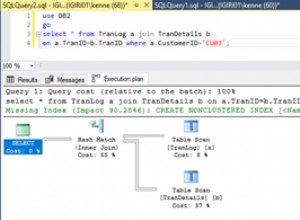
Questo riguarda la lunghezza della clausola IN - e quello che a volte viene chiamato BUG in MySQL.
MySQL sembra avere una soglia bassa per le clausole IN, quando passerà a una SCANSIONE TABLE/INDEX invece di raccogliere più partizioni (una per elemento IN) e unirle.
Con un INNER JOIN, è quasi sempre costretto a utilizzare un diretto riga per riga nella raccolta JOIN, motivo per cui a volte è più veloce
Fare riferimento a queste pagine di manuale di MySQL
Potrei sbagliarmi poiché sembra implicare che IN (constant value list) dovrebbe sempre usare una ricerca binaria su ogni elemento...