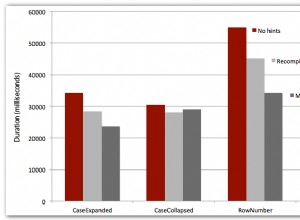
TL;DR
È il NULL sicuro uguale
operatore.
Come il normale = operatore, vengono confrontati due valori e il risultato è 0 (non uguale) o 1 (pari); in altre parole:'a' <=> 'b' restituisce 0 e 'a' <=> 'a' restituisce 1 .
A differenza del normale = operatore, valori di NULL non hanno un significato speciale e quindi non restituisce mai NULL come possibile risultato; quindi:'a' <=> NULL restituisce 0 e NULL <=> NULL restituisce 1 .
Utilità
Questo può tornare utile quando entrambi gli operandi possono contenere NULL e hai bisogno di un risultato di confronto coerente tra due colonne.
Un altro caso d'uso è con le istruzioni preparate, ad esempio:
... WHERE col_a <=> ? ...
Qui, il segnaposto può essere un valore scalare o NULL senza dover modificare nulla della query.
Operatori correlati
Oltre a <=> ci sono anche altri due operatori che possono essere usati per confrontare NULL , ovvero IS NULL e IS NOT NULL; fanno parte dello standard ANSI e quindi sono supportati su altri database, a differenza di <=> , che è specifico per MySQL.
Puoi pensarli come specializzazioni di <=> di MySQL :
'a' IS NULL ==> 'a' <=> NULL
'a' IS NOT NULL ==> NOT('a' <=> NULL)
Sulla base di ciò, la tua particolare query (frammento) può essere convertita nella più portabile:
WHERE p.name IS NULL
Supporto
Lo standard SQL:2003 ha introdotto un predicato per questo, che funziona esattamente come <=> di MySQL operatore, nella forma seguente:
IS [NOT] DISTINCT FROM
Quanto segue è universalmente supportato, ma è relativamente complesso:
CASE WHEN (a = b) or (a IS NULL AND b IS NULL)
THEN 1
ELSE 0
END = 1