Quando devi lavorare con un database con cui non hai familiarità al 100%, puoi essere sopraffatto dalle centinaia di metriche disponibili. Quali sono i più importanti? Cosa devo monitorare e perché? Quali modelli nelle metriche dovrebbero suonare alcuni campanelli d'allarme? In questo post del blog cercheremo di presentarti alcune delle metriche più importanti da tenere d'occhio durante l'esecuzione di MySQL o MariaDB in produzione.
Contatori stato Com_*
Inizieremo con i contatori Com_*, che definiscono il numero e i tipi di query eseguite da MySQL. Stiamo parlando di tipi di query come SELECT, INSERT, UPDATE e molti altri. È molto importante tenerli d'occhio poiché picchi improvvisi o cadute impreviste potrebbero suggerire che qualcosa è andato storto nel sistema.
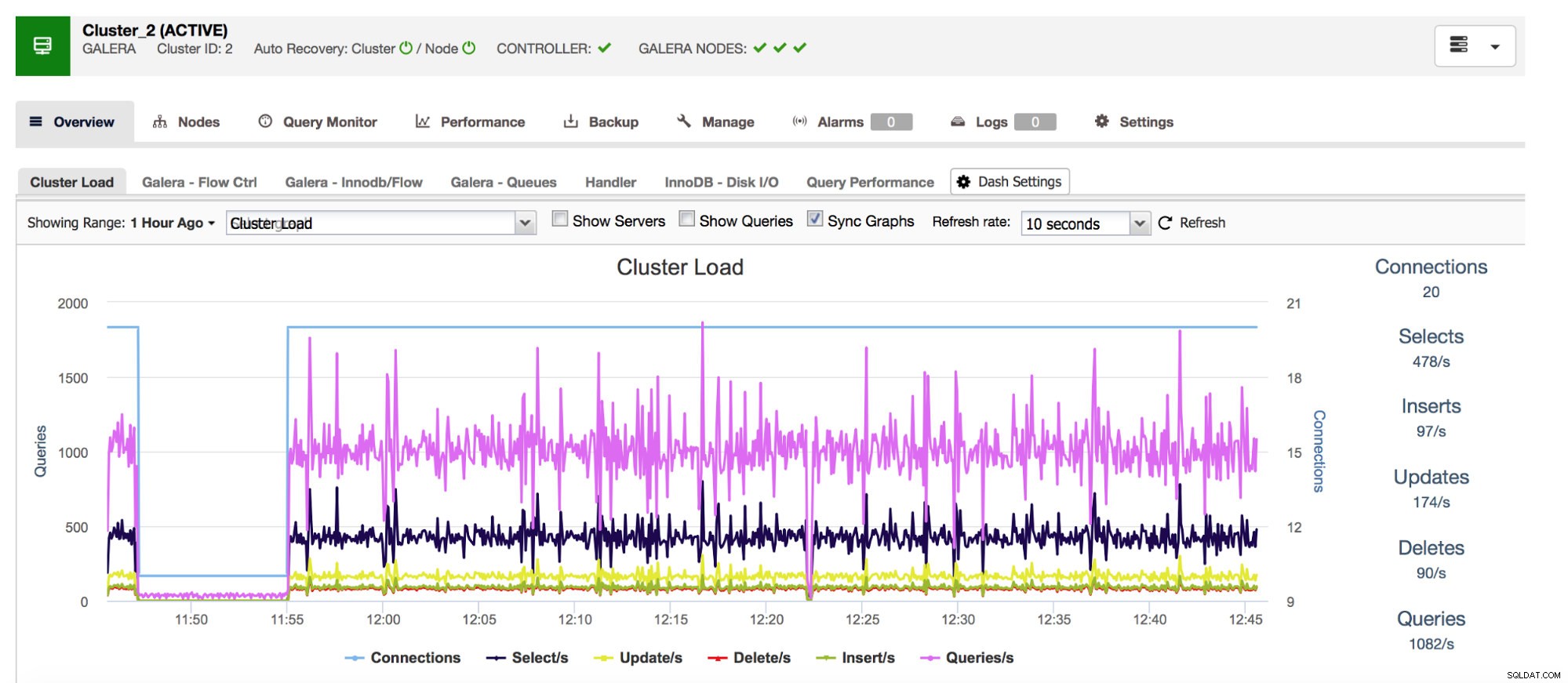
Il nostro sistema di gestione database all-inclusive ClusterControl mostra questi dati relativi ai tipi di query più comuni nella sezione "Panoramica".
Contatori di stato Gestore_*
Una categoria di parametri da tenere d'occhio sono i contatori Handler_* in MySQL. I contatori Com_* ti dicono che tipo di query sta eseguendo la tua istanza MySQL, ma una SELECT può essere completamente diversa da un'altra:SELECT potrebbe essere una ricerca della chiave primaria, può anche essere una scansione della tabella se non è possibile utilizzare un indice. I gestori spiegano in che modo MySQL accede ai dati archiviati:questo è molto utile per indagare sui problemi di prestazioni e valutare se esiste un possibile guadagno nella revisione delle query e nell'indicizzazione aggiuntiva.
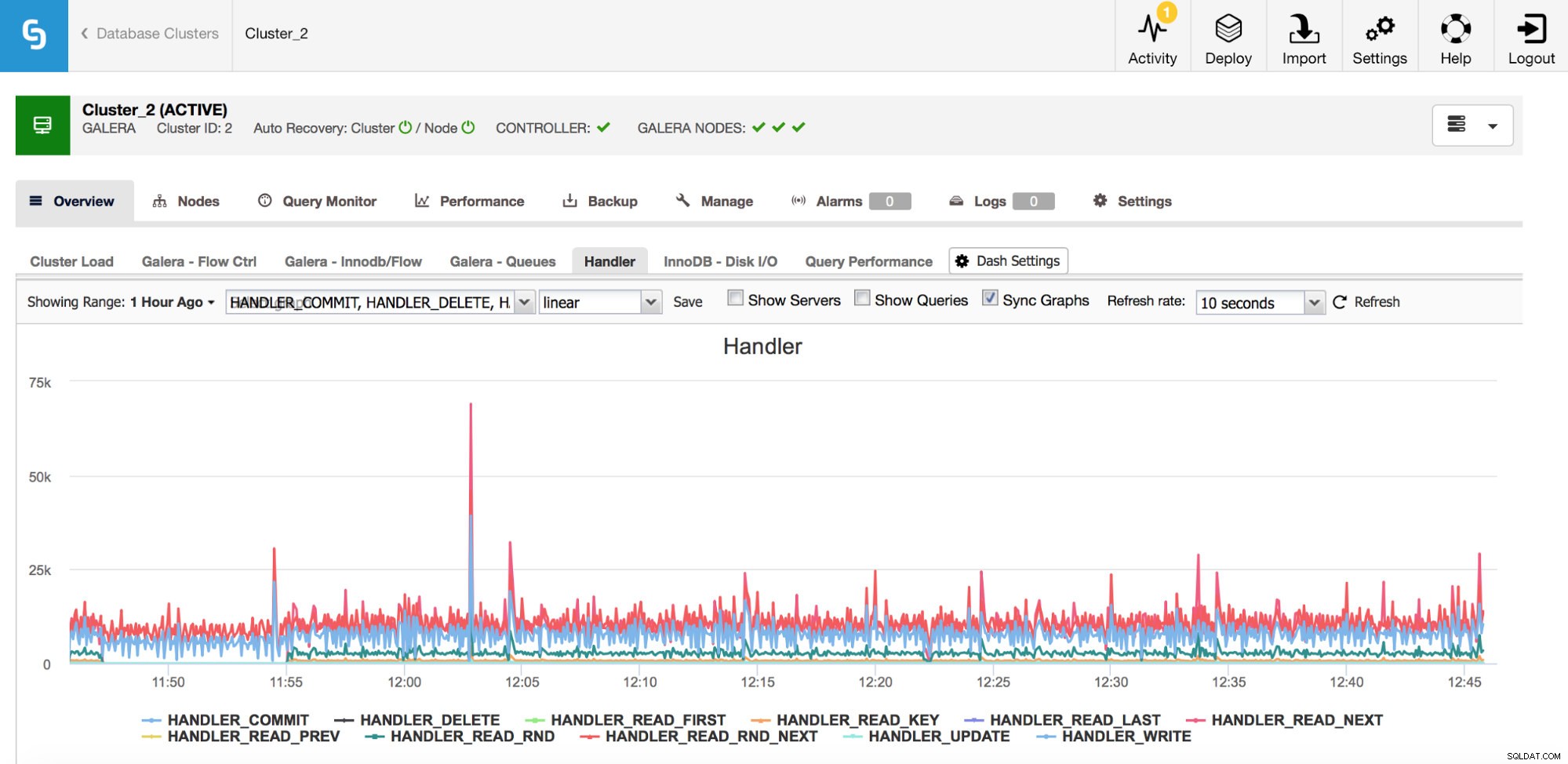
Come puoi vedere dal grafico sopra ci sono molte metriche da tracciare (e ClusterControl grafici le più importanti) - non le tratteremo tutte qui (puoi trovare le descrizioni nella documentazione di MySQL) ma vorremmo evidenziare le quelli più importanti.
Handler_read_rnd_next - ogni volta che MySQL accede a una riga senza una ricerca nell'indice, in ordine sequenziale, questo contatore verrà aumentato. Se nel tuo carico di lavoro handler_read_rnd_next è responsabile di un'alta percentuale dell'intero traffico, significa che le tue tabelle, molto probabilmente, potrebbero utilizzare alcuni indici aggiuntivi perché MySQL esegue molte scansioni di tabelle.
Handler_read_next e handler_read_prev:questi due contatori vengono aggiornati ogni volta che MySQL esegue una scansione dell'indice, avanti o indietro. Handler_read_first e handler_read_last potrebbero far luce su che tipo di scansioni dell'indice sono:se stiamo parlando di una scansione completa dell'indice (avanti o indietro), quei due contatori verranno aggiornati.
Handler_read_key - questo contatore, d'altra parte, se il suo valore è alto, ti dice che le tue tabelle sono ben indicizzate poiché molte delle righe sono state accedute tramite una ricerca nell'indice.
Ritardo di replica
Se stai lavorando con la replica di MySQL, il ritardo di replica è una metrica che vuoi assolutamente monitorare. Il ritardo di replica è inevitabile e dovrai affrontarlo, ma per affrontarlo devi capire perché accade. Per questo il primo passo sarà sapere _quando_ è apparso.
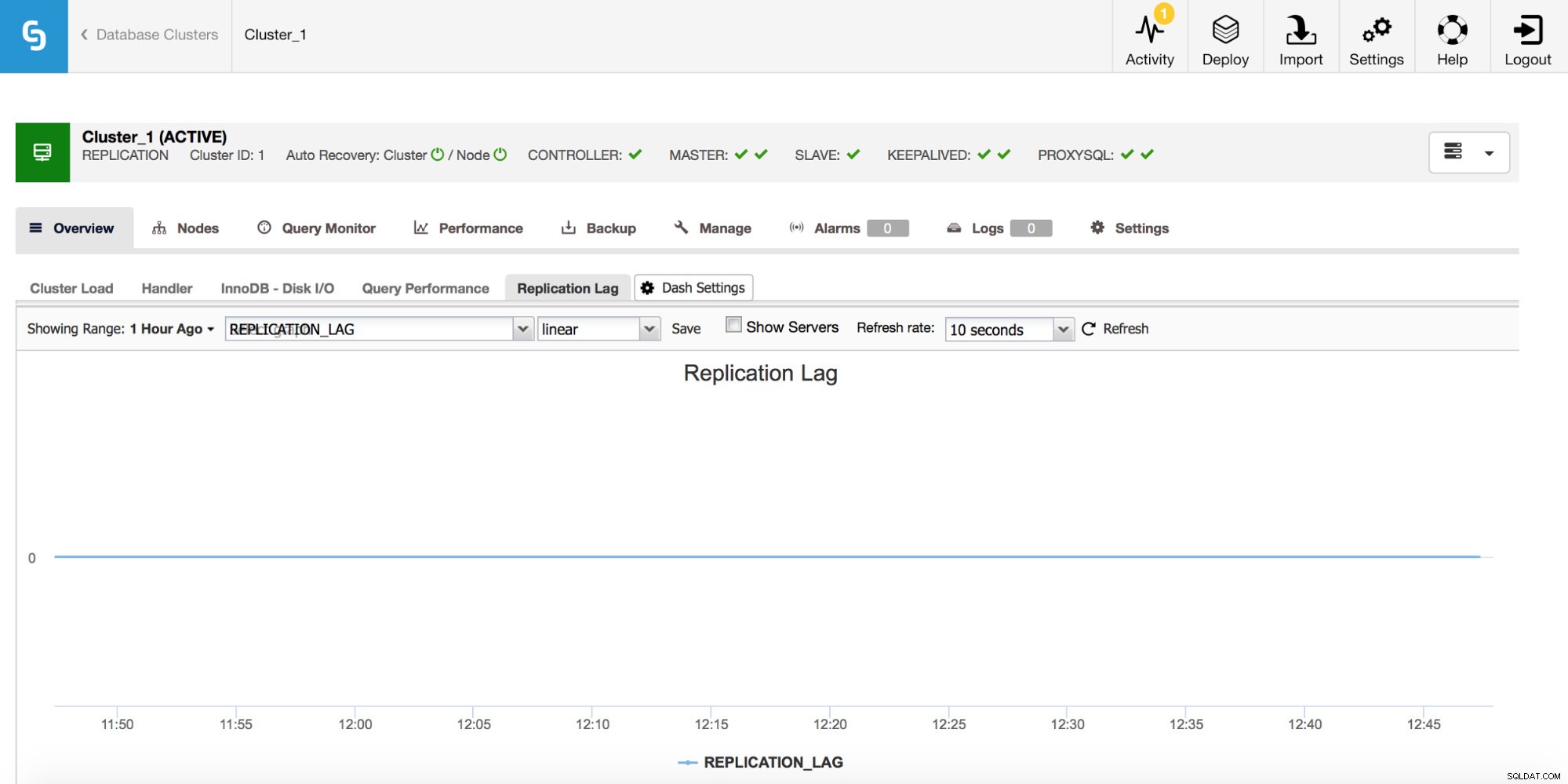
Ogni volta che vedi un picco del ritardo di replica, vorresti controllare altri grafici per ottenere più indizi:perché è successo? Cosa potrebbe averlo causato? I motivi potrebbero essere diversi:DML lunghi e pesanti, aumento significativo del numero di DML eseguiti in un breve periodo di tempo, limitazioni di CPU o I/O.
I/O InnoDB
Esistono numerosi parametri importanti da monitorare relativi all'I/O.
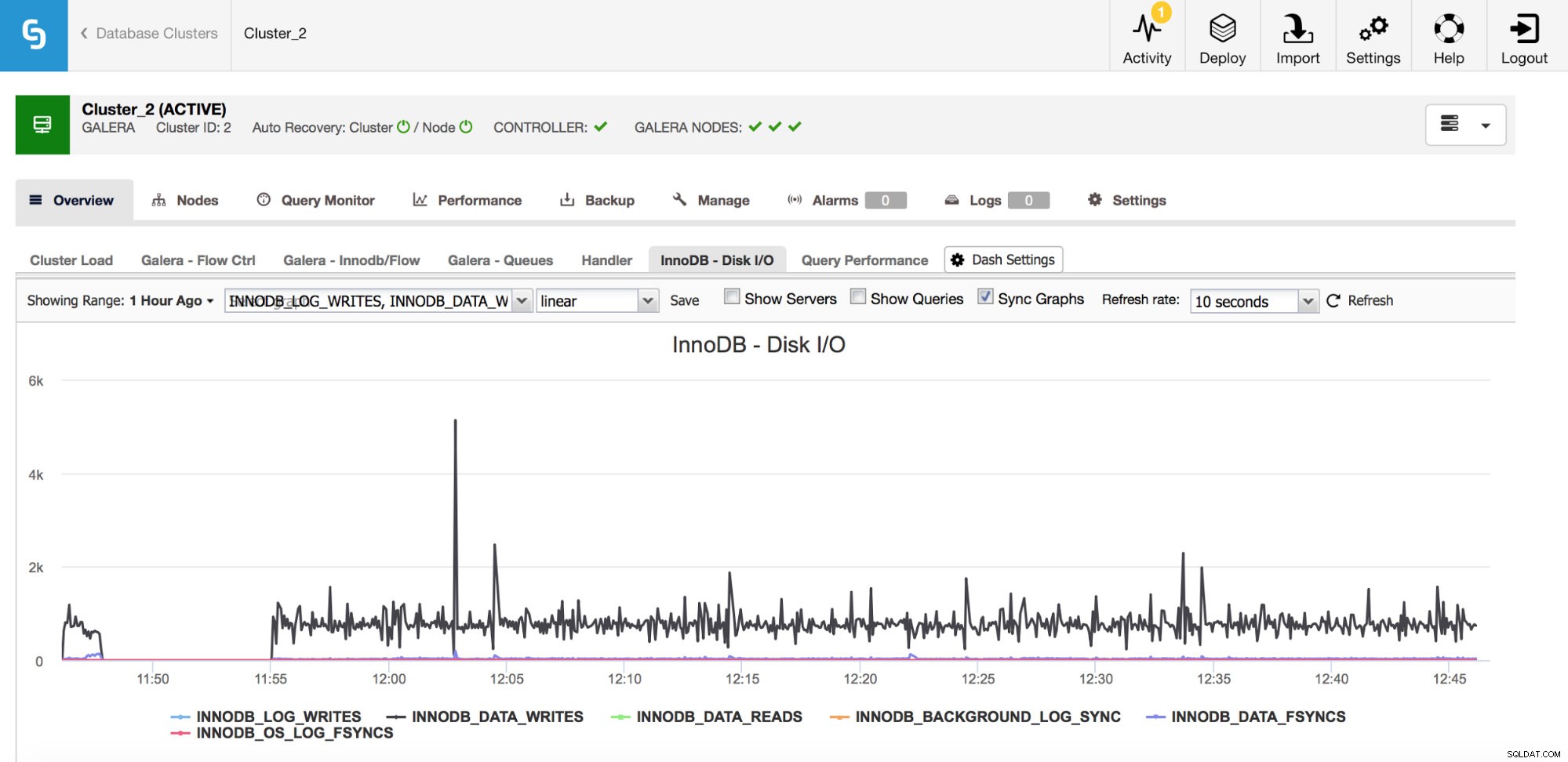
Nel grafico sopra, puoi vedere un paio di parametri che ti dicono che tipo di I/O fa InnoDB:scritture e letture di dati, scritture di redo log, fsyncs. Tali metriche ti aiuteranno a decidere, ad esempio, se il ritardo di replica è stato causato da un picco di I/O o forse da qualche altro motivo. È anche importante tenere traccia di queste metriche e confrontarle con i tuoi limiti hardware:se ti stai avvicinando ai limiti hardware dei tuoi dischi, forse è il momento di esaminarlo prima che abbia effetti più gravi sulle prestazioni del tuo database.
Diversinines DevOps Guide to Database ManagementScopri cosa devi sapere per automatizzare e gestire i tuoi database open sourceScarica gratuitamenteMetriche di Galera - Controllo del flusso e code
Se ti capita di utilizzare Galera Cluster (indipendentemente dal sapore che usi), ci sono un altro paio di metriche che vorresti monitorare da vicino, queste sono in qualche modo legate insieme. I primi sono le metriche relative al controllo del flusso.
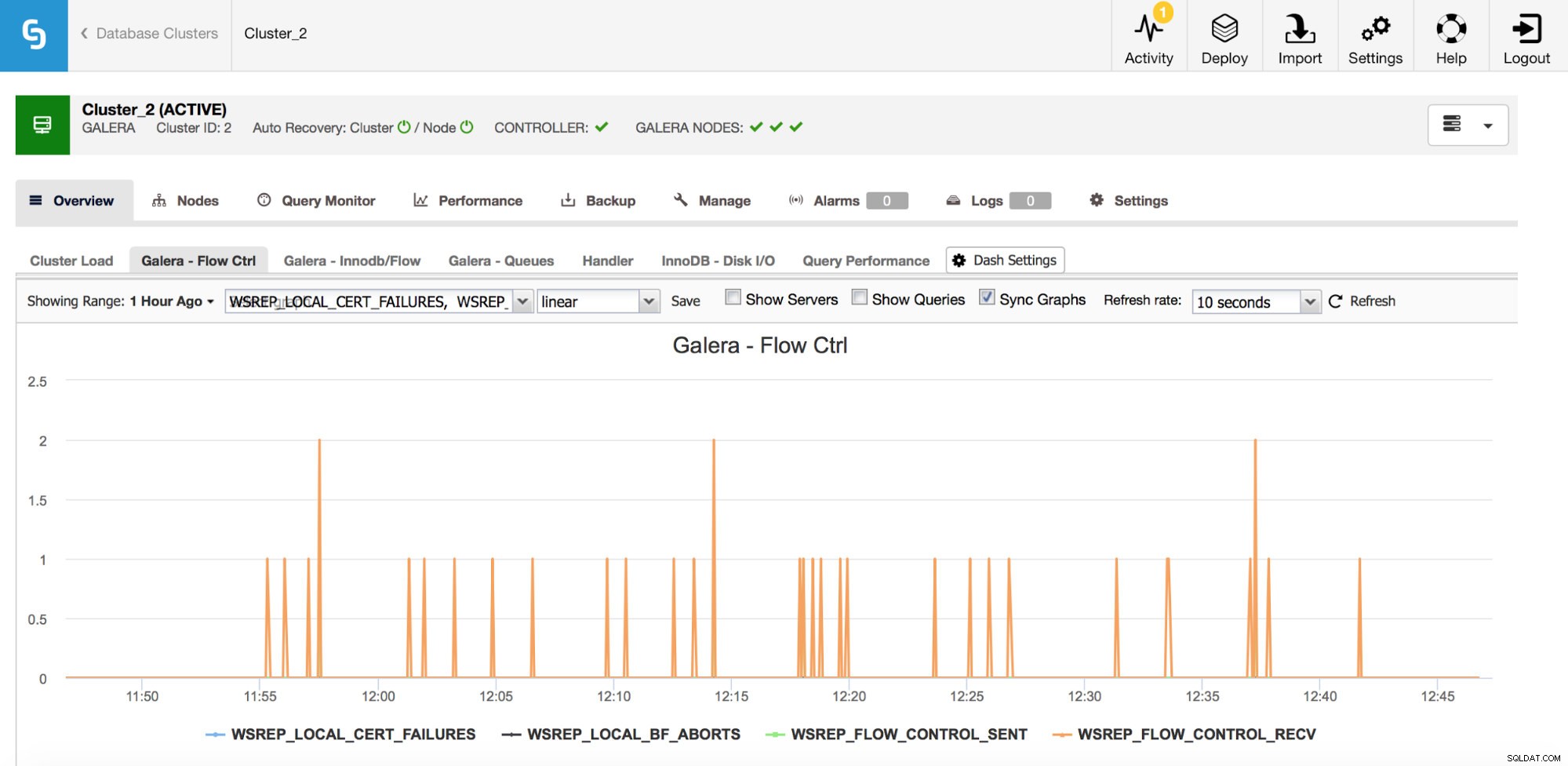
Il controllo del flusso, in Galera, è un mezzo per mantenere sincronizzato il cluster. Ogni volta che un nodo si blocca e non riesce a tenere il passo con il resto del cluster, inizia a inviare messaggi di controllo del flusso chiedendo ai nodi rimanenti del cluster di rallentare. Questo gli permette di recuperare. Ciò riduce le prestazioni del cluster, quindi è importante essere in grado di dire quale nodo e quando ha iniziato a inviare messaggi di controllo del flusso. Questo può spiegare alcuni dei rallentamenti riscontrati dagli utenti o limitare la finestra di tempo e l'host da utilizzare per ulteriori indagini.
La seconda serie di metriche da monitorare sono quelle relative alle code di invio e ricezione in Galera.
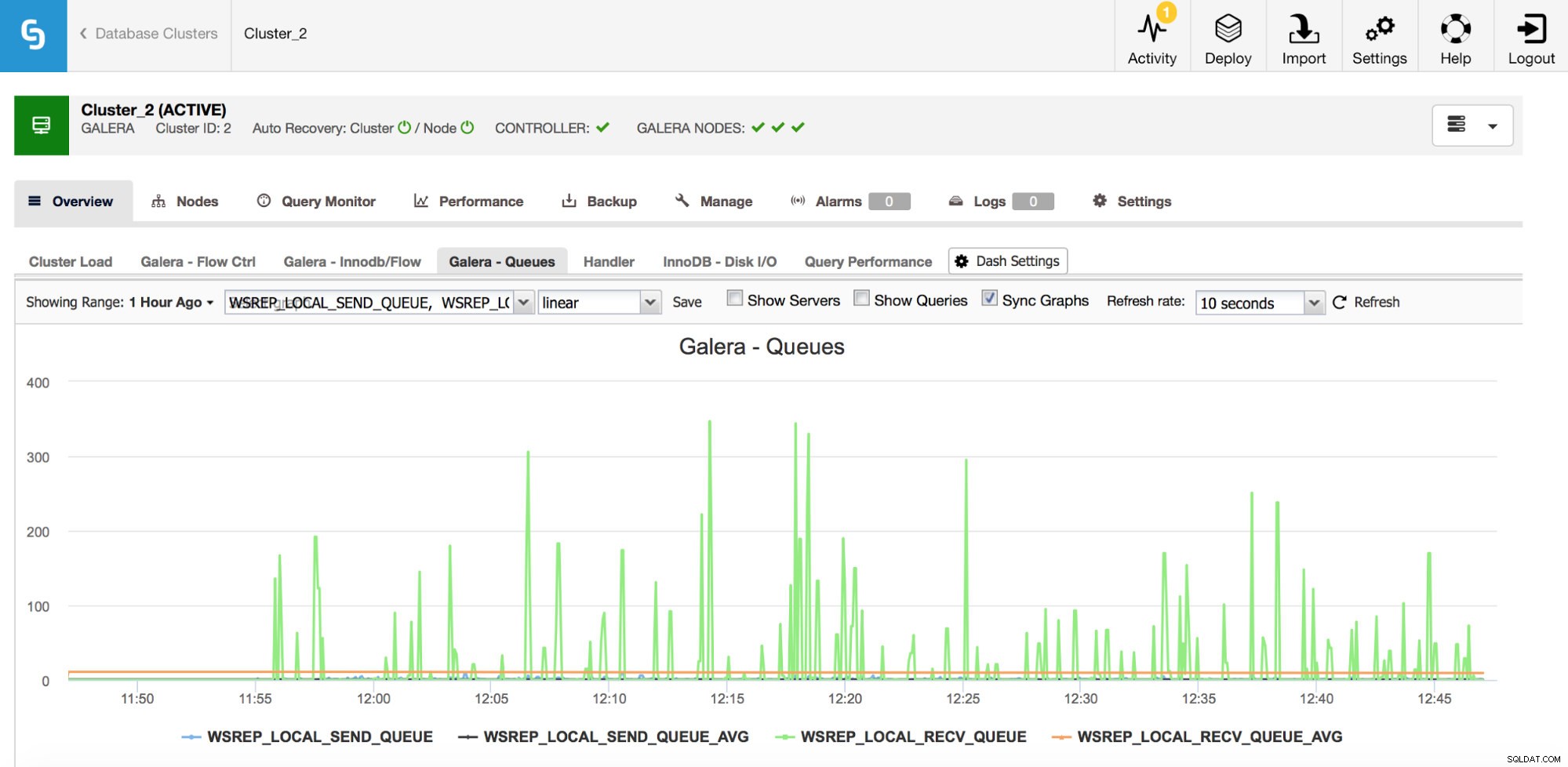
I nodi Galera possono memorizzare nella cache i set di scrittura (transazioni) se non possono applicarli tutti immediatamente. Se necessario, possono anche memorizzare nella cache i set di scritture che stanno per essere inviati ad altri nodi (se un determinato nodo riceve scritture dall'applicazione). Entrambi i casi sono sintomi di un rallentamento che, molto probabilmente, comporterà l'invio di messaggi di controllo del flusso e richiederà alcune indagini:perché è successo, su quale nodo, a che ora?
Questa è, ovviamente, solo la punta dell'iceberg se consideriamo tutte le metriche rese disponibili da MySQL, tuttavia, non puoi sbagliare se inizi a guardare quelle che abbiamo trattato qui, oltre alle normali metriche del sistema operativo/hardware come la CPU , memoria, utilizzo del disco e stato dei servizi.



