Non c'è differenza tra queste due affermazioni e l'ottimizzatore trasformerà il IN al = quando IN contiene solo un elemento.
Tuttavia, quando hai una domanda come questa, esegui entrambe le istruzioni, esegui il loro piano di esecuzione e osserva le differenze. Qui - non ne troverai nessuno.
Dopo una lunga ricerca online, ho trovato un documento su SQL per supportare questo (presumo che si applichi a tutti i DBMS):
Ecco il piano di esecuzione di entrambe le query in Oracle (la maggior parte dei DBMS lo elaborerà allo stesso modo):
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number = '123456789'
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
E per IN() :
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number in('123456789');
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
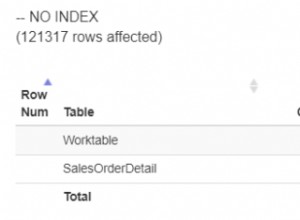
Come puoi vedere, entrambi sono identici. Questo è su una colonna indicizzata. Lo stesso vale per una colonna non indicizzata (solo una scansione completa della tabella).