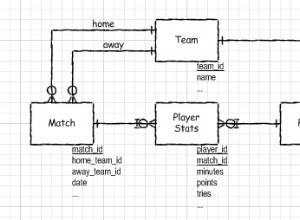
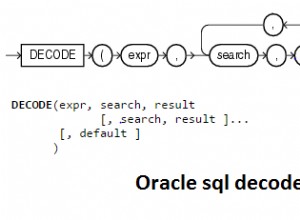
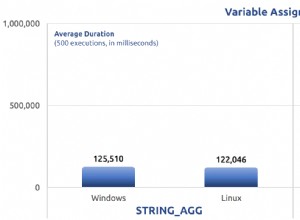
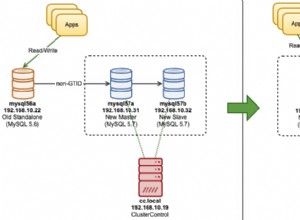
La prima cosa da tenere a mente è che MySQL usa solo un indice per psuedo-SELECT (non istruzione):quando visualizzi l'output di SELECT usando EXPLAIN, vedrai quale indice è stato scelto per. EXPLAIN può essere eseguito solo su SELECTS, quindi dobbiamo presumere che un DELETE/UPDATE utilizzi lo stesso piano quando sostituisci la sintassi con SELECT...
Per quanto ne so, la maggior parte dei database (quelli incorporati possono essere strani) supportano l'uso di indici nelle seguenti clausole:
- SELEZIONA
- UNISCI (sintassi ANSI-92)
- DOVE (perché c'è sia ANSI-89 che filtro qui)
- HAVING (WHERE equivalente, ma a differenza di WHERE - consente l'uso aggregato senza bisogno di subquery)
- ORDINA PER
Non sono al 100% su GROUP BY, quindi per il momento lo sto omettendo.
In definitiva, è la scelta degli ottimizzatori per cosa usare in base al suo algoritmo e alle statistiche che ha a portata di mano. È possibile utilizzare la sintassi ANALIZZA TABELLA per aggiornare le statistiche (periodicamente, non costantemente per favore).
Addendum
MySQL limita anche la quantità di spazio per l'allocazione degli indici - 1.000 byte per le tabelle MyISAM e 767 byte per le tabelle InnoDB . Poiché MySQL utilizza un solo indice per psuedo-SELECT, coprire gli indici (indici che includono più di una colonna) è una buona idea, ma si tratta davvero di testare la query più comune e ottimizzarla nel miglior modo possibile. La priorità di indicizzazione dovrebbe essere:
- Chiave primaria (da qualche parte nella v5, la creazione dell'indice per il pk è diventata automatica)
- Chiavi straniere (prossimamente candidato JOIN
- Criteri di filtraggio (supponendo che tu abbia lo spazio)