Screenshot #1 mostra alcuni punti per distinguere tra Merge Join transformation e Lookup transformation .
Riguardo alla ricerca:
Se vuoi trovare le righe corrispondenti nella fonte 2 in base all'input della fonte 1 e se sai che ci sarà solo una corrispondenza per ogni riga di input, ti suggerirei di usare l'operazione di ricerca. Un esempio potresti essere tu OrderDetails tabella e si desidera trovare l'Order Id corrispondente e Customer Number , quindi Cerca è un'opzione migliore.
Per quanto riguarda l'unione di unisci:
Se desideri eseguire unioni come recuperare tutti gli indirizzi (casa, lavoro, altro) da Address tabella per un determinato Cliente nel Customer tabella, quindi devi andare con Unisci unisciti perché il cliente può avere 1 o più indirizzi associati.
Un esempio da confrontare:
Ecco uno scenario per dimostrare le differenze di prestazioni tra Merge Join e Lookup . I dati utilizzati qui sono un join uno a uno, che è l'unico scenario comune tra loro da confrontare.
-
Ho tre tabelle denominate
dbo.ItemPriceInfo,dbo.ItemDiscountInfoedbo.ItemAmount. Gli script di creazione per queste tabelle sono forniti nella sezione degli script SQL. -
Tabelle
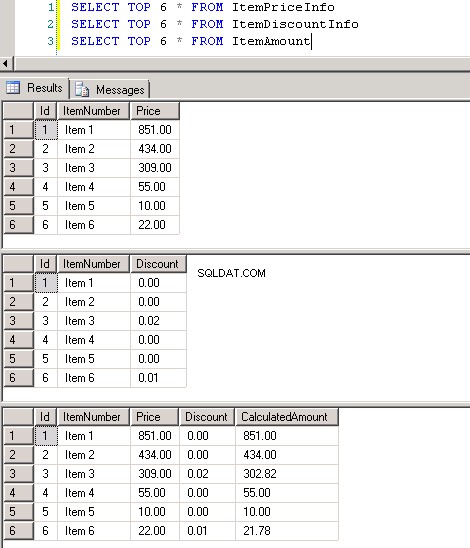
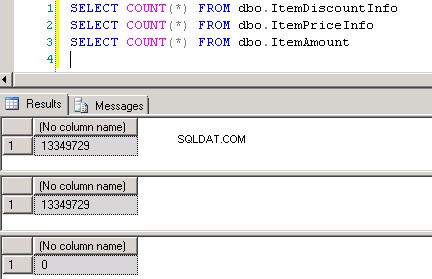
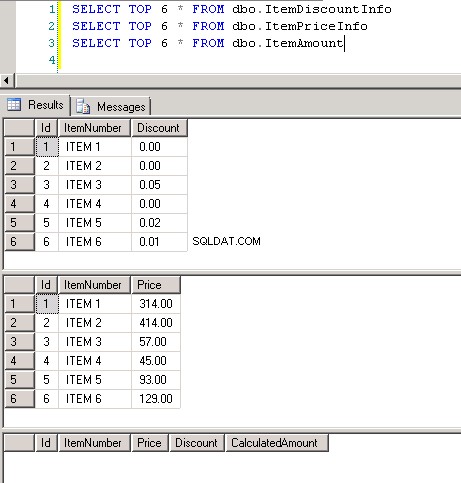
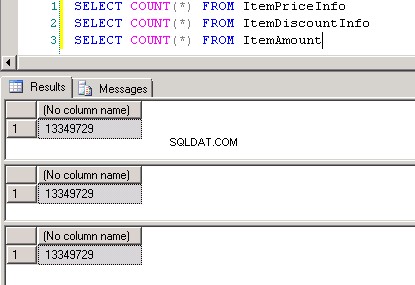
dbo.ItemPriceInfoedbo.ItemDiscountInfoentrambi hanno 13.349.729 righe. Entrambe le tabelle hanno ItemNumber come colonna comune. ItemPriceInfo ha informazioni sul prezzo e ItemDiscountInfo ha informazioni sugli sconti. Screenshot #2 mostra il conteggio delle righe in ciascuna di queste tabelle. Screenshot n. 3 mostra le prime 6 righe per dare un'idea dei dati presenti nelle tabelle. -
Ho creato due pacchetti SSIS per confrontare le prestazioni delle trasformazioni Merge Join e Lookup. Entrambi i pacchetti devono prendere le informazioni dalle tabelle
dbo.ItemPriceInfoedbo.ItemDiscountInfo, calcola l'importo totale e salvalo nella tabelladbo.ItemAmount. -
Primo pacchetto utilizzato
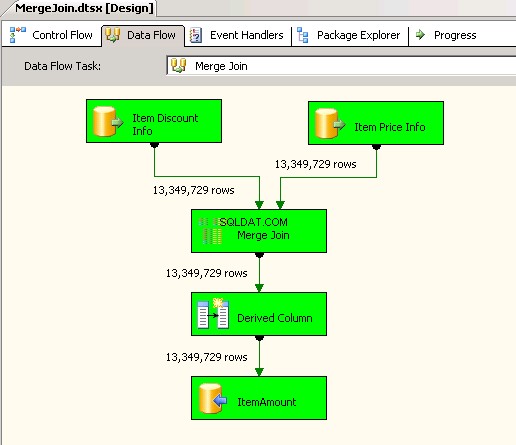
Merge Jointrasformazione e al suo interno ha utilizzato INNER JOIN per combinare i dati. Screenshot #4 e #5 mostra l'esecuzione del pacchetto di esempio e la durata dell'esecuzione. Ci sono voluti05minuti14secondi719millisecondi per eseguire il pacchetto basato sulla trasformazione Merge Join. -
Secondo pacchetto utilizzato
Lookuptrasformazione con cache completa (che è l'impostazione predefinita). creenshots #6 e #7 mostra l'esecuzione del pacchetto di esempio e la durata dell'esecuzione. Ci sono voluti11minuti03secondi610millisecondi per eseguire il pacchetto basato sulla trasformazione Lookup. È possibile che venga visualizzato il messaggio di avviso Informazioni:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Ecco un link che parla di come calcolare la dimensione della cache di ricerca. Durante l'esecuzione di questo pacchetto, anche se l'attività Flusso di dati è stata completata più rapidamente, la pulizia della pipeline ha richiesto molto tempo. -
Questo non significa che la trasformazione di ricerca è negativa. È solo che deve essere usato con saggezza. Lo uso abbastanza spesso nei miei progetti, ma ancora una volta non mi occupo di oltre 10 milioni di righe per la ricerca ogni giorno. Di solito, i miei lavori gestiscono tra 2 e 3 milioni di righe e per questo le prestazioni sono davvero buone. Fino a 10 milioni di righe, entrambe si sono comportate ugualmente bene. Il più delle volte quello che ho notato è che il collo di bottiglia risulta essere la componente di destinazione piuttosto che le trasformazioni. Puoi superarlo avendo più destinazioni. Qui è un esempio che mostra l'implementazione di più destinazioni.
-
Screenshot #8 mostra il conteggio dei record in tutte e tre le tabelle. Screenshot #9 mostra i primi 6 record in ciascuna delle tabelle.
Spero di esserti stato d'aiuto.
Script SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Schermata n. 1:

Schermata n. 2:
Schermata n. 3:
Schermata n. 4:
Schermata n. 5:

Schermata n. 6:
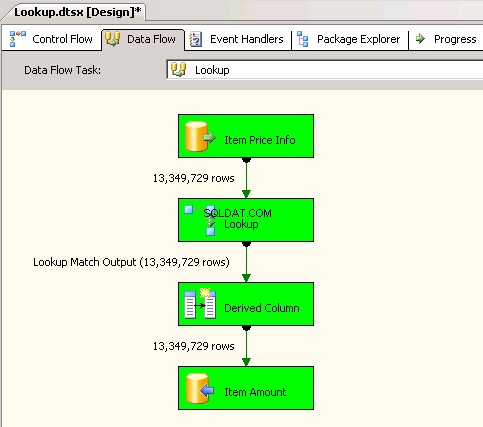
Schermata n. 7:
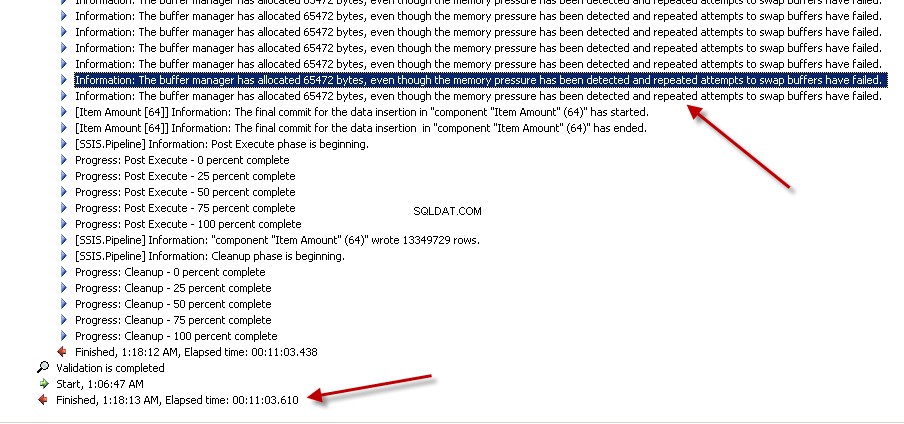
Schermata n. 8:
Schermata n. 9: