Costruire l'alta disponibilità, un passo alla volta
Quando si tratta di infrastruttura di database, la vogliamo tutti. Tutti ci sforziamo di creare una configurazione altamente disponibile. La ridondanza è la chiave. Iniziamo a implementare la ridondanza al livello più basso e continuiamo a salire. Si inizia con l'hardware:alimentatori ridondanti, raffreddamento ridondante, dischi hot-swap. Livello di rete:più NIC collegate insieme e collegate a diversi switch che utilizzano router ridondanti. Per l'archiviazione utilizziamo dischi impostati in RAID, che offre prestazioni migliori ma anche ridondanza. Quindi, a livello software, utilizziamo tecnologie di clustering:più nodi di database che lavorano insieme per implementare la ridondanza:MySQL Cluster, Galera Cluster.
Tutto questo non va bene se hai tutto in un unico datacenter:quando un datacenter si interrompe, o parte dei servizi (ma quelli importanti) vanno offline, o anche se perdi la connettività al datacenter, il tuo servizio si interromperà - non importa la quantità di ridondanza nei livelli inferiori. E sì, quelle cose succedono.
- L'interruzione del servizio S3 ha provocato il caos nella regione USA-Est-1 a febbraio 2017
- Interruzione del servizio EC2 e RDS nella regione degli Stati Uniti orientali nell'aprile 2011
- EC2, EBS e RDS sono stati interrotti nella regione dell'UE occidentale nell'agosto 2011
- L'interruzione dell'alimentazione ha causato la caduta di Rackspace Texas DC nel giugno 2009
- Un guasto all'UPS ha causato la disconnessione di centinaia di server in Rackspace London DC nel gennaio 2010
Questo non è affatto un elenco completo di errori, è solo il risultato di una rapida ricerca su Google. Questi servono come esempi che le cose potrebbero e andranno male se metti tutte le uova nello stesso paniere. Un altro esempio potrebbe essere l'uragano Sandy, che ha causato un enorme esodo di dati dagli Stati Uniti orientali agli Stati Uniti occidentali DC - a quel tempo difficilmente si potevano creare istanze negli Stati Uniti occidentali poiché tutti si precipitavano a spostare la propria infrastruttura sull'altra costa in attesa che il North Virginia DC sarà gravemente influenzato dal tempo.
Pertanto, le configurazioni multi-datacenter sono indispensabili se si desidera creare un ambiente ad alta disponibilità. In questo post del blog, discuteremo di come costruire tale infrastruttura utilizzando Galera Cluster per MySQL/MariaDB.
Concetti di Galleria
Prima di esaminare soluzioni particolari, passiamo un po' di tempo a spiegare due concetti che sono molto importanti nelle configurazioni Galera multi-DC ad alta disponibilità.
Quorum
L'elevata disponibilità richiede risorse, ovvero è necessario un numero di nodi nel cluster per renderlo altamente disponibile. Un cluster può tollerare la perdita di alcuni dei suoi membri, ma solo in una certa misura. Al di là di un certo tasso di errore, potresti trovarti in uno scenario con il cervello diviso.
Facciamo un esempio con una configurazione a 2 nodi. Se uno dei nodi si interrompe, come può l'altro sapere che il suo peer si è bloccato e non si tratta di un errore di rete? In tal caso, l'altro nodo potrebbe anche essere attivo e funzionante e servire il traffico. Non esiste un buon modo per gestire un caso del genere... Questo è il motivo per cui la tolleranza agli errori di solito inizia da tre nodi. Galera utilizza un calcolo del quorum per determinare se è sicuro per il cluster gestire il traffico o se deve interrompere le operazioni. Dopo un errore, tutti i nodi rimanenti tentano di connettersi tra loro e determinano quanti di essi sono attivi. Viene quindi confrontato con lo stato precedente del cluster e, finché oltre il 50% dei nodi è attivo, il cluster può continuare a funzionare.
Ciò si traduce in:
cluster a 2 nodi:nessuna tolleranza agli errori
cluster a 3 nodi:fino a 1 arresto anomalo
cluster a 4 nodi:fino a 1 arresto anomalo (se due nodi si arrestano in modo anomalo, solo il 50% del cluster sarebbe disponibile, è necessario più del 50% dei nodi per sopravvivere)
cluster di 5 nodi - fino a 2 arresti anomali
cluster di 6 nodi - fino a 2 arresti anomali
Probabilmente vedrai lo schema:desideri che il tuo cluster abbia un numero dispari di nodi, in termini di alta disponibilità non ha senso passare da 5 a 6 nodi nel cluster. Se vuoi una migliore tolleranza agli errori, dovresti scegliere 7 nodi.
Segmenti
In genere, in un cluster Galera, tutte le comunicazioni seguono lo schema tutto a tutto. Ogni nodo comunica con tutti gli altri nodi del cluster.
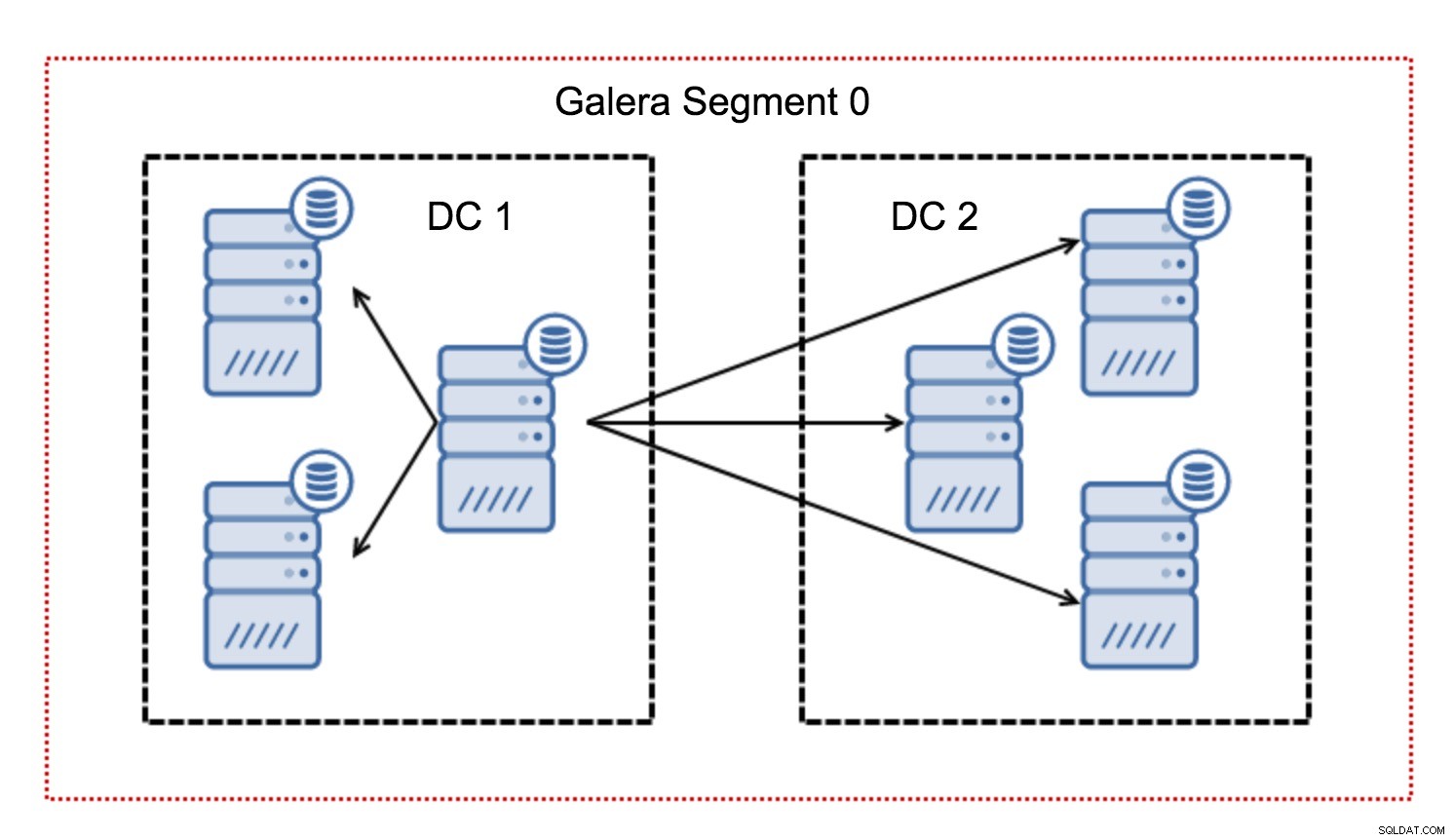
Come forse saprai, ogni writeset in Galera deve essere certificato da tutti i nodi del cluster, quindi ogni scrittura avvenuta su un nodo deve essere trasferita a tutti i nodi del cluster. Funziona bene in un ambiente a bassa latenza. Ma se parliamo di configurazioni multi-DC, dobbiamo considerare una latenza molto più elevata rispetto a una rete locale. Per renderlo più sopportabile nei cluster che si estendono su reti geografiche, Galera ha introdotto i segmenti.
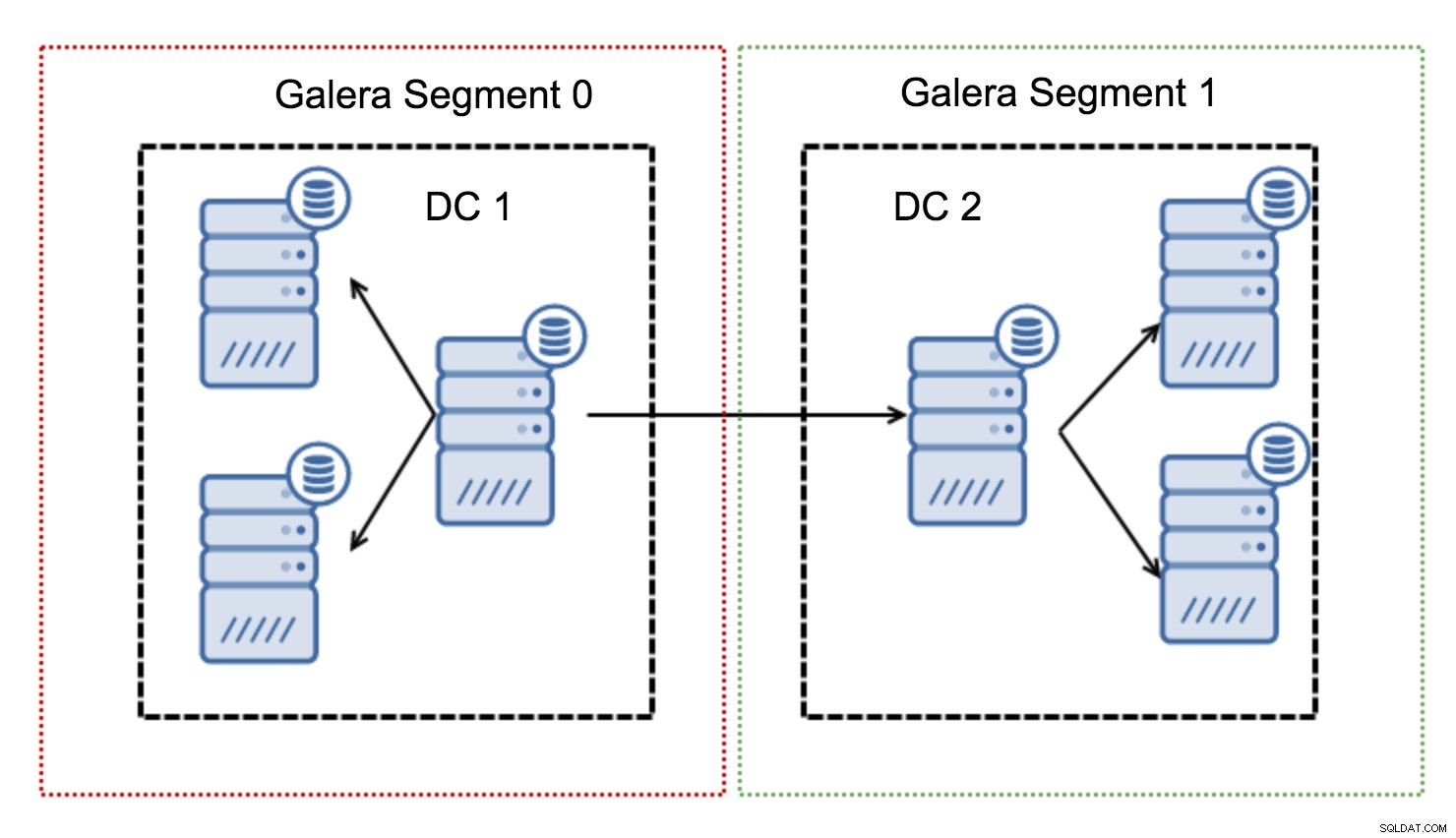
Funzionano contenendo il traffico Galera all'interno di un gruppo di nodi (segmento). Tutti i nodi all'interno di un singolo segmento agiscono come se fossero in una rete locale:presuppongono una comunicazione uno a tutti. Per il traffico cross-segment, le cose sono diverse:in ciascuno dei segmenti viene scelto un nodo "relè", tutto il traffico cross-segment passa attraverso quei nodi. Quando un nodo di inoltro si interrompe, viene eletto un altro nodo. Ciò non riduce di molto la latenza:dopotutto, la latenza WAN rimarrà la stessa indipendentemente dal fatto che si stabilisca una connessione a un host remoto o a più host remoti, ma dato che i collegamenti WAN tendono ad essere limitati nella larghezza di banda e potrebbe esserci un addebito per la quantità di dati trasferiti, tale approccio consente di limitare la quantità di dati scambiati tra i segmenti. Un'altra opzione per risparmiare tempo e denaro è il fatto che i nodi nello stesso segmento hanno la priorità quando è necessario un donatore:ancora una volta, ciò limita la quantità di dati trasferiti sulla WAN e, molto probabilmente, accelera quasi sempre l'SST come rete locale sarà più veloce di un collegamento WAN.
Ora che abbiamo eliminato alcuni di questi concetti, diamo un'occhiata ad altri aspetti importanti delle configurazioni multi-DC per il cluster Galera.
Problemi che stai per affrontare
Quando si lavora in ambienti che si estendono su WAN, ci sono un paio di problemi da tenere in considerazione durante la progettazione dell'ambiente.
Calcolo del quorum
Nella sezione precedente, abbiamo descritto come appare un calcolo del quorum nel cluster Galera:in breve, vuoi avere un numero dispari di nodi per massimizzare la sopravvivenza. Tutto ciò è ancora vero nelle configurazioni multi-DC, ma al mix vengono aggiunti altri elementi. Prima di tutto, devi decidere se vuoi che Galera gestisca automaticamente un errore del data center. Questo determinerà quanti data center utilizzerai. Immaginiamo due controller di dominio:se dividi i tuoi nodi dal 50% al 50%, se un data center si interrompe, il secondo non ha 50% + 1 nodi per mantenere il suo stato "primario". Se dividi i tuoi nodi in modo non uniforme, utilizzando la maggior parte di essi nel datacenter "principale", quando il datacenter si interrompe, il controller di dominio di "backup" non avrà 50% + 1 nodi per formare un quorum. Puoi assegnare pesi diversi ai nodi ma il risultato sarà esattamente lo stesso:non c'è modo di eseguire il failover automatico tra due controller di dominio senza intervento manuale. Per implementare il failover automatico, sono necessari più di due controller di dominio. Ancora una volta, idealmente un numero dispari:tre datacenter è una configurazione perfetta. Successivamente, la domanda è:quanti nodi devi avere? Si desidera che siano distribuiti uniformemente tra i data center. Il resto è solo una questione di quanti nodi falliti deve gestire la tua configurazione.
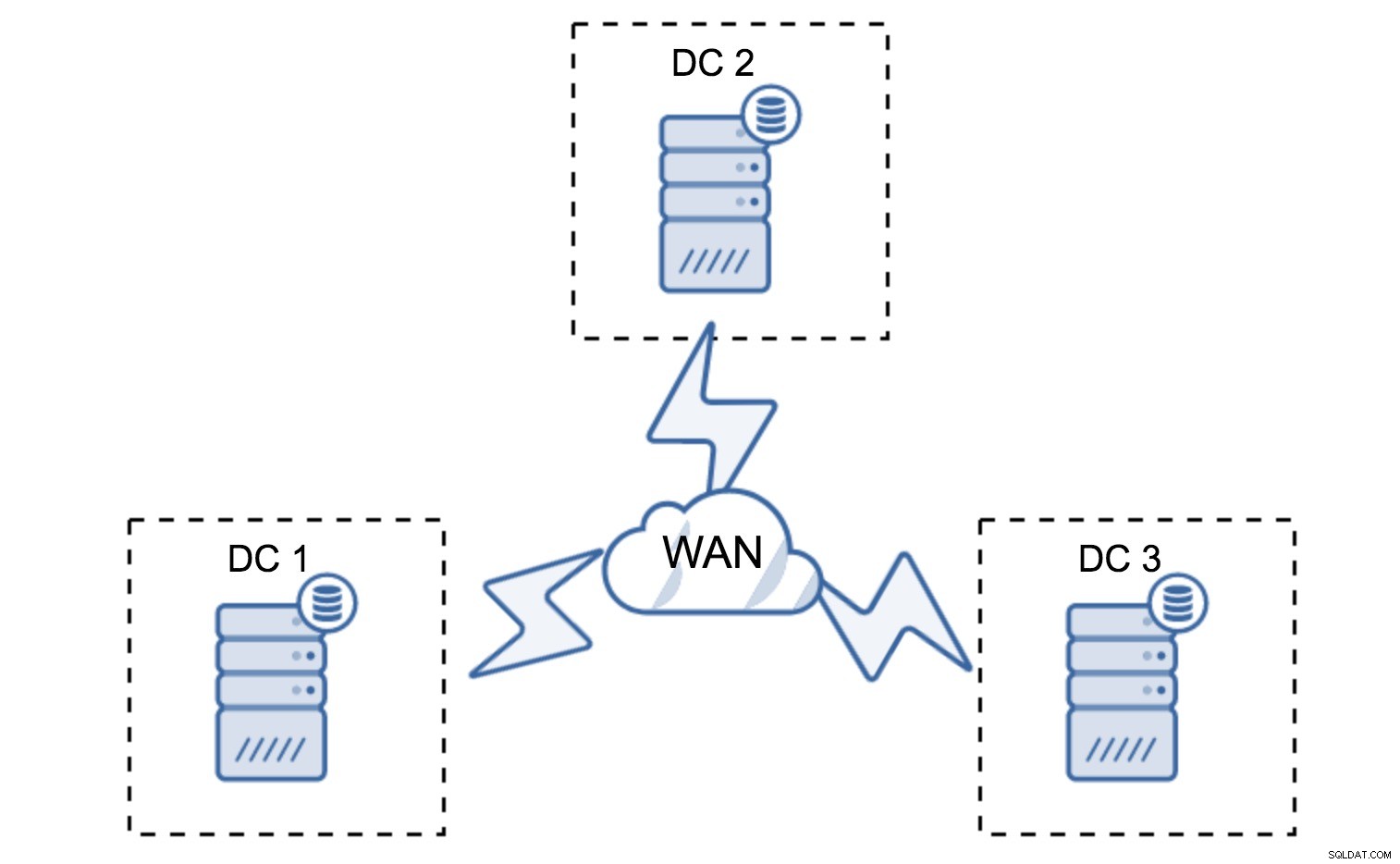
La configurazione minima utilizzerà un nodo per data center, tuttavia presenta seri inconvenienti. Ogni trasferimento di stato richiederà lo spostamento dei dati attraverso la WAN e ciò si tradurrà in un tempo più lungo necessario per completare l'SST o in costi più elevati.
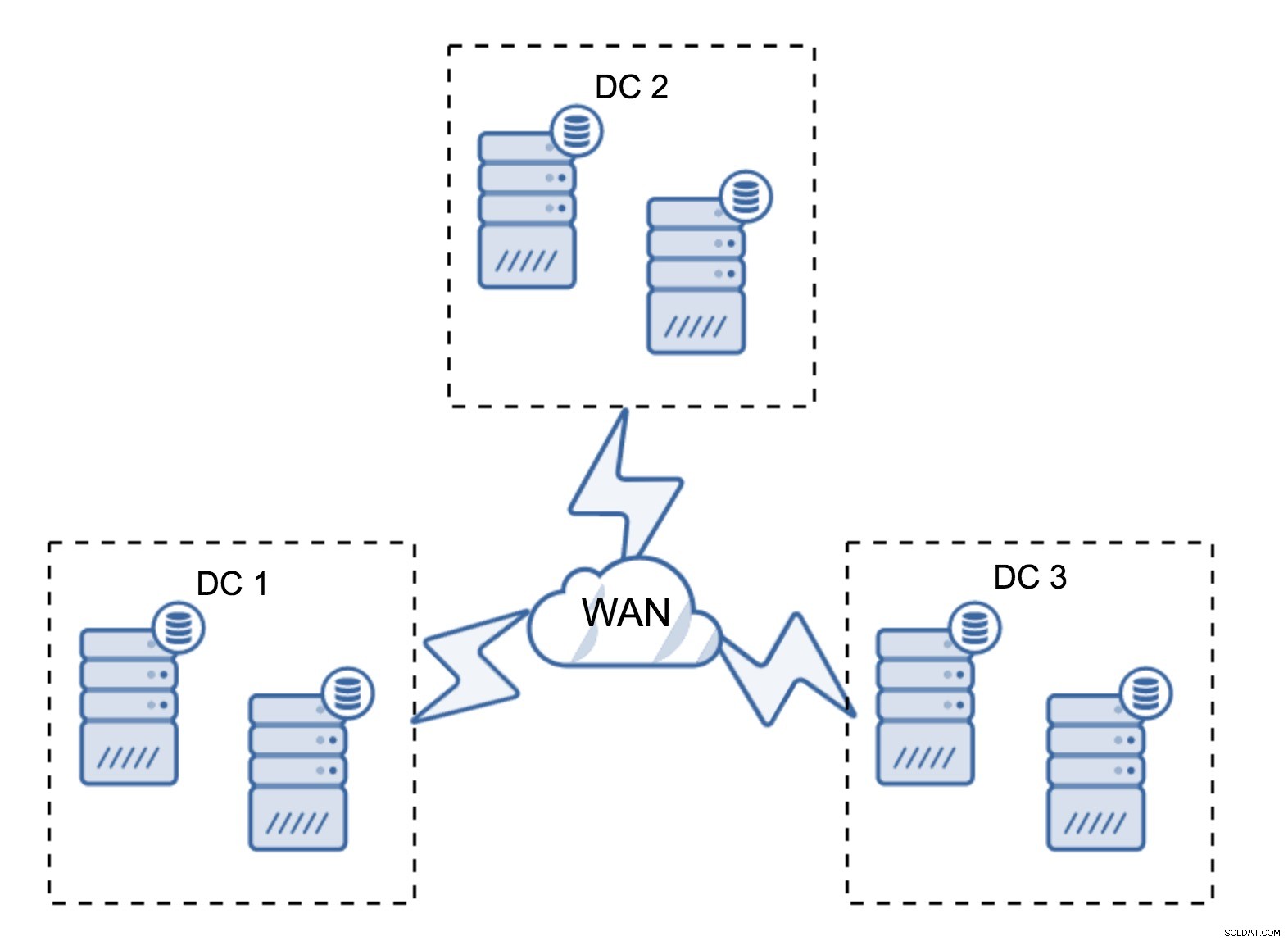
Una configurazione abbastanza tipica prevede sei nodi, due per data center. Questa configurazione sembra inaspettata in quanto ha un numero pari di nodi. Ma, a pensarci bene, potrebbe non essere un grosso problema:è abbastanza improbabile che tre nodi si interrompano contemporaneamente e una tale configurazione sopravviverà a un arresto anomalo di un massimo di due nodi. Un intero data center potrebbe andare offline e i due DC rimanenti continueranno a funzionare. Ha anche un enorme vantaggio rispetto alla configurazione minima:quando un nodo va offline, c'è sempre un secondo nodo nel datacenter che può fungere da donatore. La maggior parte delle volte, la WAN non verrà utilizzata per SST.
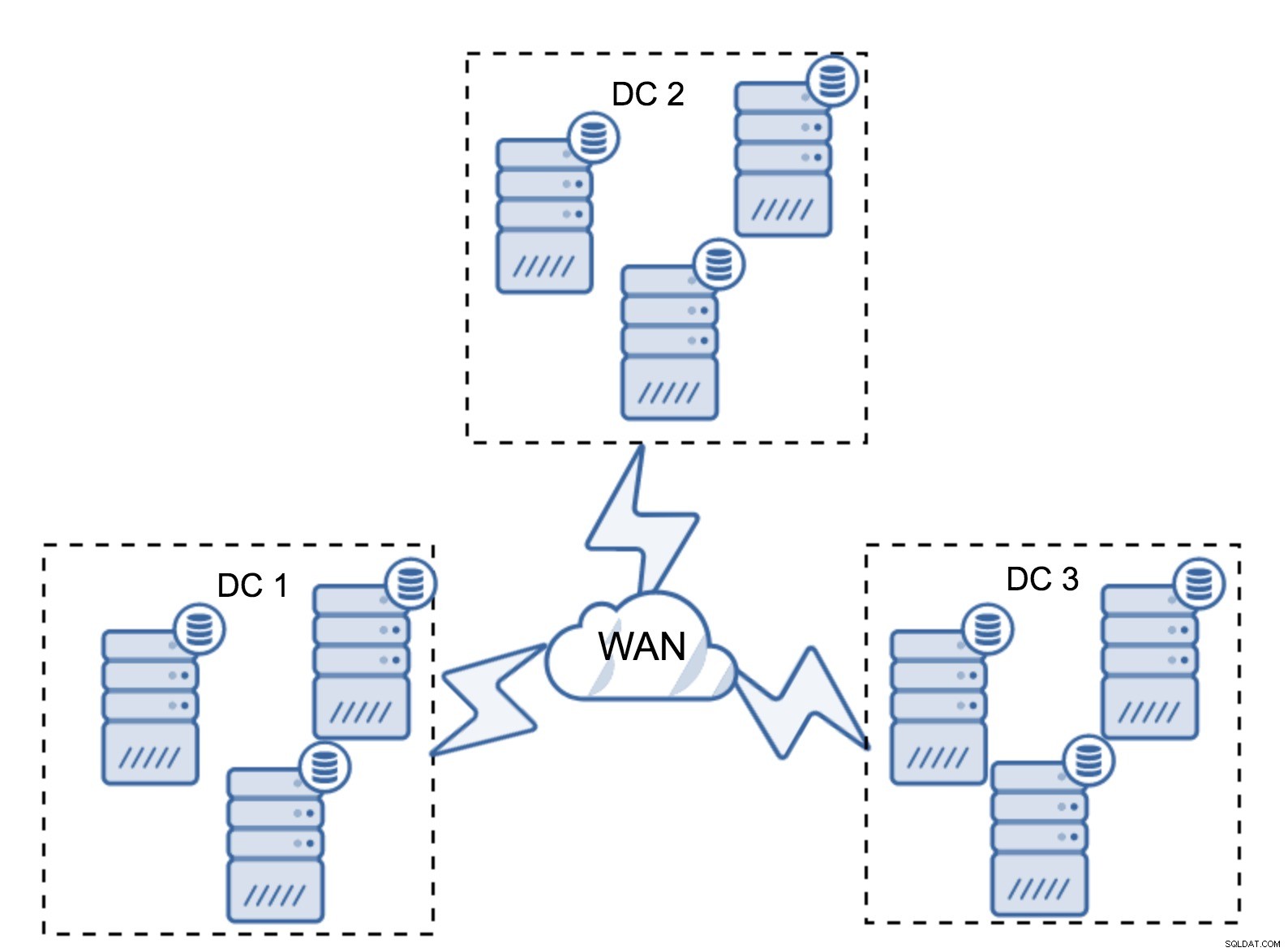
Naturalmente, puoi aumentare il numero di nodi a tre per cluster, nove in totale. Questo ti offre una sopravvivenza ancora migliore:fino a quattro nodi potrebbero bloccarsi e il cluster sopravviverà comunque. D'altra parte, devi tenere presente che, anche con l'uso di segmenti, più nodi significano un maggiore sovraccarico delle operazioni e puoi scalare il cluster Galera solo in una certa misura.
Può capitare che non ci sia bisogno di un terzo datacenter perché, diciamo, la tua applicazione si trova solo in due di essi. Naturalmente, il requisito di tre datacenter è ancora valido, quindi non lo si aggira, ma va benissimo usare un Galera Arbitrator (garbd) invece di server di database completamente caricati.
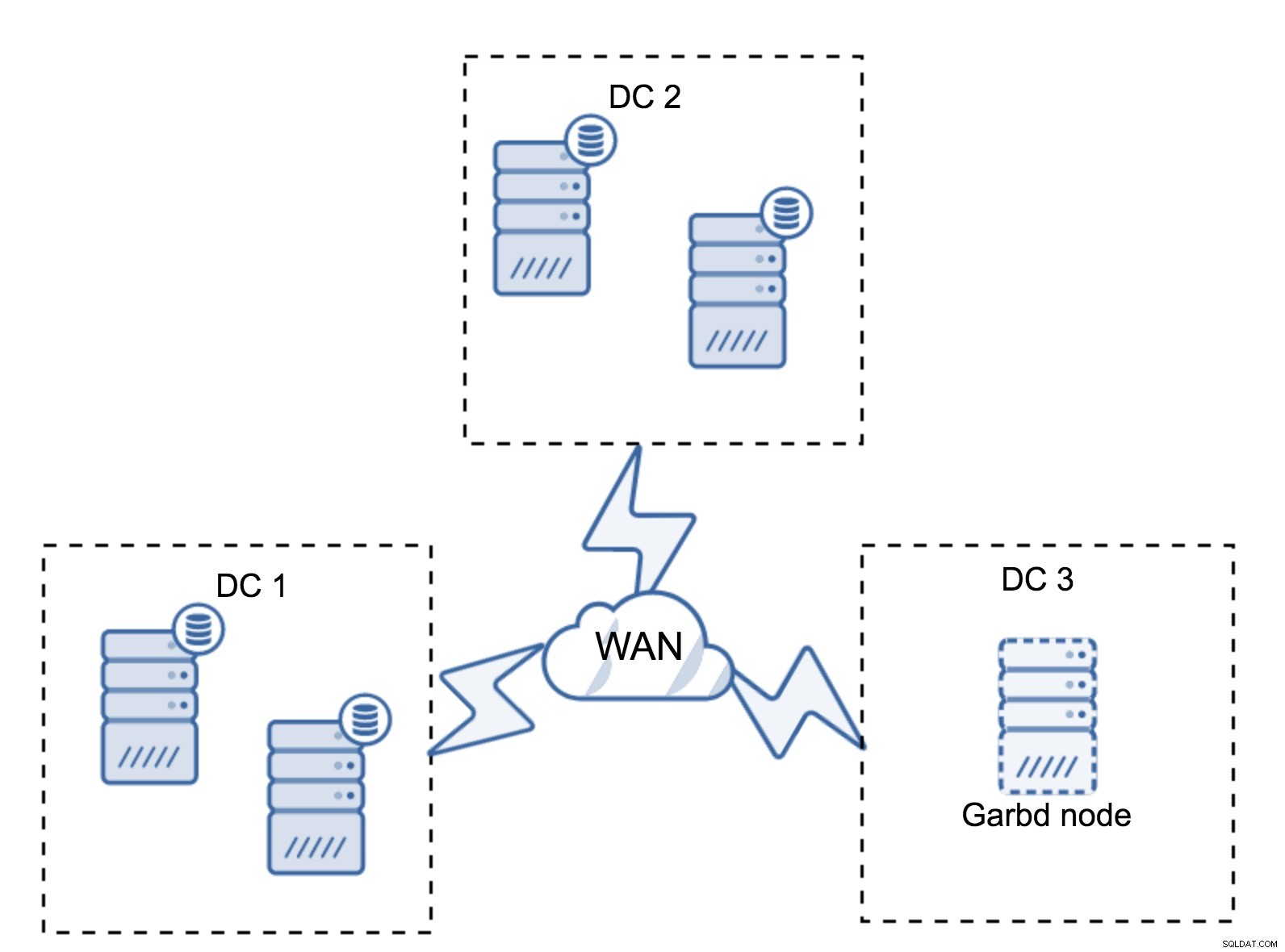
Garbd può essere installato su nodi più piccoli, anche su server virtuali. Non richiede hardware potente, non memorizza alcun dato né applica alcun writeset. Ma vede tutto il traffico di replica e prende parte al calcolo del quorum. Grazie ad esso, puoi distribuire configurazioni come quattro nodi, due per controller di dominio + garbd nel terzo:hai cinque nodi in totale e tale cluster può accettare fino a due errori. Quindi significa che può accettare lo spegnimento completo di uno dei data center.
Quale opzione è meglio per te? Non esiste una soluzione migliore per tutti i casi, tutto dipende dai requisiti della tua infrastruttura. Fortunatamente, ci sono diverse opzioni tra cui scegliere:più o meno nodi, 3 CC o 2 CC complete e vestirsi nella terza:è molto probabile che troverai qualcosa di adatto a te.
Latenza di rete
Quando si lavora con configurazioni multi-DC, è necessario tenere presente che la latenza di rete sarà notevolmente superiore a quella che ci si aspetterebbe da un ambiente di rete locale. Ciò può ridurre notevolmente le prestazioni del cluster Galera quando lo si confronta con un'istanza MySQL autonoma o una configurazione di replica MySQL. Il requisito che tutti i nodi debbano certificare un writeset significa che tutti i nodi devono riceverlo, non importa quanto siano lontani. Con la replica asincrona, non è necessario attendere prima di un commit. Naturalmente, la replica ha altri problemi e svantaggi, ma la latenza non è il principale. Il problema è particolarmente visibile quando il database ha punti caldi:righe che vengono aggiornate frequentemente (contatori, code, ecc.). Tali righe non possono essere aggiornate più di una volta per andata e ritorno della rete. Per i cluster sparsi in tutto il mondo, questo può facilmente significare che non sarai in grado di aggiornare una singola riga più spesso di 2 - 3 volte al secondo. Se questo diventa un limite per te, potrebbe significare che il cluster Galera non è adatto al tuo particolare carico di lavoro.
Livello proxy nel cluster Galera multi-DC
Non è sufficiente avere un cluster Galera che si estende su più data center, è comunque necessaria la tua applicazione per accedervi. Uno dei metodi più diffusi per nascondere la complessità del livello di database da un'applicazione consiste nell'utilizzare un proxy. I proxy vengono utilizzati come punto di ingresso ai database, tengono traccia dello stato dei nodi del database e devono sempre indirizzare il traffico solo ai nodi disponibili. In questa sezione, proveremo a proporre un progetto di livello proxy che potrebbe essere utilizzato per un cluster Galera multi-DC. Utilizzeremo ProxySQL, che ti offre un po' di flessibilità nella gestione dei nodi del database, ma puoi utilizzare un altro proxy, purché possa tracciare lo stato dei nodi Galera.
Dove trovare i proxy?
In breve, ci sono due modelli comuni qui:puoi distribuire ProxySQL su nodi separati oppure puoi distribuirli sugli host dell'applicazione. Diamo un'occhiata ai pro e ai contro di ciascuna di queste configurazioni.
Livello proxy come insieme separato di host
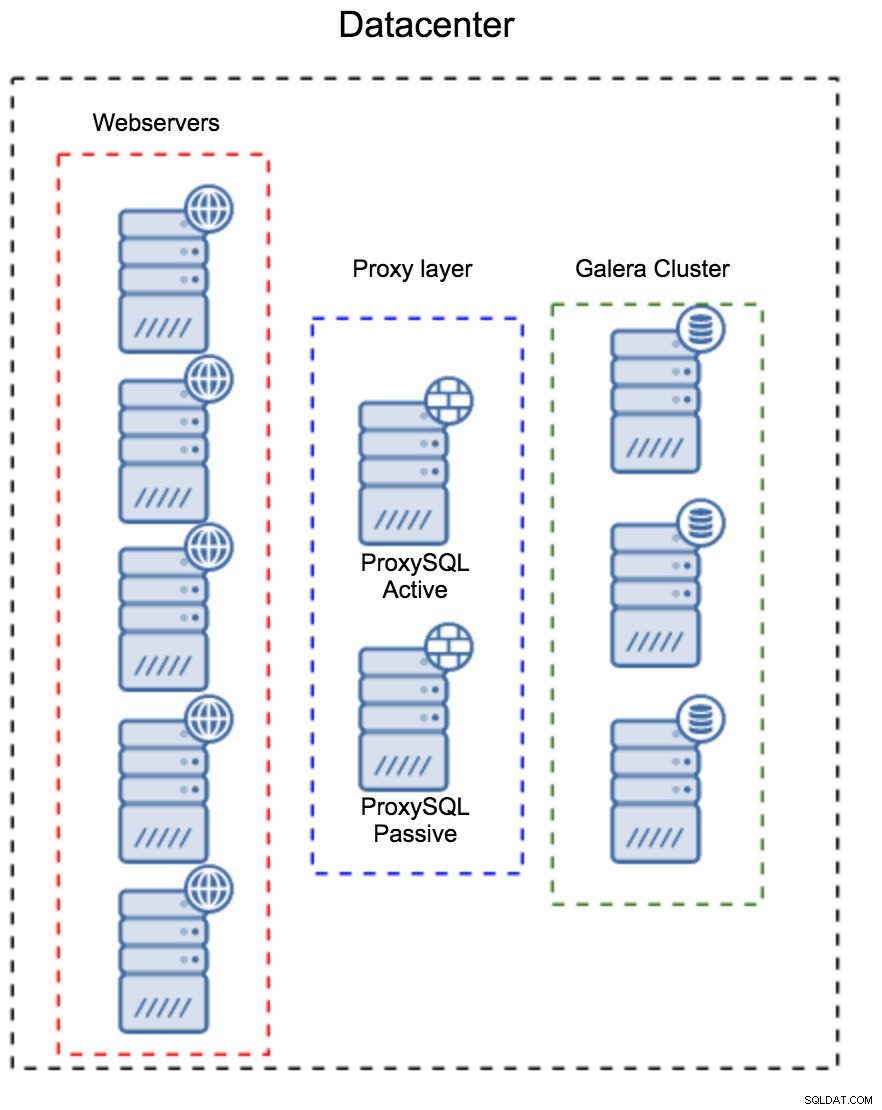
Il primo modello consiste nel creare un livello proxy utilizzando host dedicati separati. Puoi distribuire ProxySQL su un paio di host e utilizzare IP virtuale e keepalive per mantenere un'elevata disponibilità. Un'applicazione utilizzerà il VIP per connettersi al database e il VIP assicurerà che le richieste vengano sempre instradate a un ProxySQL disponibile. Il problema principale con questa configurazione è che si utilizza al massimo una delle istanze ProxySQL:tutti i nodi di standby non vengono utilizzati per instradare il traffico. Ciò potrebbe costringerti a utilizzare hardware più potente di quello che useresti normalmente. D'altra parte, è più facile mantenere l'installazione:dovrai applicare le modifiche alla configurazione su tutti i nodi ProxySQL, ma ce ne saranno solo una manciata. Puoi anche utilizzare l'opzione di ClusterControl per sincronizzare i nodi. Tale configurazione dovrà essere duplicata su ogni datacenter che utilizzi.
Proxy installato su istanze dell'applicazione
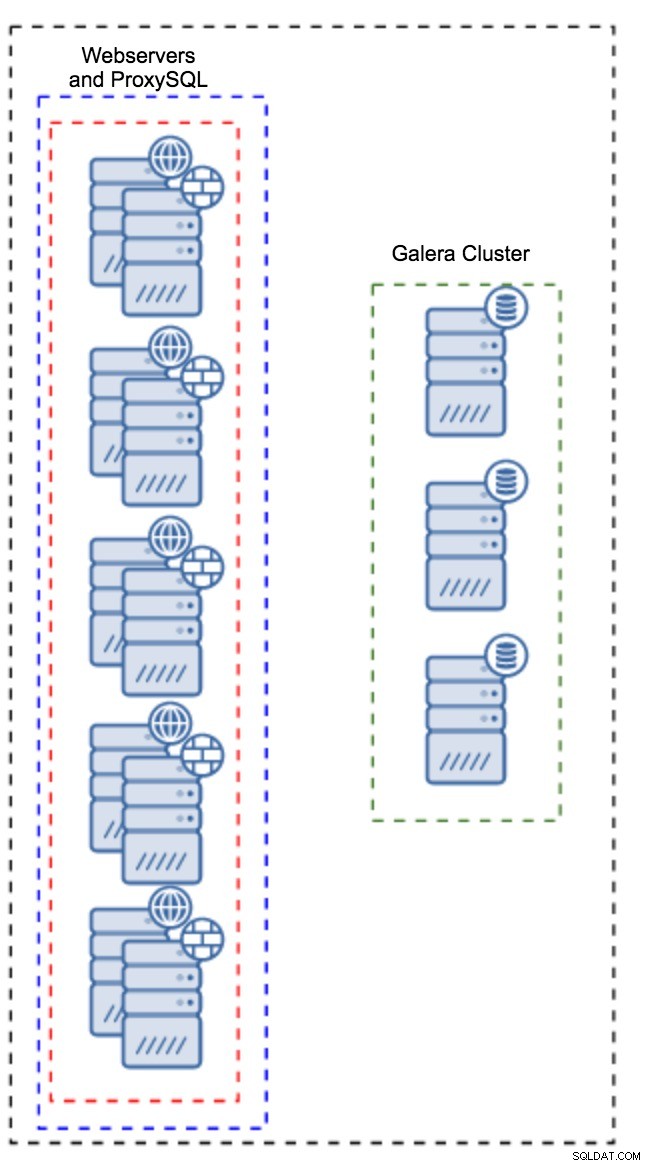
Invece di avere un set separato di host, ProxySQL può anche essere installato sugli host dell'applicazione. L'applicazione si connetterà direttamente a ProxySQL su localhost, potrebbe persino utilizzare unix socket per ridurre al minimo il sovraccarico della connessione TCP. Il vantaggio principale di tale configurazione è che si dispone di un numero elevato di istanze ProxySQL e il carico è distribuito uniformemente su di esse. Se uno va giù, solo quell'host dell'applicazione sarà interessato. I nodi rimanenti continueranno a funzionare. Il problema più serio da affrontare è la gestione della configurazione. Con un numero elevato di nodi ProxySQL, è fondamentale trovare un metodo automatizzato per mantenere sincronizzate le loro configurazioni. Potresti usare ClusterControl o uno strumento di gestione della configurazione come Puppet.
Ottimizzazione di Galera in un ambiente WAN
Le impostazioni predefinite di Galera sono progettate per la rete locale e se si desidera utilizzarlo in un ambiente WAN, sono necessarie alcune regolazioni. Discutiamo alcune delle modifiche di base che puoi apportare. Tieni presente che l'ottimizzazione precisa richiede dati di produzione e traffico:non puoi semplicemente apportare alcune modifiche e presumere che siano valide, dovresti eseguire un benchmarking adeguato.
Configurazione del sistema operativo
Iniziamo con la configurazione del sistema operativo. Non tutte le modifiche qui proposte sono relative alla WAN, ma è sempre bene ricordare a noi stessi qual è un buon punto di partenza per qualsiasi installazione di MySQL.
vm.swappiness = 1Swappiness controlla quanto aggressivo il sistema operativo utilizzerà lo swap. Non dovrebbe essere impostato su zero perché nei kernel più recenti impedisce al sistema operativo di utilizzare lo swap e potrebbe causare seri problemi di prestazioni.
/sys/block/*/queue/scheduler = deadline/noopLo scheduler per il dispositivo a blocchi, utilizzato da MySQL, dovrebbe essere impostato su scadenza o noop. La scelta esatta dipende dai benchmark, ma entrambe le impostazioni dovrebbero offrire prestazioni simili, migliori dello scheduler predefinito, CFQ.
Per MySQL, dovresti considerare l'utilizzo di EXT4 o XFS, a seconda del kernel (le prestazioni di quei filesystem cambiano da una versione del kernel all'altra). Esegui alcuni benchmark per trovare l'opzione migliore per te.
Oltre a questo, potresti voler esaminare le impostazioni di rete sysctl. Non li discuteremo in dettaglio (puoi trovare la documentazione qui) ma l'idea generale è aumentare i buffer, i backlog e i timeout, per rendere più facile adattarsi a stalli e collegamenti WAN instabili.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Oltre all'ottimizzazione del sistema operativo, dovresti considerare di modificare le impostazioni relative alla rete Galera.
evs.suspect_timeout
evs.inactive_timeoutPotresti prendere in considerazione la modifica dei valori predefiniti di queste variabili. Entrambi i timeout determinano il modo in cui il cluster rimuove i nodi non riusciti. Il timeout sospetto si verifica quando tutti i nodi non possono raggiungere il membro inattivo. Il timeout inattivo definisce un limite fisso di quanto tempo un nodo può rimanere nel cluster se non risponde. Di solito scoprirai che i valori predefiniti funzionano bene. Ma in alcuni casi, soprattutto se esegui il tuo cluster Galera su WAN (ad esempio, tra regioni AWS), l'aumento di tali variabili può comportare prestazioni più stabili. Suggeriamo di impostarli entrambi su PT1M, per ridurre le probabilità che l'instabilità del collegamento WAN elimini un nodo dal cluster.
evs.send_window
evs.user_send_windowQueste variabili, evs.send_window e evs.user_send_window , definire quanti pacchetti possono essere inviati tramite replica contemporaneamente (evs.send_window ) e quanti di essi possono contenere dati (evs.user_send_window ). Per connessioni ad alta latenza, potrebbe valere la pena aumentare questi valori in modo significativo (512 o 1024 ad esempio).
evs.inactive_check_periodLa variabile di cui sopra può anche essere modificata. evs.inactive_check_period , per impostazione predefinita, è impostato su un secondo, il che potrebbe essere troppo frequente per una configurazione WAN. Ti consigliamo di impostarlo su PT30S.
gcs.fc_factor
gcs.fc_limitQui vogliamo ridurre al minimo le possibilità che si attivi il controllo del flusso, quindi consigliamo di impostare gcs.fc_factor a 1 e aumentare gcs.fc_limit ad esempio, 260.
gcs.max_packet_sizePoiché stiamo lavorando con il collegamento WAN, dove la latenza è significativamente più alta, vogliamo aumentare le dimensioni dei pacchetti. Un buon punto di partenza sarebbe 2097152.
Come accennato in precedenza, è praticamente impossibile fornire una ricetta semplice su come impostare questi parametri poiché dipende da troppi fattori:dovrai eseguire i tuoi benchmark, utilizzando dati il più vicino possibile ai tuoi dati di produzione, prima di può dire che il tuo sistema è sintonizzato. Detto questo, queste impostazioni dovrebbero darti un punto di partenza per l'accordatura più precisa.
Per ora è tutto. Galera funziona abbastanza bene in ambienti WAN, quindi provalo e facci sapere come ti trovi.