Negli ultimi due blog, abbiamo spiegato come eseguire un cluster Galera su Docker, sia su Docker autonomo che su Docker Swarm multi-host con rete overlay. In questo post del blog, esamineremo l'esecuzione di Galera Cluster su Kubernetes, uno strumento di orchestrazione per eseguire container su larga scala. Alcune parti sono diverse, ad esempio come l'applicazione deve connettersi al cluster, come Kubernetes gestisce il failover e come funziona il bilanciamento del carico in Kubernetes.
Kubernetes vs Sciame Docker
Il nostro obiettivo finale è garantire che Galera Cluster funzioni in modo affidabile in un ambiente container. In precedenza abbiamo trattato Docker Swarm e si è scoperto che l'esecuzione di Galera Cluster su di esso ha una serie di blocchi, che impediscono che sia pronto per la produzione. Il nostro viaggio ora continua con Kubernetes, uno strumento di orchestrazione di container di livello produttivo. Vediamo quale livello di "predisposizione alla produzione" può supportare durante l'esecuzione di un servizio con stato come Galera Cluster.
Prima di andare oltre, evidenziamo alcune delle differenze chiave tra Kubernetes (1.6) e Docker Swarm (17.03) durante l'esecuzione di Galera Cluster sui container:
- Kubernetes supporta due sonde di controllo dello stato:vivacità e prontezza. Questo è importante quando si esegue un cluster Galera su container, perché un container Galera attivo non significa che sia pronto per essere utilizzato e dovrebbe essere incluso nel set di bilanciamento del carico (si pensi a uno stato di joiner/donatore). Docker Swarm supporta solo una sonda di controllo dello stato simile alla vivacità di Kubernetes, un contenitore è integro e continua a funzionare o non è integro e viene riprogrammato. Leggi qui per i dettagli.
- Kubernetes ha una dashboard dell'interfaccia utente accessibile tramite "kubectl proxy".
- Docker Swarm supporta solo il bilanciamento del carico round robin (ingresso), mentre Kubernetes utilizza meno connessione.
- Docker Swarm supporta la mesh di routing per pubblicare un servizio sulla rete esterna, mentre Kubernetes supporta qualcosa di simile chiamato NodePort, oltre a bilanciatori di carico esterni (GCE GLB/AWS ELB) e nomi DNS esterni (come per v1.7)
Installazione di Kubernetes utilizzando Kubeadm
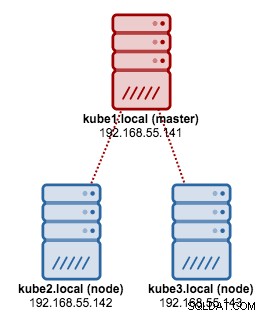
Useremo kubeadm per installare un cluster Kubernetes a 3 nodi su CentOS 7. È composto da 1 master e 2 nodi (minion). La nostra architettura fisica si presenta così:
1. Installa kubelet e Docker su tutti i nodi:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. Sul master, inizializza il master, copia il file di configurazione, configura la rete Pod utilizzando Weave e installa Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Poi sugli altri nodi rimanenti:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Verifica che i nodi siano pronti:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Ora abbiamo un cluster Kubernetes per la distribuzione del cluster Galera.
Galera Cluster su Kubernetes
In questo esempio, distribuiremo un MariaDB Galera Cluster 10.1 utilizzando l'immagine Docker estratta dal nostro repository DockerHub. I file di definizione YAML utilizzati in questa distribuzione possono essere trovati nella directory example-kubernetes nel repository Github.
Kubernetes supporta numerosi controller di distribuzione. Per distribuire un Cluster Galera, è possibile utilizzare:
- ReplicaSet
- StatefulSet
Ognuno di loro ha i suoi pro e contro. Esamineremo ciascuno di essi e vedremo qual è la differenza.
Prerequisiti
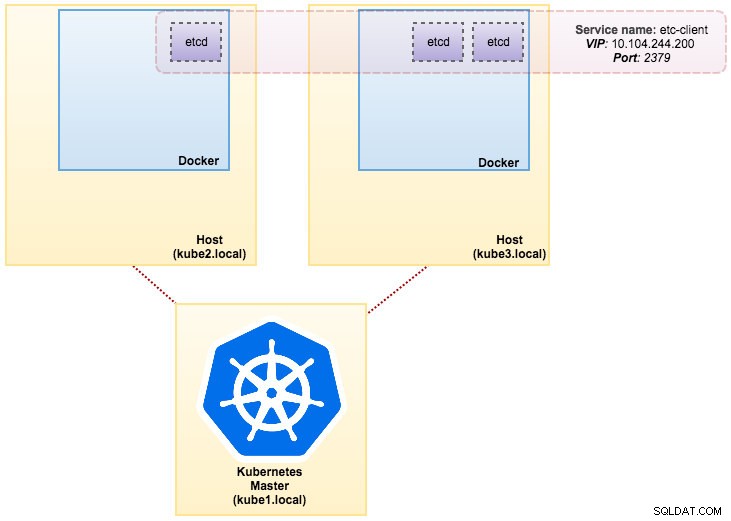
L'immagine che abbiamo creato richiede un etcd (autonomo o cluster) per il rilevamento del servizio. Per eseguire un cluster etcd è necessario che ogni istanza etcd sia in esecuzione con comandi diversi, quindi utilizzeremo il controller Pods invece di Deployment e creeremo un servizio chiamato "etcd-client" come endpoint per i Pod etcd. Il file di definizione etcd-cluster.yaml dice tutto.
Per distribuire un cluster etcd a 3 pod, esegui semplicemente:
$ kubectl create -f etcd-cluster.yamlVerifica se il cluster etcd è pronto:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dLa nostra architettura ora ha un aspetto simile a questo:
 Severalnines MySQL su Docker:come containerizzare il databaseScopri tutto ciò che devi capire quando consideri di eseguire un servizio MySQL su inizio della virtualizzazione dei container DockerScarica il white paper
Severalnines MySQL su Docker:come containerizzare il databaseScopri tutto ciò che devi capire quando consideri di eseguire un servizio MySQL su inizio della virtualizzazione dei container DockerScarica il white paper Utilizzo di ReplicaSet
Un ReplicaSet garantisce che un numero specificato di "repliche" del pod sia in esecuzione in un dato momento. Tuttavia, una distribuzione è un concetto di livello superiore che gestisce i ReplicaSet e fornisce aggiornamenti dichiarativi ai pod insieme a molte altre utili funzionalità. Pertanto, si consiglia di utilizzare le distribuzioni anziché utilizzare direttamente i ReplicaSet, a meno che non sia necessaria l'orchestrazione degli aggiornamenti personalizzata o non richiedano affatto aggiornamenti. Quando utilizzi le distribuzioni, non devi preoccuparti della gestione dei ReplicaSet che creano. Le distribuzioni possiedono e gestiscono i propri ReplicaSet.
Nel nostro caso, utilizzeremo Deployment come controller del carico di lavoro, come mostrato in questa definizione YAML. Possiamo creare direttamente il Galera Cluster ReplicaSet and Service eseguendo il seguente comando:
$ kubectl create -f mariadb-rs.ymlVerifica se il cluster è pronto esaminando ReplicaSet (rs), pod (po) e servizi (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dDall'output sopra, possiamo illustrare i nostri Pod e il servizio come di seguito:
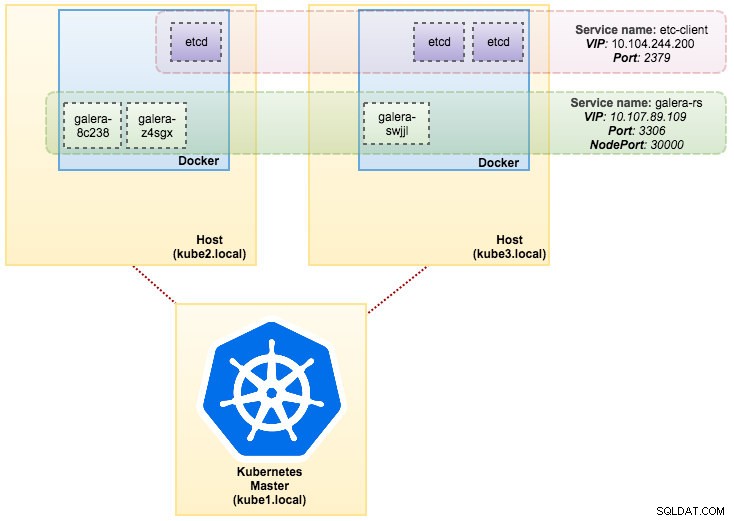
L'esecuzione di Galera Cluster su ReplicaSet è simile a trattarlo come un'applicazione senza stato. Orchestra la creazione, l'eliminazione e gli aggiornamenti del pod e può essere preso di mira per la scalabilità automatica del pod orizzontale (HPA), ovvero un ReplicaSet può essere ridimensionato automaticamente se soddisfa determinate soglie o obiettivi (utilizzo della CPU, pacchetti al secondo, richiesta al secondo ecc).
Se uno dei nodi Kubernetes si interrompe, i nuovi Pod verranno programmati su un nodo disponibile per soddisfare le repliche desiderate. I volumi associati al Pod verranno eliminati se il Pod viene eliminato o riprogrammato. Il nome host del Pod verrà generato in modo casuale, rendendo più difficile tracciare l'ubicazione del contenitore semplicemente osservando il nome host.
Tutto ciò funziona abbastanza bene negli ambienti di test e staging, dove puoi eseguire un ciclo di vita completo del contenitore come distribuire, ridimensionare, aggiornare e distruggere senza alcuna dipendenza. Aumentare e ridurre è semplice, aggiornando il file YAML e pubblicandolo nel cluster Kubernetes o utilizzando il comando scale:
$ kubectl scale replicaset galera-rs --replicas=5Utilizzo di StatefulSet
Conosciuto come PetSet nella versione precedente alla 1.6, StatefulSet è il modo migliore per distribuire Galera Cluster in produzione, perché:
- L'eliminazione e/o il ridimensionamento di uno StatefulSet non elimineranno i volumi associati a StatefulSet. Questo viene fatto per garantire la sicurezza dei dati, che è generalmente più preziosa di un'eliminazione automatica di tutte le risorse StatefulSet correlate.
- Per uno StatefulSet con N repliche, quando i pod vengono distribuiti, vengono creati in sequenza, in ordine da {0 .. N-1 }.
- Quando i Pod vengono eliminati, vengono chiusi in ordine inverso, da {N-1 .. 0}.
- Prima di applicare un'operazione di ridimensionamento a un Pod, tutti i suoi predecessori devono essere in esecuzione e pronti.
- Prima che un Pod venga terminato, tutti i suoi successori devono essere completamente chiusi.
StatefulSet fornisce un supporto di prima classe per i contenitori con stato. Fornisce una garanzia di distribuzione e ridimensionamento. Quando viene creato un cluster Galera a tre nodi, verranno distribuiti tre Pod nell'ordine db-0, db-1, db-2. db-1 non verrà distribuito prima che db-0 sia "In esecuzione e pronto" e db-2 non verrà distribuito fino a quando db-1 non sarà "In esecuzione e pronto". Se db-0 dovesse fallire, dopo che db-1 è "In esecuzione e pronto", ma prima dell'avvio di db-2, db-2 non verrà avviato fino a quando db-0 non viene riavviato correttamente e diventa "In esecuzione e pronto".
Utilizzeremo l'implementazione Kubernetes dell'archiviazione persistente denominata PersistentVolume e PersistentVolumeClaim. Questo per garantire la persistenza dei dati se il pod è stato riprogrammato sull'altro nodo. Anche se Galera Cluster fornisce la copia esatta dei dati su ogni replica, avere i dati persistenti in ogni pod è utile ai fini della risoluzione dei problemi e del ripristino.
Per creare una memoria persistente, dobbiamo prima creare PersistentVolume per ogni pod. I PV sono plug-in di volume come i volumi in Docker, ma hanno un ciclo di vita indipendente da qualsiasi singolo pod che utilizza il PV. Poiché implementeremo un cluster Galera a 3 nodi, dobbiamo creare 3 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirLa definizione sopra mostra che creeremo 3 PV, mappati sul percorso fisico dei nodi Kubernetes con 10 GB di spazio di archiviazione. Abbiamo definito ReadWriteOnce, il che significa che il volume può essere montato in lettura-scrittura da un solo nodo. Salva le righe precedenti in mariadb-pv.yml e pubblicalo su Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdQuindi, definisci le risorse PersistentVolumeClaim:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"La definizione sopra mostra che vorremmo rivendicare le risorse PV e utilizzare spec.selector.matchLabels per cercare il nostro PV (metadata.labels.app:galera-ss ) in base al rispettivo indice pod (metadata.labels.podindex ) assegnato da Kubernetes. Il nome.metadata la risorsa deve utilizzare il formato "{volumeMounts.name}-{pod}-{ordinal index}" definito in spec.templates.containers quindi Kubernetes sa quale punto di montaggio mappare la richiesta nel pod.
Salva le righe precedenti in mariadb-pvc.yml e pubblicalo su Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdIl nostro archivio persistente è ora pronto. Possiamo quindi avviare la distribuzione del cluster Galera creando una risorsa StatefulSet insieme alla risorsa del servizio Headless come mostrato in mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdOra, recupera il riepilogo della nostra distribuzione StatefulSet:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dA questo punto, il nostro Cluster Galera in esecuzione su StatefulSet può essere illustrato come nel diagramma seguente:
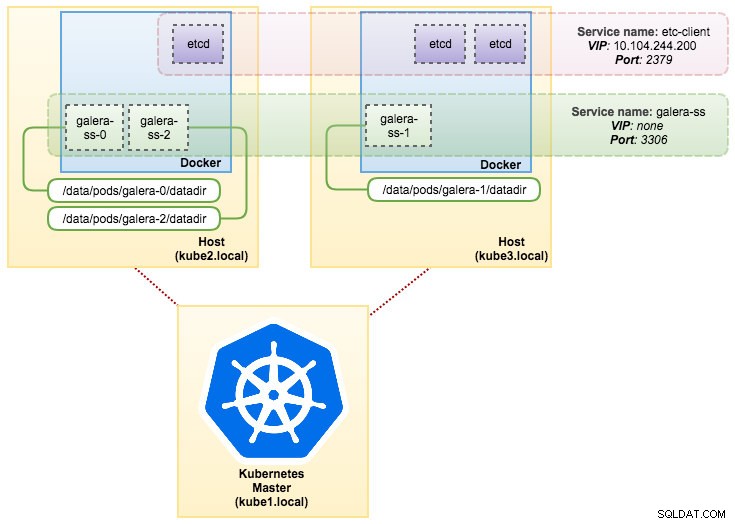
L'esecuzione su StatefulSet garantisce identificatori coerenti come nome host, indirizzo IP, ID di rete, dominio del cluster, Pod DNS e archiviazione. Ciò consente al Pod di distinguersi facilmente dagli altri in un gruppo di Pod. Il volume verrà mantenuto sull'host e non verrà eliminato se il Pod viene eliminato o riprogrammato su un altro nodo. Ciò consente il recupero dei dati e riduce il rischio di perdita totale dei dati.
Sul lato negativo, il tempo di implementazione sarà N-1 volte (N =repliche) in più perché Kubernetes obbedirà alla sequenza ordinale durante la distribuzione, la riprogrammazione o l'eliminazione delle risorse. Sarebbe un po' una seccatura preparare il PV e le attestazioni prima di pensare al ridimensionamento del cluster. Tieni presente che l'aggiornamento di uno StatefulSet esistente è attualmente un processo manuale, in cui puoi solo aggiornare spec.replicas al momento.
Connessione a Galera Cluster Service e Pod
Ci sono un paio di modi per connettersi al cluster di database. Puoi collegarti direttamente alla porta. Nell'esempio del servizio "galera-rs", utilizziamo NodePort, esponendo il servizio sull'IP di ciascun nodo su una porta statica (la NodePort). Viene creato automaticamente un servizio ClusterIP, a cui verrà instradato il servizio NodePort. Potrai contattare il servizio NodePort, dall'esterno del cluster, richiedendo {NodeIP}:{NodePort} .
Esempio di connessione esterna al Cluster Galera:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000All'interno dello spazio di rete Kubernetes, i Pod possono connettersi internamente tramite l'IP del cluster o il nome del servizio, recuperabile utilizzando il comando seguente:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Dall'elenco dei servizi, possiamo vedere che Galera Cluster ReplicaSet Cluster-IP è 10.107.89.109. Internamente, un altro pod può accedere al database tramite questo indirizzo IP o nome del servizio utilizzando la porta esposta, 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Puoi anche connetterti alla NodePort esterna dall'interno di qualsiasi pod sulla porta 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+La connessione ai Pod di back-end verrà bilanciata di conseguenza in base all'algoritmo di connessione minima.
Riepilogo
A questo punto, eseguire Galera Cluster su Kubernetes in produzione sembra molto più promettente rispetto a Docker Swarm. Come discusso nell'ultimo post del blog, le preoccupazioni sollevate vengono affrontate in modo diverso con il modo in cui Kubernetes orchestra i contenitori in StatefulSet (sebbene sia ancora una funzionalità beta nella v1.6). Ci auguriamo che l'approccio suggerito aiuti a eseguire Galera Cluster su container su larga scala in produzione.