Ho messo insieme un esempio di trasformazione (fare clic con il pulsante destro del mouse e scegliere il collegamento di salvataggio) in base a ciò che hai fornito. L'unico passaggio su cui mi sento un po' incerto sono gli ultimi input della tabella. In pratica sto scrivendo i dati di join sulla tabella e lasciando che fallisca se esiste già una relazione specifica.
nota:
Questa soluzione in realtà non soddisfa i requisiti "Tutti gli approcci dovrebbero includere parte della convalida e una strategia di rollback in caso di errore di inserimento o di mancato mantenimento dell'integrità referenziale". criteri, anche se probabilmente non fallirà. Se vuoi davvero impostare qualcosa di complesso, possiamo, ma questo dovrebbe sicuramente farti andare avanti con queste trasformazioni.

Flusso di dati per passo
1. Iniziamo con la lettura nel tuo file. Nel mio caso l'ho convertito in CSV ma anche la scheda va bene. 
2. Ora inseriremo i nomi dei dipendenti nella tabella Dipendenti utilizzando una combination lookup/update .Dopo l'inserimento, aggiungiamo employee_id al nostro flusso di dati come id e rimuovi EmployeeName dal flusso di dati.

3. Qui stiamo solo usando un passaggio Seleziona valori per rinominare l'id campo a employee_id 
4. Inserisci i titoli di lavoro proprio come abbiamo fatto noi dipendenti e aggiungi l'id del titolo al nostro flusso di dati eliminando anche il JobLevelHistory dal flusso di dati.

5. Rinomina semplice dell'id del titolo in title_id (vedi passaggio 3) 
6. Inserisci uffici, ottieni ID, rimuovi OfficeHistory dallo stream.

7. Rinominare semplicemente l'id dell'ufficio in office_id (vedi passaggio 3)

8. Copia i dati dall'ultimo passaggio in due flussi con i valori employee_id,office_id e employee_id,title_id rispettivamente.

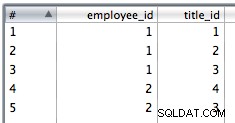
9. Utilizzare un inserto tabella per inserire i dati di unione. L'ho selezionato per ignorare gli errori di inserimento poiché potrebbero esserci dei duplicati e i vincoli PK faranno fallire alcune righe.
Tabelle di output