Volevo entrare con l'opzione di risolvere il tuo compito con BigQuery puro (SQL standard)
Prerequisiti / ipotesi :i dati di origine sono in sandbox.temp.id1_id2_pairs
Dovresti sostituirlo con il tuo o se vuoi testare con dati fittizi dalla tua domanda - puoi creare questa tabella come di seguito (ovviamente sostituisci sandbox.temp con il tuo project.dataset )
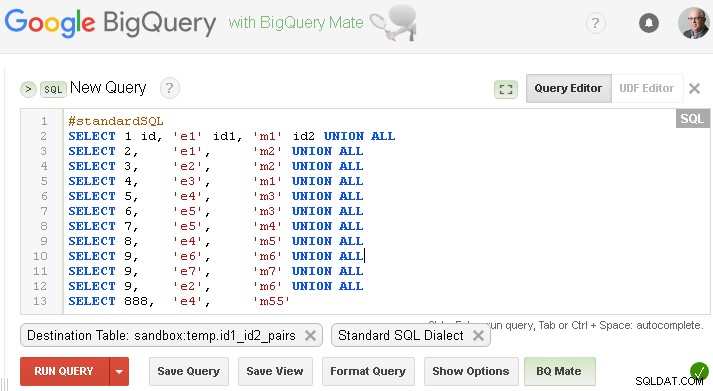
Assicurati di impostare la rispettiva tabella di destinazione
Nota :puoi trovare tutte le rispettive query (come testo) in fondo a questa risposta, ma per ora sto illustrando la mia risposta con schermate - quindi tutto è presentato - query, risultato e opzioni utilizzate
Quindi, ci saranno tre passaggi:
Passaggio 1:Inizializzazione
Qui, eseguiamo solo il raggruppamento iniziale di id1 in base alle connessioni con id2:
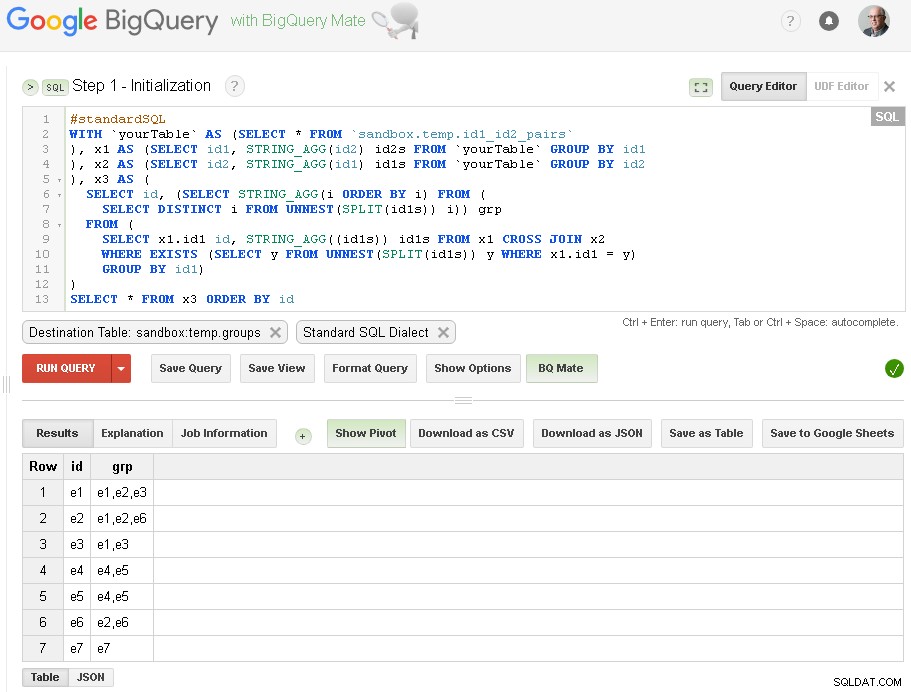
Come puoi vedere qui, abbiamo creato un elenco di tutti i valori id1 con le rispettive connessioni basate su una semplice connessione a un livello tramite id2
La tabella di output è sandbox.temp.groups
Passaggio 2:Raggruppamento delle iterazioni
In ogni iterazione arricchiremo il raggruppamento in base a gruppi già stabiliti.
La fonte della query è la tabella di output del passaggio precedente (sandbox.temp.groups ) e Destinazione è la stessa tabella (sandbox.temp.groups ) con Sovrascrivi
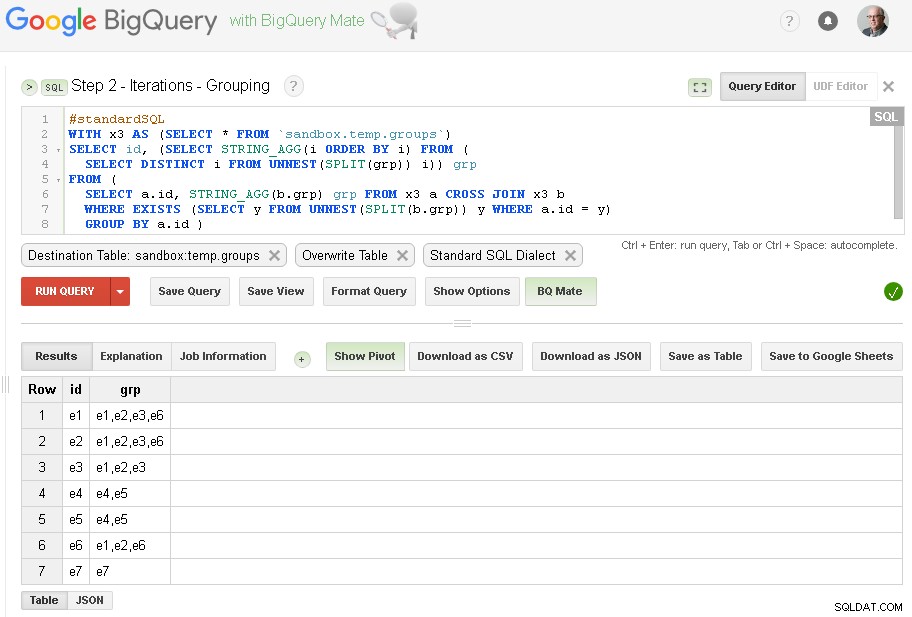
Continueremo le iterazioni fino a quando il conteggio dei gruppi trovati sarà lo stesso dell'iterazione precedente
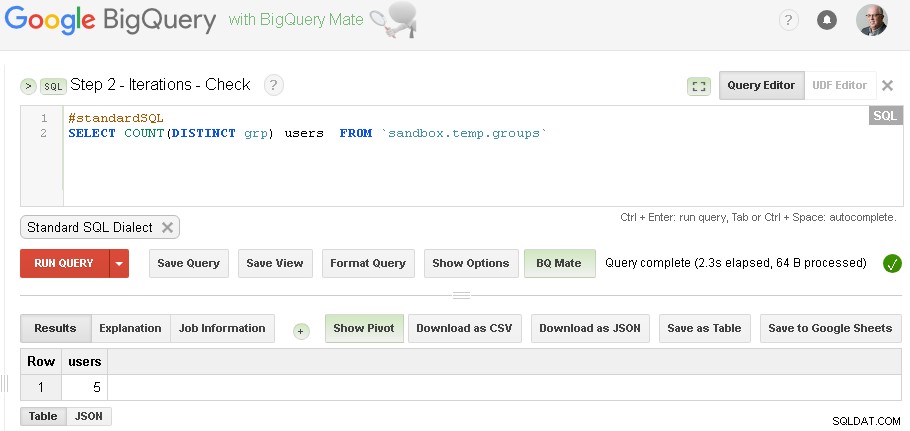
Nota :puoi semplicemente avere due schede dell'interfaccia utente Web BigQuery aperte (come mostrato sopra) e senza modificare alcun codice esegui semplicemente Raggruppamento e quindi Controlla ancora e ancora fino a quando l'iterazione converge
(per i dati specifici che ho usato nella sezione dei prerequisiti - avevo tre iterazioni - la prima iterazione ha prodotto 5 utenti, la seconda iterazione ha prodotto 3 utenti e la terza iterazione ha prodotto di nuovo 3 utenti - il che indicava che abbiamo terminato con le iterazioni.
Ovviamente, nel caso della vita reale - il numero di iterazioni potrebbe essere più di tre - quindi abbiamo bisogno di una sorta di automazione (vedi la rispettiva sezione in fondo alla risposta).
Passaggio 3:Raggruppamento finale
Quando il raggruppamento id1 è completato, possiamo aggiungere il raggruppamento finale per id2
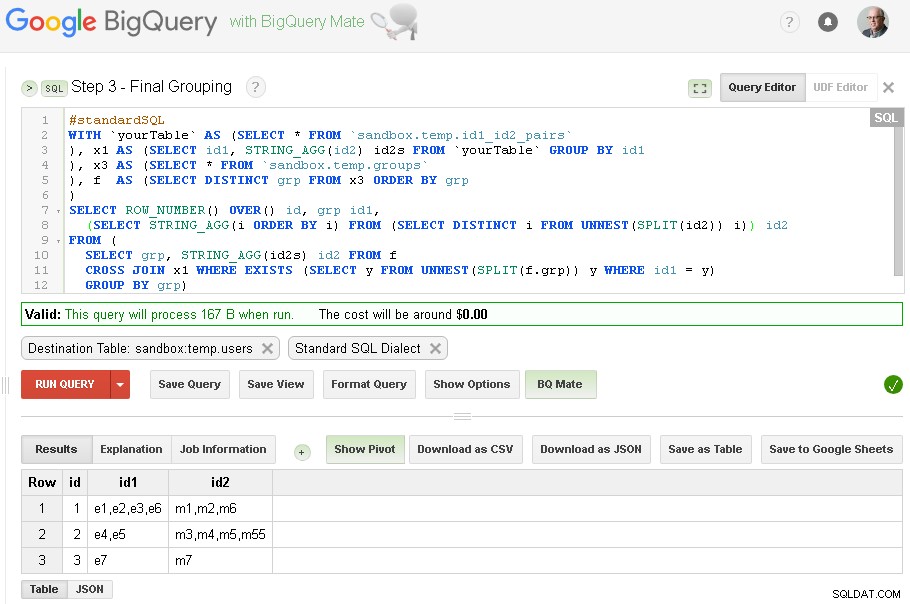
Il risultato finale ora è in sandbox.temp.users tabella
Query utilizzate (non dimenticare di impostare le rispettive tabelle di destinazione e sovrascrivere quando necessario secondo la logica e gli screenshot sopra descritti):
Prerequisiti:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Passaggio 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Passaggio 2:raggruppamento
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Passaggio 2:verifica
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Passaggio 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automazione :
Ovviamente, sopra "processo" può essere eseguito manualmente nel caso in cui le iterazioni convergano velocemente, quindi ti ritroverai con 10-20 esecuzioni. Ma in casi più reali puoi automatizzarlo facilmente con qualsiasi client
a tua scelta