Ecco alcune "regole del gioco" che devi tenere a mente per risolvere questo problema. Probabilmente li conosci già, ma indicarli chiaramente può aiutare a confermare per altri lettori.
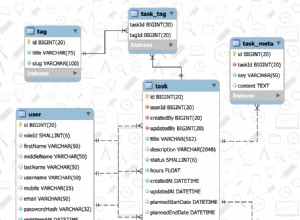
- Tutti gli indici in MySQL possono fare riferimento solo a colonne in una singola tabella di base. Non puoi creare un indice fulltext che indicizzi su più tabelle.
- Non puoi definire indici per viste, solo tabelle di base.
- Un
MATCH()la query su un indice fulltext deve corrispondere a tutte le colonne nell'indice fulltext, nell'ordine dichiarato nell'indice.
Creerei una terza tabella per memorizzare il contenuto che desideri indicizzare. Non è necessario archiviare questo contenuto in modo ridondante:archivialo esclusivamente nella terza tabella. Questo prende in prestito un concetto di "superclasse comune" dal design orientato agli oggetti (nella misura in cui possiamo applicarlo al design RDBMS).
CREATE TABLE Searchable (
`id` SERIAL PRIMARY KEY,
`title` varchar(100) default NULL,
`description` text,
`keywords` text,
`url` varchar(255) default '',
FULLTEXT KEY `TitleDescFullText` (`keywords`,`title`,`description`,`url`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE `shopitems` (
`id` INT UNSIGNED NOT NULL,
`ShopID` INT UNSIGNED NOT NULL,
`ImageID` INT UNSIGNED NOT NULL,
`pricing` varchar(45) NOT NULL,
`datetime_created` datetime NOT NULL,
PRIMARY KEY (`id`),
FOREIGN KEY (`id`) REFERENCES Searchable (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE `shops` (
`id` INT UNSIGNED NOT NULL,
`owner_id` varchar(255) default NULL,
`datetime_created` datetime default NULL,
`created_by` varchar(255) default NULL,
`datetime_modified` datetime default NULL,
`modified_by` varchar(255) default NULL,
`overall_rating_avg` decimal(4,2) default '0.00',
PRIMARY KEY (`id`),
FOREIGN KEY (`id`) REFERENCES Searchable (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
Si noti che l'unica tabella con una chiave di incremento automatico è ora Searchable . I tavoli shops e shopitems utilizzare una chiave con un tipo di dati compatibile, ma non con incremento automatico. Quindi devi creare una riga in Searchable per generare l'id valore, prima di poter creare la riga corrispondente in uno dei due shops o shopitems .
Ho aggiunto FOREIGN KEY dichiarazioni a scopo illustrativo, anche se MyISAM ignorerà silenziosamente questi vincoli (e sai già che devi utilizzare MyISAM per avere il supporto per l'indicizzazione fulltext).
Ora puoi cercare il contenuto testuale di entrambi i shops e shopitems in una singola query, utilizzando un unico indice fulltext:
SELECT S.*, sh.*, si.*,
MATCH(keywords, title, description, url) AGAINST('dummy') As score
FROM Searchable S
LEFT OUTER JOIN shops sh ON (S.id = sh.id)
LEFT OUTER JOIN shopitems si ON (S.id = si.id)
WHERE MATCH(keywords, title, description, url) AGAINST('dummy')
ORDER BY score DESC;
Naturalmente, per una determinata riga in Searchable solo una tabella deve corrispondere, negozi o articoli da negozio, e queste tabelle hanno colonne diverse. Quindi o sh.* o si.* sarà NULL nel risultato. Sta a te formattare l'output nella tua applicazione.
Un paio di altre risposte hanno suggerito di utilizzare Sphinx Search . Questa è un'altra tecnologia che integra MySQL e aggiunge capacità di ricerca full-text più sofisticate. Ha ottime prestazioni per le query, quindi alcune persone ne sono rimaste piuttosto incantate.
Ma la creazione di indici e soprattutto l'aggiunta a un indice in modo incrementale è costosa. In effetti, l'aggiornamento di un indice Sphinx Search è così costoso che la soluzione consigliata consiste nel creare un indice per i dati archiviati meno recenti e un altro indice più piccolo per i dati recenti che è più probabile che vengano aggiornati. Quindi ogni ricerca deve eseguire due query, rispetto ai due indici separati. E se i tuoi dati non si prestano naturalmente allo schema in cui i dati più vecchi non cambiano, potresti non essere comunque in grado di sfruttare questo trucco.
Re il tuo commento:ecco un estratto dalla documentazione Sphinx Search sugli aggiornamenti in tempo reale di un indice:
L'idea è che, poiché è costoso aggiornare un indice Sphinx Search, la loro soluzione è rendere l'indice aggiornato il più piccolo possibile. In modo che solo i post del forum più recenti (nel loro esempio), mentre la cronologia più ampia dei post del forum archiviati non cambi mai, quindi costruisci un secondo indice più grande per quella raccolta una volta. Ovviamente se vuoi fare una ricerca, devi interrogare entrambi gli indici.
Periodicamente, diciamo una volta alla settimana, i messaggi "recenti" del forum verrebbero considerati "archiviati" e dovresti unire l'indice corrente per i post recenti all'indice archiviato e ricominciare dall'indice più piccolo. Sottolineano che l'unione di due indici Sphinx Search è più efficiente della reindicizzazione dopo un aggiornamento dei dati.
Ma il mio punto è che non tutti i set di dati rientrano naturalmente nello schema di avere un set di dati archiviato che non cambia mai, rispetto ai dati recenti che si aggiornano frequentemente.
Prendi il tuo database per esempio:hai negozi e articoli da negozio. Come puoi separarli in righe che non cambiano mai, rispetto a nuove righe? Qualsiasi negozio o prodotto nel catalogo dovrebbe essere autorizzato ad aggiornare la propria descrizione. Ma poiché ciò richiederebbe la ricostruzione dell'intero indice Sphinx Search ogni volta che apporti una modifica, diventa un'operazione molto costosa. Forse metteresti in coda le modifiche e le applicheresti in batch, ricostruendo l'indice una volta alla settimana. Ma prova a spiegare ai venditori del negozio perché una piccola modifica alla descrizione del negozio non avrà effetto prima di domenica sera.