Tutti voi avete sentito parlare di scalabilità:la vostra architettura dovrebbe essere scalabile, dovreste essere in grado di scalare per soddisfare la domanda, e così via. Cosa significa quando si parla di database? Come appare il ridimensionamento dietro le quinte? Questo argomento è vasto e non c'è modo di coprire tutti gli aspetti. Questa serie di post di due blog è un tentativo di darti un'idea dell'argomento della scalabilità del database.
Perché ridimensioniamo?
Per prima cosa, diamo un'occhiata a cosa si intende per scalabilità. In breve, stiamo parlando della capacità di gestire un carico maggiore da parte dei sistemi di database. Può trattarsi di affrontare picchi di breve durata nell'attività, può trattarsi di gestire un carico di lavoro gradualmente aumentato nell'ambiente di database. Ci possono essere numerosi motivi per considerare il ridimensionamento. La maggior parte di loro viene con le proprie sfide. Possiamo dedicare un po' di tempo a esaminare esempi della situazione in cui potremmo voler aumentare la scalabilità.
Aumento del consumo di risorse
Questo è il più generico:il tuo carico è aumentato al punto in cui le tue risorse esistenti non sono più in grado di gestirlo. Può essere qualsiasi cosa. Il carico della CPU è aumentato e il cluster di database non è più in grado di fornire dati con tempi di esecuzione delle query ragionevoli e stabili. L'utilizzo della memoria è cresciuto a tal punto che il database non è più vincolato alla CPU ma è diventato legato all'I/O e, di conseguenza, le prestazioni dei nodi del database sono state notevolmente ridotte. La rete può anche essere un collo di bottiglia. Potresti essere sorpreso di vedere quali limiti relativi alla rete sono assegnati alle tue istanze cloud. In effetti, questo potrebbe diventare il limite più comune che devi affrontare poiché la rete è tutto nel cloud:non solo i dati inviati tra l'applicazione e il database, ma anche lo spazio di archiviazione è collegato alla rete. Può anche essere l'utilizzo del disco:stai esaurendo lo spazio su disco o, più probabilmente, dato che al giorno d'oggi possiamo avere dischi piuttosto grandi, la dimensione del database ha superato la dimensione "gestibile". La manutenzione come la modifica dello schema diventa una sfida, le prestazioni si riducono a causa delle dimensioni dei dati, i backup richiedono anni per essere completati. Tutti questi casi possono essere validi per la necessità di una scalabilità verticale.
Improvviso aumento del carico di lavoro
Un altro caso di esempio in cui è necessario il ridimensionamento è un improvviso aumento del carico di lavoro. Per qualche motivo (che si tratti di attività di marketing, contenuto virale, emergenza o situazioni simili) la tua infrastruttura subisce un aumento significativo del carico sul cluster di database. Il carico della CPU supera il tetto, l'I/O del disco sta rallentando le query, ecc. Praticamente tutte le risorse menzionate nella sezione precedente possono essere sovraccaricate e iniziare a causare problemi.
Operazione pianificata
Il terzo motivo che vorremmo evidenziare è quello più generico:una sorta di operazione pianificata. Può essere un'attività di marketing pianificata che prevedi porti più traffico, Black Friday, test di carico o praticamente qualsiasi cosa tu sappia in anticipo.
Ognuno di questi motivi ha le sue caratteristiche. Se puoi pianificare in anticipo, puoi preparare il processo in dettaglio, testarlo ed eseguirlo ogni volta che ne hai voglia. Molto probabilmente ti piacerà farlo in un periodo di "basso traffico", purché qualcosa del genere esista nei tuoi carichi di lavoro (non deve esistere). D'altra parte, picchi improvvisi nel carico, soprattutto se sono abbastanza significativi da avere un impatto sulla produzione, forzeranno una reazione immediata, non importa quanto tu sia preparato e quanto sia sicuro:se i tuoi servizi sono già interessati, puoi anche semplicemente provaci invece di aspettare.
Tipi di ridimensionamento del database
Ci sono due tipi principali di ridimensionamento:verticale e orizzontale. Entrambi hanno pro e contro, entrambi sono utili in diverse situazioni. Diamo un'occhiata a loro e discutiamo dei casi d'uso per entrambi gli scenari.
Ridimensionamento verticale
Questo metodo di ridimensionamento è probabilmente il più vecchio:se il tuo hardware non è abbastanza robusto per gestire il carico di lavoro, potenzialo. Stiamo parlando semplicemente di aggiungere risorse ai nodi esistenti con l'intento di renderli sufficientemente capaci per affrontare i compiti assegnati. Questo ha alcune ripercussioni che vorremmo esaminare.
Vantaggi del ridimensionamento verticale
La cosa più importante è che tutto rimanga lo stesso. Avevi tre nodi in un cluster di database, hai ancora tre nodi, solo più capaci. Non è necessario riprogettare l'ambiente, modificare il modo in cui l'applicazione deve accedere al database:tutto rimane esattamente lo stesso perché, dal punto di vista della configurazione, nulla è realmente cambiato.
Un altro vantaggio significativo del ridimensionamento verticale è che può essere molto veloce, specialmente negli ambienti cloud. L'intero processo consiste, più o meno, nell'arrestare il nodo esistente, apportare le modifiche all'hardware, riavviare il nodo. Per le configurazioni classiche in loco, senza alcuna virtualizzazione, questo potrebbe essere complicato:potresti non avere CPU più veloci disponibili per lo scambio, anche l'aggiornamento di dischi a dischi più grandi o più veloci potrebbe richiedere molto tempo, ma per gli ambienti cloud, pubblici o privati, questo può essere facile come eseguire tre comandi:ferma istanza, aggiorna istanza a dimensioni maggiori, avvia istanza. Gli IP virtuali e i volumi ricollegabili semplificano lo spostamento dei dati tra le istanze.
Svantaggi del ridimensionamento verticale
Il principale svantaggio del ridimensionamento verticale è che, semplicemente, ha i suoi limiti. Se stai utilizzando la dimensione dell'istanza più grande disponibile, con i volumi del disco più veloci, non c'è molto altro che puoi fare. Inoltre, non è così facile aumentare significativamente le prestazioni del tuo cluster di database. Dipende principalmente dalla dimensione dell'istanza iniziale, ma se stai già eseguendo nodi abbastanza performanti, potresti non essere in grado di ottenere uno scale-out 10x usando il ridimensionamento verticale. I nodi che sarebbero 10 volte più veloci potrebbero semplicemente non esistere.
Ridimensionamento orizzontale
Il ridimensionamento orizzontale è una bestia diversa. Invece di aumentare con la dimensione dell'istanza, rimaniamo allo stesso livello ma ci espandiamo orizzontalmente aggiungendo più nodi. Anche in questo caso, ci sono pro e contro di questo metodo.
Pro del ridimensionamento orizzontale
Il vantaggio principale del ridimensionamento orizzontale è che, in teoria, il limite è il cielo. Non esiste un limite rigido artificiale di scale-out, anche se esistono limiti, principalmente a causa del sovraccarico delle comunicazioni all'interno del cluster sempre più grande con ogni nuovo nodo aggiunto al cluster.
Un altro vantaggio significativo sarebbe la possibilità di aumentare la scalabilità del cluster senza la necessità di tempi di inattività. Se desideri aggiornare l'hardware, devi arrestare l'istanza, aggiornarla e quindi ricominciare. Se desideri aggiungere più nodi al cluster, tutto ciò che devi fare è eseguire il provisioning di quei nodi, installare il software di cui hai bisogno, incluso il database, e lasciarlo entrare nel cluster. Facoltativamente (a seconda che il cluster disponga di metodi interni per eseguire il provisioning di nuovi nodi con i dati) potrebbe essere necessario eseguire il provisioning dei dati autonomamente. In genere, tuttavia, è un processo automatizzato.
Contro del ridimensionamento orizzontale
Il problema principale che devi affrontare è che l'aggiunta di sempre più nodi rende difficile la gestione dell'intero ambiente. Devi essere in grado di dire quali nodi sono disponibili, tale elenco deve essere mantenuto e aggiornato con ogni nuovo nodo creato. Potresti aver bisogno di soluzioni esterne come il servizio di directory (Consul o Etcd) per tenere traccia dei nodi e del loro stato. Questo, ovviamente, aumenta la complessità dell'intero ambiente.
Un altro potenziale problema è che il processo di scale-out richiede tempo. L'aggiunta di nuovi nodi e il loro provisioning con software e, soprattutto, dati richiede tempo. Quanto dipende dall'hardware (principalmente I/O e throughput di rete) e dalla dimensione dei dati. Per configurazioni di grandi dimensioni questo potrebbe essere un periodo di tempo significativo e questo potrebbe essere un ostacolo per le situazioni in cui lo scale-up deve avvenire immediatamente. Le ore di attesa per l'aggiunta di nuovi nodi potrebbero non essere accettabili se il cluster di database è interessato al punto che le operazioni non vengono eseguite correttamente.
Prerequisiti per il ridimensionamento
Replica dei dati
Prima di eseguire qualsiasi tentativo di ridimensionamento, l'ambiente deve soddisfare un paio di requisiti. Per cominciare, la tua applicazione deve essere in grado di sfruttare più di un nodo. Se può utilizzare un solo nodo, le tue opzioni sono praticamente limitate al ridimensionamento verticale. Puoi aumentare le dimensioni di tale nodo o aggiungere alcune risorse hardware al server bare metal e renderlo più performante ma è il meglio che puoi fare:sarai sempre limitato dalla disponibilità di hardware più performante e, alla fine, troverai te stesso senza un'opzione per aumentare ulteriormente.
D'altra parte, se hai i mezzi per utilizzare più nodi di database dalla tua applicazione, puoi trarre vantaggio dal ridimensionamento orizzontale. Fermiamoci qui e discutiamo di cosa hai bisogno per utilizzare effettivamente più nodi al massimo delle loro potenzialità.
Per cominciare, la possibilità di dividere le letture dalle scritture. Tradizionalmente l'applicazione si connette a un solo nodo. Quel nodo viene utilizzato per gestire tutte le scritture e tutte le letture eseguite dall'applicazione.

L'aggiunta di un secondo nodo al cluster, dal punto di vista del ridimensionamento, non cambia nulla . Devi tenere presente che, se un nodo si guasta, l'altro dovrà gestire il traffico, quindi in nessun momento la somma del carico su entrambi i nodi dovrebbe essere troppo alta per essere gestita da un singolo nodo.

Con tre nodi disponibili puoi utilizzare completamente due nodi. Questo ci consente di ridurre parte del traffico di lettura:se un nodo ha una capacità del 100% (e preferiremmo eseguire al massimo al 70%), due nodi rappresentano il 200%. Tre nodi:300%. Se un nodo è inattivo e se spingeremo i nodi rimanenti quasi al limite, possiamo dire che siamo in grado di lavorare con il 170 - 180% della capacità di un singolo nodo se il cluster è degradato. Questo ci dà un bel carico del 60% su ogni nodo se tutti e tre i nodi sono disponibili.
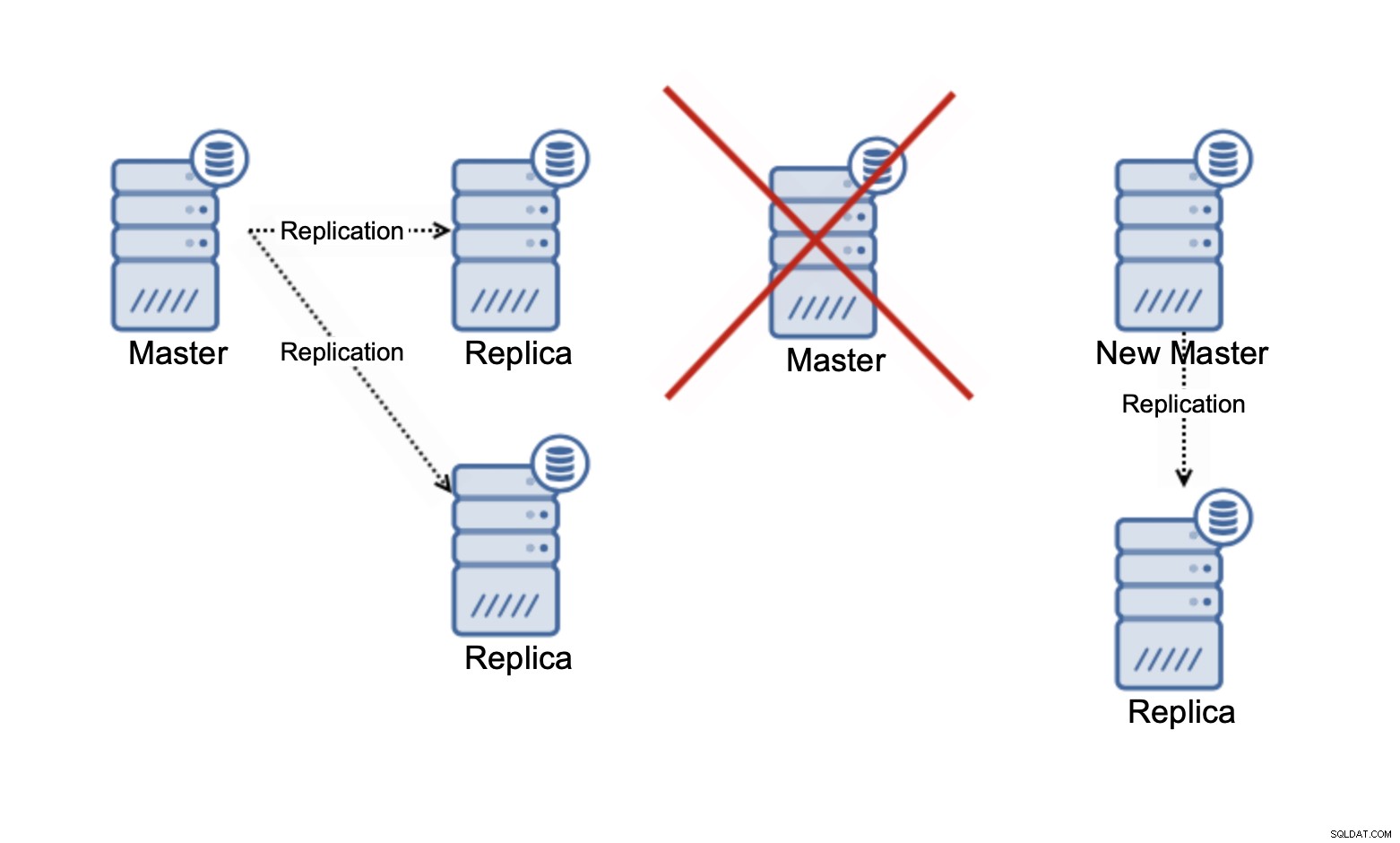
Tieni presente che al momento stiamo parlando solo di ridimensionamento delle letture . In nessun momento la replica può migliorare la tua capacità di scrittura. Nella replica asincrona, hai solo un writer (master) e per la replica sincrona, come Galera, in cui il set di dati è condiviso su tutti i nodi, ogni scrittura che sta avvenendo su un nodo dovrà essere eseguita sui nodi rimanenti del grappolo.
In un cluster Galera a tre nodi, se scrivi una riga, scrivi infatti tre righe, una per ogni nodo. L'aggiunta di più nodi o repliche non farà differenza. Invece di scrivere la stessa riga su tre nodi, la scriverai su cinque. Questo è il motivo per cui suddividere le tue scritture in un cluster multi-master, in cui il set di dati è condiviso su tutti i nodi (ci sono cluster multi-master in cui i dati sono frammentati, ad esempio MySQL NDB Cluster - qui la storia della scalabilità in scrittura è completamente diversa), non ha molto senso. Aggiunge un sovraccarico per la gestione di potenziali conflitti di scrittura su tutti i nodi, mentre in realtà non cambia nulla per quanto riguarda la capacità di scrittura totale.
Bilanciamento del carico e suddivisione in lettura/scrittura
La possibilità di dividere le letture dalle scritture è un must se si desidera ridimensionare le letture in configurazioni di replica asincrona. Devi essere in grado di inviare il traffico di scrittura a un nodo e quindi inviare le letture a tutti i nodi nella topologia di replica. Come accennato in precedenza, questa funzionalità è anche abbastanza utile nei cluster multi-master in quanto ci consente di rimuovere i conflitti di scrittura che possono verificarsi se si tenta di distribuire le scritture su più nodi del cluster. Come possiamo eseguire la divisione lettura/scrittura? Ci sono diversi metodi che puoi usare per farlo. Approfondiamo un po' questo argomento.
Dividi R/W a livello di applicazione
Lo scenario più semplice, anche il meno frequente:la tua applicazione è in grado di configurare quali nodi dovrebbero ricevere scritture e quali nodi dovrebbero ricevere letture. Questa funzionalità può essere configurata in un paio di modi, il più semplice è l'elenco hardcoded dei nodi, ma potrebbe anche essere qualcosa sulla falsariga dell'inventario dinamico dei nodi aggiornato dai thread in background. Il problema principale con questo approccio è che l'intera logica deve essere scritta come parte dell'applicazione. Con un elenco di nodi hardcoded, lo scenario più semplice richiederebbe modifiche al codice dell'applicazione per ogni modifica nella topologia di replica. D'altra parte, soluzioni più avanzate come l'implementazione di un rilevamento dei servizi sarebbero più complesse da mantenere a lungo termine.
R/W connettore diviso in
Un'altra opzione sarebbe quella di utilizzare un connettore per eseguire una divisione di lettura/scrittura. Non tutti hanno questa opzione, ma alcuni sì. Un esempio potrebbe essere php-mysqlnd o Connector/J. Il modo in cui è integrato nell'applicazione, può differire in base al connettore stesso. In alcuni casi la configurazione deve essere eseguita nell'applicazione, in alcuni casi deve essere eseguita in un file di configurazione separato per il connettore. Il vantaggio di questo approccio è che anche se devi estendere la tua applicazione, la maggior parte del nuovo codice è pronto per l'uso e gestito da fonti esterne. Semplifica la gestione di tale configurazione e devi scrivere meno codice (se presente).
R/W suddiviso in loadbalancer
Infine, una delle migliori soluzioni:i loadbalancer. L'idea è semplice:passare i dati attraverso un loadbalancer che sarà in grado di distinguere tra letture e scritture e inviarli in una posizione corretta. Questo è un grande miglioramento dal punto di vista dell'usabilità poiché possiamo separare il rilevamento del database e l'instradamento delle query dall'applicazione. L'unica cosa che l'applicazione deve fare è inviare il traffico del database a un singolo endpoint che consiste in un nome host e una porta. Il resto avviene in background. I loadbalancer stanno lavorando per instradare le query ai nodi di un database back-end. I loadbalancer possono anche eseguire il rilevamento della topologia di replica oppure puoi implementare un inventario di servizi adeguato utilizzando etcd o console e aggiornarlo tramite strumenti di orchestrazione dell'infrastruttura come Ansible.
Questo conclude la prima parte di questo blog. Nella seconda discuteremo le sfide che dobbiamo affrontare quando si ridimensiona il livello del database. Discuteremo anche alcuni modi in cui possiamo aumentare la scalabilità orizzontale dei nostri cluster di database.