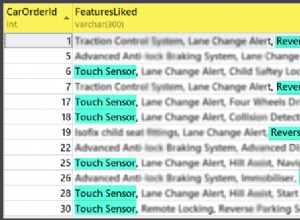
Non è del tutto chiaro cosa stai chiedendo. Il blocco garantisce che un solo utente tenti di modificare una determinata riga in un dato momento. Il blocco a livello di riga significa che solo la riga che stanno modificando è bloccata. Le solite alternative sono o bloccare l'intera tabella per la durata della modifica, oppure bloccare alcuni sottoinsiemi della tabella. Il blocco a livello di riga riduce semplicemente quel sottoinsieme di righe al numero più piccolo che garantisce comunque l'integrità.
L'idea è di consentire a un utente di modificare una cosa senza impedire ad altri utenti di modificare altre cose. Vale la pena notare, tuttavia, che in alcuni casi questo può essere una sorta di falso positivo, per così dire. Alcuni database supportano il blocco a livello di riga, ma rendono un blocco a livello di riga notevolmente più costoso del blocco di una parte più ampia della tabella, abbastanza più costoso da poter essere controproducente.
Modifica:la tua modifica al post originale aiuta, ma non molto. Prima di tutto, le dimensioni delle righe e i livelli di hardware coinvolti hanno un effetto enorme (l'inserimento di una riga da 8 byte su una dozzina di dischi rigidi SAS con striping da 15.000 unità è solo un po' più veloce dell'inserimento di una riga da un megabyte su un singolo disco rigido di classe consumer ).
In secondo luogo, si tratta in gran parte del numero di utenti simultanei, quindi il modello di inserimento fa una grande differenza. 1000 righe inserite alle 3 del mattino probabilmente non verranno notate affatto. 1000 righe inserite in modo uniforme nell'arco della giornata significano un po' di più (ma probabilmente solo un po'). 1000 righe inserite come batch proprio quando altri 100 utenti hanno bisogno di dati immediatamente potrebbero far licenziare qualcuno (soprattutto se uno di quei 100 è il proprietario dell'azienda).