Prima di tutto "toxi" non è un termine standard. Definisci sempre i tuoi termini! O almeno fornisci link pertinenti.
E ora alla domanda stessa...
No, avrai 3 tavoli.
Sei praticamente sulla strada giusta, con l'eccezione che puoi utilizzare la natura basata su set di SQL per "unire" molti di questi passaggi. Ad esempio, contrassegnare un elemento 1 con i tag:'tag1', 'tag2' e 'tag3' può essere fatto in questo modo...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
Il IGNORE consente che ciò avvenga anche se l'elemento è già collegato ad alcuni di questi tag.
Ciò presuppone che tutti i tag richiesti siano già in tags . Assumendo tag.tag_id è auto-incremento, puoi fare qualcosa del genere per assicurarti che siano:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Non c'è magia. Se "l'elemento è collegato a un tag particolare" è un'informazione che vuoi registrare, allora avrà avere una sorta di rappresentazione fisica nel database.
Intendi rietichettare gli elementi (non modificare i tag stessi)?
Per rimuovere tutti i tag che non sono nell'elenco, fai qualcosa del genere:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Questo disconnetterà l'elemento da tutti i tag tranne 'tag1' e 'tag3'. Esegui INSERT sopra e questo DELETE uno dopo l'altro per "coprire" sia l'aggiunta che la rimozione di tag.
Puoi giocare con tutto questo in SQL Fiddle .
Corretta. Un endpoint figlio di un FK non attiverà un'azione referenziale (come ON DELETE CASCADE), solo il genitore lo farà.
A proposito, stai utilizzando questo schema perché desideri campi aggiuntivi in tags (accanto a tag_text ), giusto? Se lo fai, non perdere questi dati aggiuntivi solo perché tutte le connessioni sono scomparse è il comportamento desiderato.
Ma se volessi solo il tag_text , utilizzeresti uno schema più semplice in cui eliminare tutte le connessioni sarebbe come eliminare il tag stesso:
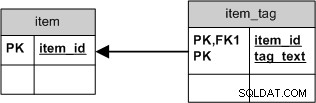
Ciò non solo semplificherebbe l'SQL, ma fornirebbe anche un migliore clustering .
A prima vista, "toxi" potrebbe sembrare un risparmio di spazio, ma in pratica potrebbe non essere così, poiché richiede tabelle e indici aggiuntivi (e i tag tendono ad essere brevi).
Misura prima di decidere di fare qualcosa del genere. Il mio SQL Fiddle menzionato sopra utilizza un ordine di campi molto deliberato nella tagmap PK, quindi i dati sono raggruppati in un modo molto amichevole per questo tipo di conteggio (ricorda:Le tabelle InnoDB sono raggruppate
). Dovresti avere una quantità davvero enorme di articoli (o richiedere prestazioni insolitamente elevate) prima che questo diventi un problema.
In ogni caso, misura su quantità realistiche di dati!