I sistemi di bilanciamento del carico sono un componente essenziale di qualsiasi configurazione di database ad alta disponibilità. Vengono utilizzati per aumentare la capacità e l'affidabilità dei sistemi e delle applicazioni critici, impedendo il sovraccarico di qualsiasi server. Ne parliamo molto sul blog di Diversinines, ad esempio perché ne hai bisogno e come funzionano. Uno dei più popolari bilanciatori di carico disponibili per MySQL e MariaDB è HAProxy.
Per quanto riguarda le funzionalità, HAProxy non è paragonabile a ProxySQL o MaxScale. Tuttavia, HAProxy è un sistema di bilanciamento del carico veloce e robusto che funzionerà perfettamente in qualsiasi ambiente purché l'applicazione sia in grado di eseguire la suddivisione in lettura/scrittura e inviare query SELECT a un back-end e tutte le scritture e SELECT...FOR UPDATE a un separato backend.
Tenere traccia di tutte le metriche rese disponibili da HAProxy è molto importante; devi essere in grado di conoscere lo stato del tuo proxy, soprattutto per sapere se hai riscontrato problemi.
ClusterControl ha sempre reso disponibile una pagina di stato HAProxy che mostra lo stato del proxy in tempo reale. Ora, con i nuovi dashboard SCUMM (Severalnines ClusterControl Unified Monitoring &Management) basati su Prometheus, è possibile monitorare facilmente come queste metriche cambiano nel tempo.
Questo post del blog esplorerà le diverse metriche presentate nella dashboard HAProxy SCUMM.
Esplorazione del dashboard HAProxy in ClusterControl
Tutti i dashboard Prometheus e SCUMM sono disabilitati per impostazione predefinita in ClusterControl. Tuttavia, per distribuirli per un determinato cluster è solo questione di un clic. Se monitori più cluster con ClusterControl, puoi riutilizzare la stessa istanza Prometheus per ogni cluster.
Una volta distribuito, puoi accedere al dashboard HAProxy. Diamo un'occhiata ai dati disponibili nella dashboard:
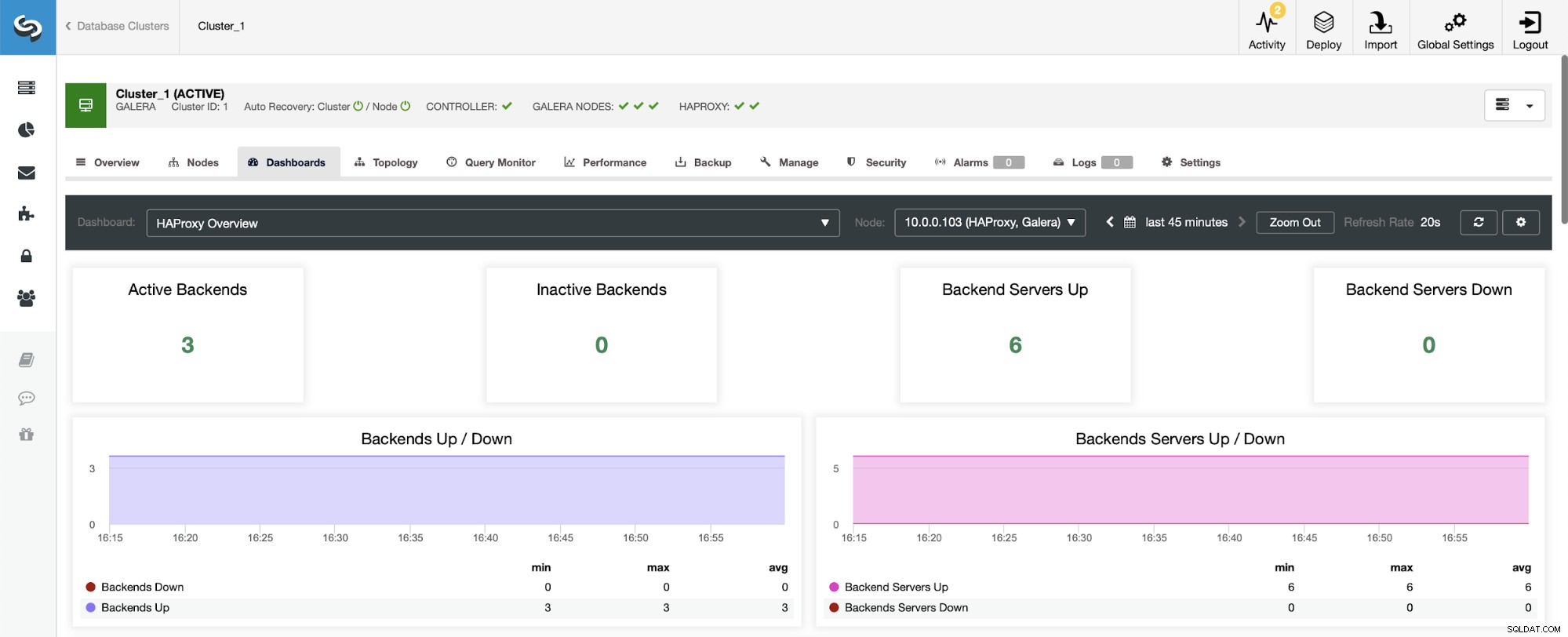
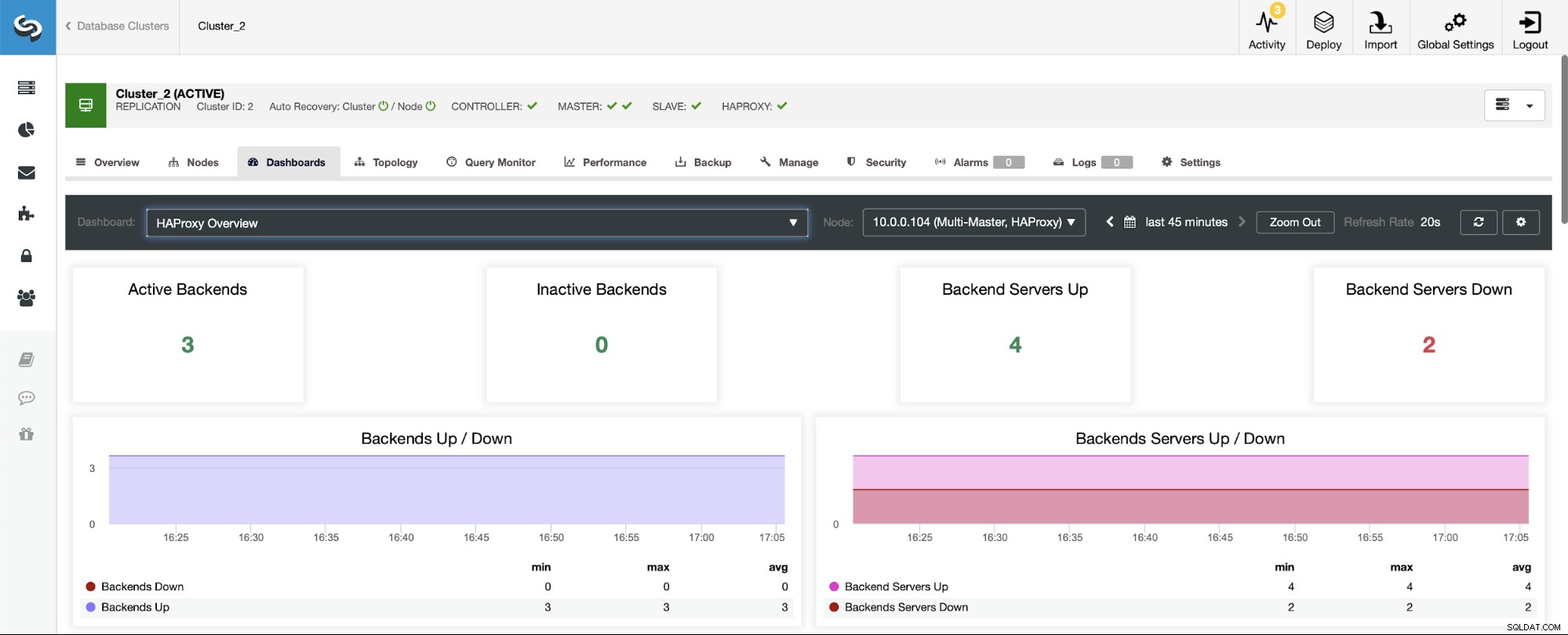
La prima cosa che vedrai quando accedi alla dashboard HAProxy è informazioni sullo stato dei tuoi backend. Qui, tieni presente che ciò che vedi potrebbe dipendere dal tipo di cluster e da come hai distribuito HAProxy. In questo caso, abbiamo distribuito un cluster Galera e HAProxy è stato distribuito in modalità round robin. Pertanto, vengono visualizzati tre backend per le letture e tre per le scritture, sei in totale. Questo è anche il motivo per cui vedi tutti i backend contrassegnati come "Up".
In uno scenario con un cluster di replica, le cose sembreranno diverse poiché HAProxy verrà distribuito in una divisione di lettura/scrittura e gli script manterranno attivo e funzionante un solo host (master) nella backend.
Nota, ecco perché di seguito vedi due server backend contrassegnati come "Down":
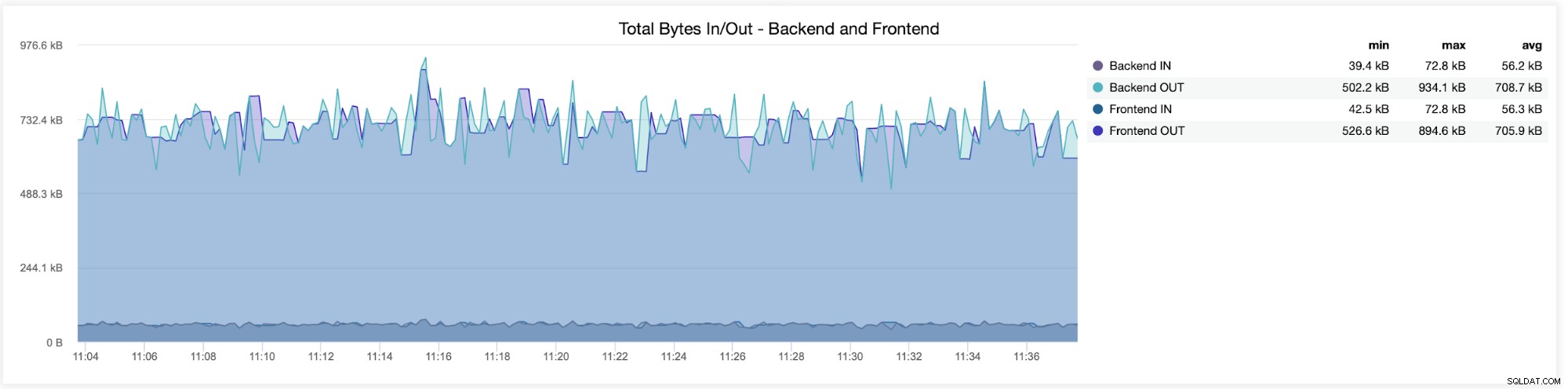
Nel grafico seguente vedrai i dati inviati e ricevuti da entrambi backend (da HAProxy ai server di database) e frontend (tra HAProxy e host client):
Puoi anche controllare la distribuzione del traffico tra i backend nella tua configurazione HAProxy. In questo caso, abbiamo due backend e le query vengono inviate tramite la porta 3308, che funge da punto di accesso round-robin al nostro cluster Galera:
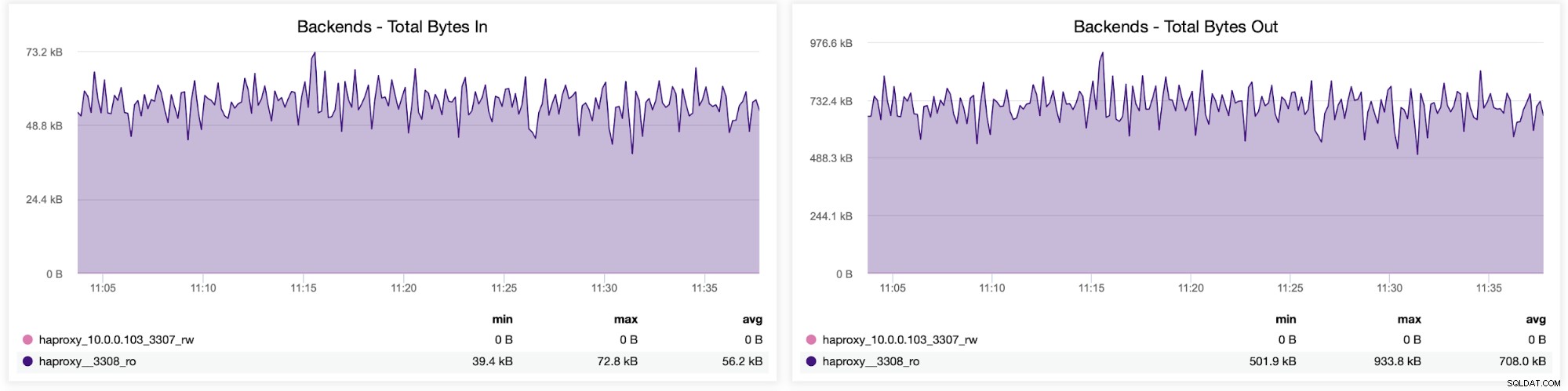
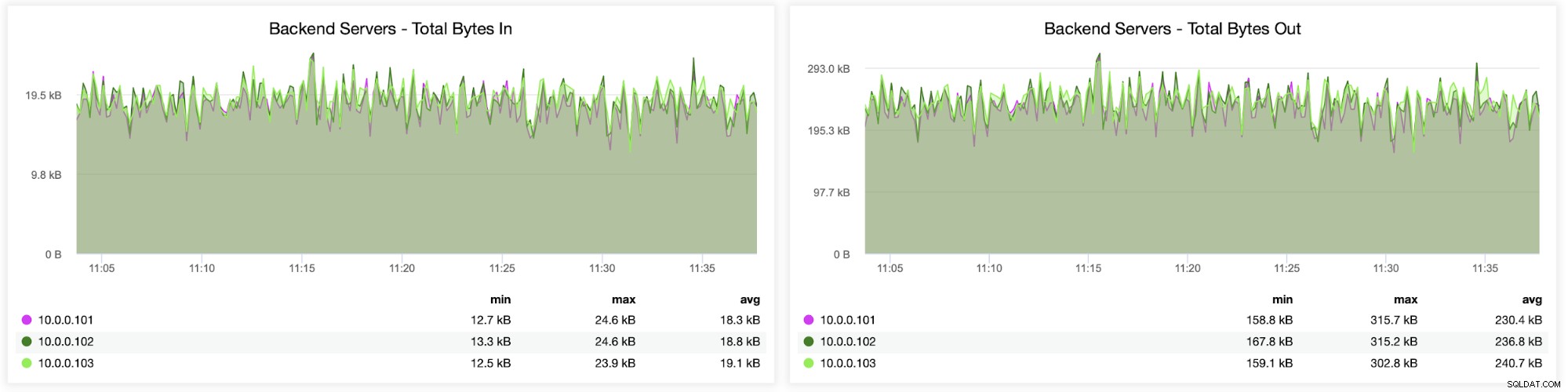
In seguito, puoi vedere come il traffico è stato distribuito su tutti i server back-end. In questo scenario, a causa del modello di accesso round robin, i dati sono stati distribuiti più o meno uniformemente su tutti e tre i server Galera back-end:
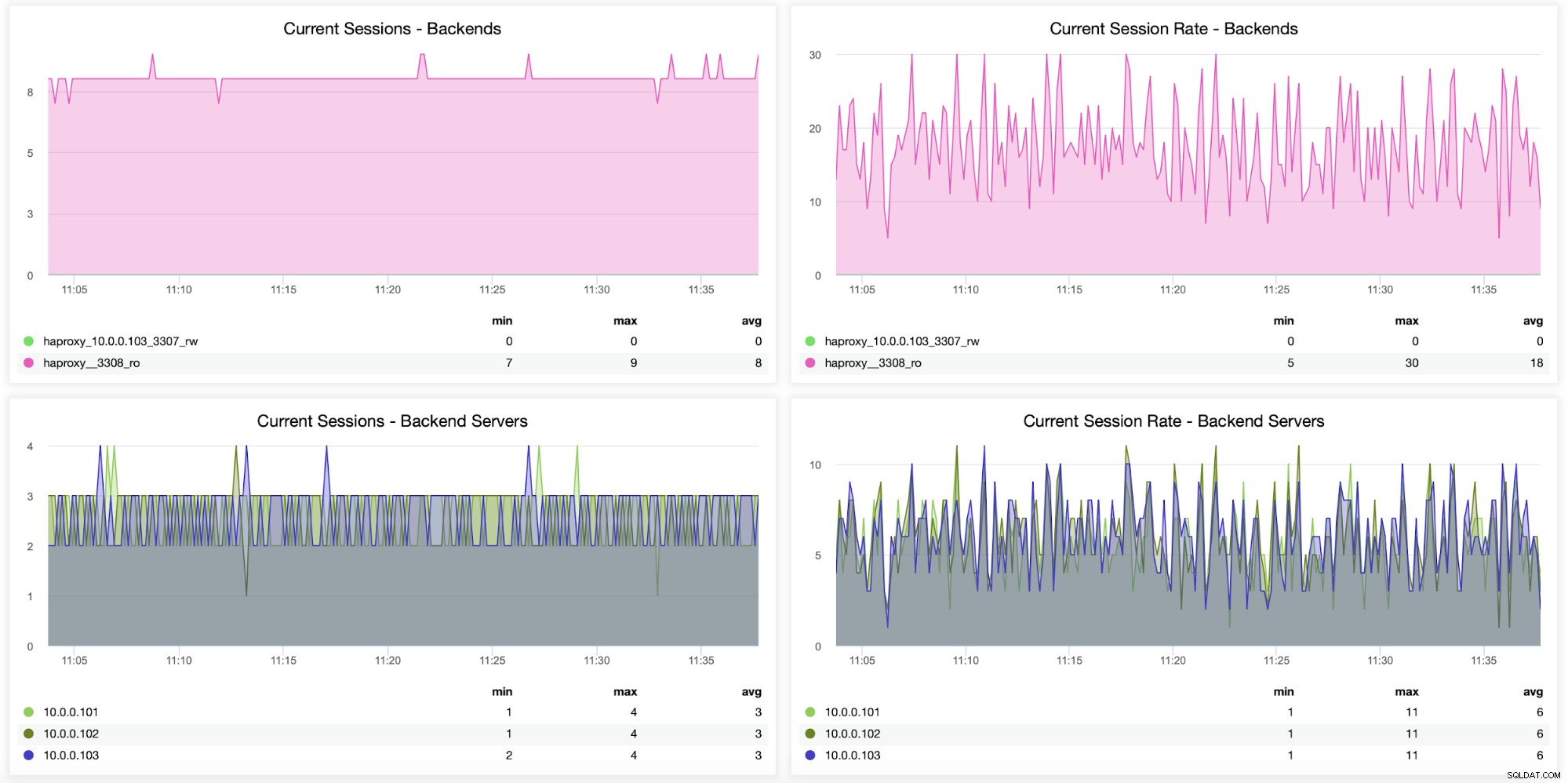
Informazioni sulle sessioni, incluso quante sessioni sono state aperte da HAProxy al back-end server, possono anche essere monitorati, come si vede nel grafico seguente. Puoi anche tenere traccia di quante volte al secondo è stata aperta una nuova sessione al back-end e come appaiono queste metriche in base al server di back-end.
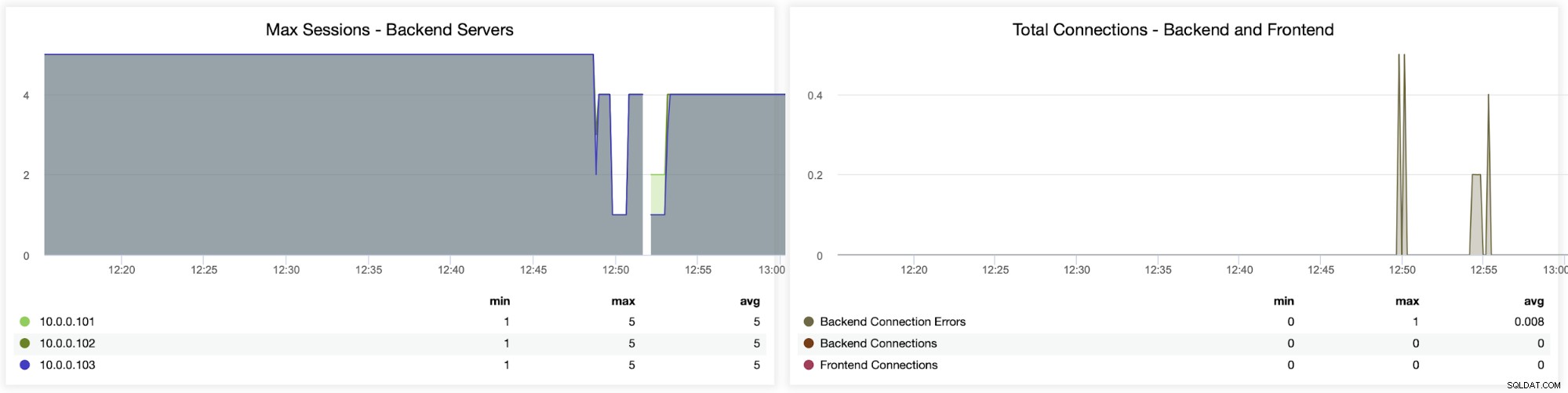
I due grafici seguenti mostrano il numero massimo di sessioni per server backend e quando sono comparsi problemi di connettività. Questo può essere molto utile per scopi di debug quando si verifica un errore di configurazione sull'istanza HAProxy e le connessioni iniziano a cadere.
Questo grafico successivo è potenzialmente più prezioso in quanto mostra varie metriche relative all'errore gestione, come errori, errori di richiesta, tentativi sul lato back-end, ecc. C'è anche un grafico "Sessioni" che mostra una panoramica delle metriche di sessione.
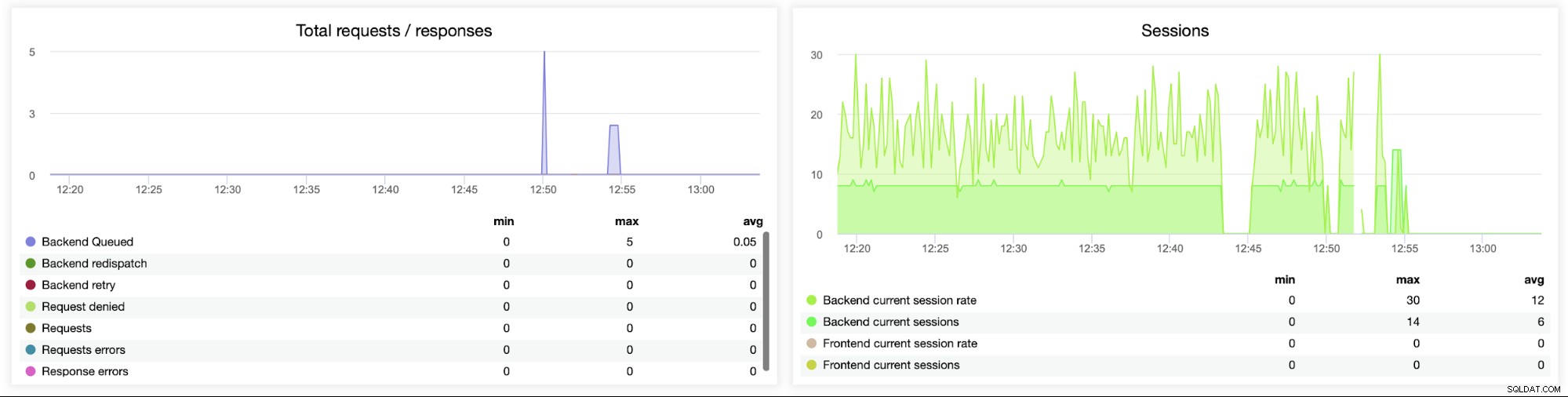
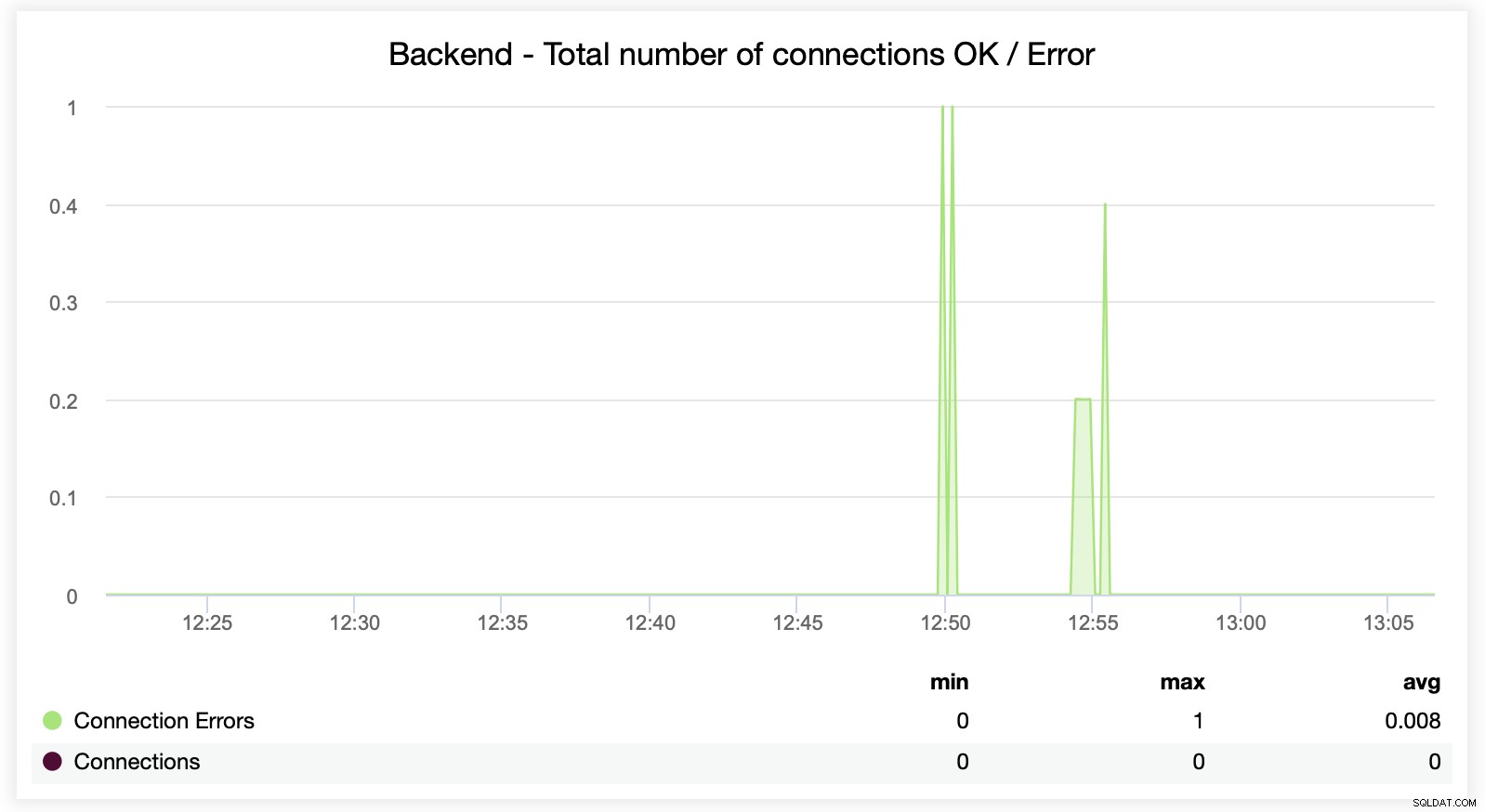
Qui puoi vedere che ClusterControl tiene traccia degli errori di connessione in tempo reale, che può aiutare a individuare il momento preciso in cui i problemi hanno iniziato a evolversi.
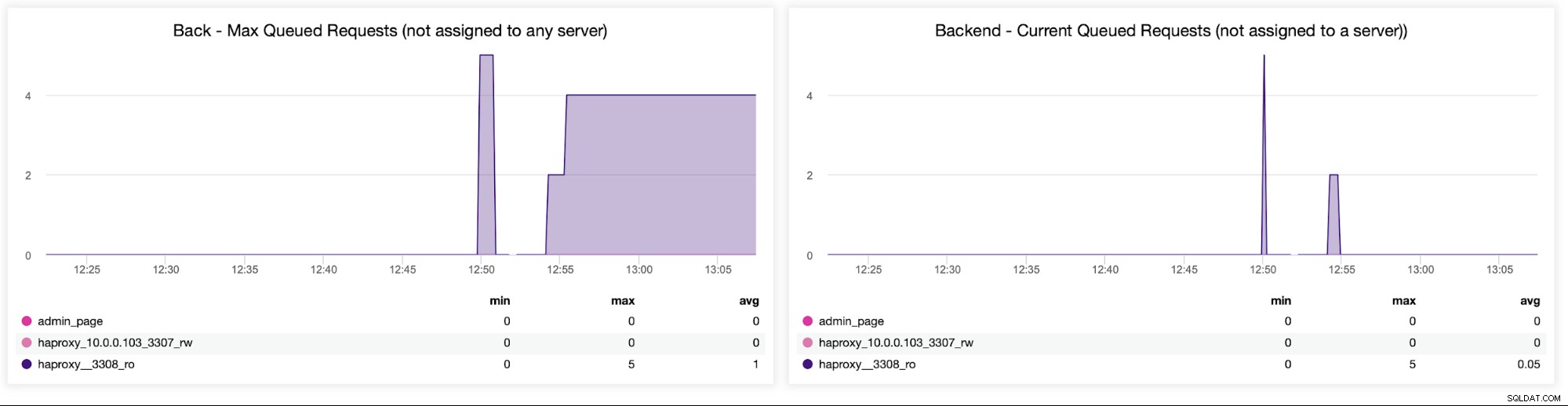
Infine, esamineremo i seguenti due grafici relativi alle richieste in coda . HAProxy accoda le richieste al back-end se i server back-end sono sovrasaturati. Questo può puntare, ad esempio, ai server di database sovraccarichi, che non possono gestire più traffico.
Conclusione
La distribuzione e il monitoraggio del sistema di bilanciamento del carico HAProxy in ClusterControl può semplificare il lavoro di gestione e monitoraggio delle connessioni. Avere una chiara visibilità sulle prestazioni dei back-end, sulla distribuzione del traffico, sulle metriche di sessione, sugli errori di connessione e sul numero di richieste in coda può aiutare a garantire la disponibilità e la scalabilità di qualsiasi configurazione di database.
ClusterControl rende l'impostazione e il monitoraggio dei sistemi di bilanciamento del carico un gioco da ragazzi per qualsiasi configurazione di database. Non usi ancora ClusterControl? Se desideri vedere di persona quanto sia facile distribuire e monitorare il tuo sistema di bilanciamento del carico HAProxy con ClusterControl, ti invitiamo a una prova gratuita di 30 giorni della piattaforma, senza vincoli. Per una guida più dettagliata sul perché e come utilizzare HAProxy per il bilanciamento del carico, consulta il nostro tutorial sul bilanciamento del carico MySQL con HAProxy.