Python e SQL sono due dei linguaggi più importanti per gli analisti di dati.
In questo articolo ti guiderò attraverso tutto ciò che devi sapere per connettere Python e SQL.
Imparerai come estrarre i dati dai database relazionali direttamente nelle tue pipeline di machine learning, archiviare i dati dalla tua applicazione Python in un database tutto tuo o qualsiasi altro caso d'uso che potresti inventare.
Insieme tratteremo:
- Perché imparare a usare Python e SQL insieme?
- Come configurare il tuo ambiente Python e MySQL Server
- Connessione a MySQL Server in Python
- Creazione di un nuovo database
- Creazione di tabelle e relazioni tra tabelle
- Popolare le tabelle con i dati
- Lettura dei dati
- Aggiornamento dei record
- Eliminazione dei record
- Creazione di record da elenchi Python
- Creazione di funzioni riutilizzabili per fare tutto questo per noi in futuro
Sono un sacco di cose molto utili e molto interessanti. Entriamo!
Una breve nota prima di iniziare:c'è un Jupyter Notebook contenente tutto il codice utilizzato in questo tutorial disponibile in questo repository GitHub. Codificare insieme è altamente raccomandato!
Il database e il codice SQL utilizzati qui sono tutti dalla mia precedente serie Introduzione a SQL pubblicata su Towards Data Science (contattami se hai problemi a visualizzare gli articoli e posso inviarti un link per vederli gratuitamente).
Se non hai familiarità con SQL e i concetti alla base dei database relazionali, ti indirizzerei verso quella serie (in più c'è ovviamente un'enorme quantità di cose fantastiche disponibili qui su freeCodeCamp!)
Perché Python con SQL?
Per analisti di dati e scienziati di dati, Python presenta molti vantaggi. Una vasta gamma di librerie open source lo rendono uno strumento incredibilmente utile per qualsiasi analista di dati.
Abbiamo panda, NumPy e Vaex per l'analisi dei dati, Matplotlib, seaborn e Bokeh per la visualizzazione e TensorFlow, scikit-learn e PyTorch per applicazioni di apprendimento automatico (oltre a molte, molte altre).
Con la sua curva di apprendimento (relativamente) facile e la sua versatilità, non sorprende che Python sia uno dei linguaggi di programmazione in più rapida crescita.
Quindi, se stiamo usando Python per l'analisi dei dati, vale la pena chiedersi:da dove provengono tutti questi dati?
Sebbene esista un'enorme varietà di origini per i set di dati, in molti casi, in particolare nelle aziende aziendali, i dati verranno archiviati in un database relazionale. I database relazionali sono un modo estremamente efficiente, potente e ampiamente utilizzato per creare, leggere, aggiornare ed eliminare dati di ogni tipo.
I sistemi di gestione di database relazionali (RDBMS) più utilizzati - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - utilizzano tutti lo Structured Query Language (SQL) per accedere e apportare modifiche ai dati.
Si noti che ogni RDBMS utilizza un tipo di SQL leggermente diverso, quindi il codice SQL scritto per uno di solito non funzionerà in un altro senza modifiche (normalmente piuttosto minori). Ma i concetti, le strutture e le operazioni sono in gran parte identici.
Ciò significa che per un Data Analyst che lavora, una profonda comprensione di SQL è estremamente importante. Sapere come usare Python e SQL insieme ti darà un vantaggio ancora maggiore quando si tratta di lavorare con i tuoi dati.
Il resto di questo articolo sarà dedicato a mostrarti esattamente come possiamo farlo.
Per iniziare
Requisiti e installazione
Per programmare insieme a questo tutorial, avrai bisogno del tuo ambiente Python configurato.
Uso Anaconda, ma ci sono molti modi per farlo. Cerca su Google "come installare Python" se hai bisogno di ulteriore aiuto. Puoi anche utilizzare Raccoglitore per codificare insieme al notebook Jupyter associato.
Utilizzeremo MySQL Community Server poiché è gratuito e ampiamente utilizzato nel settore. Se utilizzi Windows, questa guida ti aiuterà a configurare. Ecco le guide anche per utenti Mac e Linux (sebbene possa variare in base alla distribuzione Linux).
Una volta impostati, dovremo farli comunicare tra loro.
Per questo, abbiamo bisogno di installare la libreria Python di MySQL Connector. Per fare ciò, segui le istruzioni o usa semplicemente pip:
pip install mysql-connector-pythonUtilizzeremo anche i panda, quindi assicurati di aver installato anche quello.
pip install pandasImportazione di librerie
Come per ogni progetto in Python, la prima cosa che vogliamo fare è importare le nostre librerie.
È buona norma importare tutte le librerie che utilizzeremo all'inizio del progetto, in modo che le persone che leggono o rivedono il nostro codice sappiano più o meno cosa sta succedendo, quindi non ci sono sorprese.
Per questo tutorial, utilizzeremo solo due librerie:MySQL Connector e Pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdImportiamo la funzione Error separatamente in modo da potervi accedere facilmente per le nostre funzioni.
Connessione al server MySQL
A questo punto dovremmo avere MySQL Community Server configurato sul nostro sistema. Ora abbiamo bisogno di scrivere del codice in Python che ci permetta di stabilire una connessione a quel server.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionLa creazione di una funzione riutilizzabile per codice come questa è una procedura consigliata, in modo da poterla utilizzare ancora e ancora con il minimo sforzo. Una volta che questo è stato scritto, potrai riutilizzarlo in tutti i tuoi progetti anche in futuro, quindi futuro, te ne sarai grato!
Esaminiamo questa riga per riga in modo da capire cosa sta succedendo qui:
La prima riga è la denominazione della funzione (create_server_connection) e la denominazione degli argomenti che la funzione prenderà (nome_host, nome_utente e password_utente).
La riga successiva chiude tutte le connessioni esistenti in modo che il server non venga confuso con più connessioni aperte.
Successivamente utilizziamo un blocco try-except di Python per gestire eventuali errori. La prima parte tenta di creare una connessione al server utilizzando il metodo mysql.connector.connect() utilizzando i dettagli specificati dall'utente negli argomenti. Se funziona, la funzione stampa un messaggio di piccolo successo felice.
La parte eccetto del blocco stampa l'errore che MySQL Server restituisce, nella sfortunata circostanza che c'è un errore.
Infine, se la connessione riesce, la funzione restituisce un oggetto di connessione.
Lo utilizziamo in pratica assegnando l'output della funzione a una variabile, che diventa quindi il nostro oggetto di connessione. Possiamo quindi applicarvi altri metodi (come il cursore) e creare altri oggetti utili.
connection = create_server_connection("localhost", "root", pw)Questo dovrebbe produrre un messaggio di successo:

Creazione di un nuovo database
Ora che abbiamo stabilito una connessione, il nostro prossimo passo è creare un nuovo database sul nostro server.
In questo tutorial lo faremo solo una volta, ma ancora lo scriveremo come una funzione riutilizzabile in modo da avere una bella funzione utile che possiamo riutilizzare per progetti futuri.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Questa funzione accetta due argomenti, connection (il nostro oggetto di connessione) e query (una query SQL che scriveremo nel passaggio successivo). Esegue la query nel server tramite la connessione.
Usiamo il metodo del cursore sul nostro oggetto di connessione per creare un oggetto cursore (MySQL Connector utilizza un paradigma di programmazione orientato agli oggetti, quindi ci sono molti oggetti che ereditano proprietà dagli oggetti padre).
Questo oggetto cursore ha metodi come execute, executemany (che useremo in questo tutorial) insieme a molti altri metodi utili.
Se può essere d'aiuto, possiamo pensare che l'oggetto cursore ci fornisca l'accesso al cursore lampeggiante in una finestra del terminale di un server MySQL.
Quindi definiamo una query per creare il database e chiamiamo la funzione:

Tutte le query SQL utilizzate in questo tutorial sono spiegate nella mia serie di tutorial Introduzione a SQL e il codice completo può essere trovato nel notebook Jupyter associato in questo repository GitHub, quindi non fornirò spiegazioni su ciò che fa il codice SQL in questo esercitazione.
Questa è forse la query SQL più semplice possibile, però. Se sai leggere l'inglese, probabilmente puoi capire cosa fa!
L'esecuzione della funzione create_database con gli argomenti di cui sopra comporta la creazione di un database chiamato "scuola" nel nostro server.
Perché il nostro database si chiama "scuola"? Forse ora sarebbe un buon momento per esaminare più in dettaglio esattamente ciò che implementeremo in questo tutorial.
Il nostro database
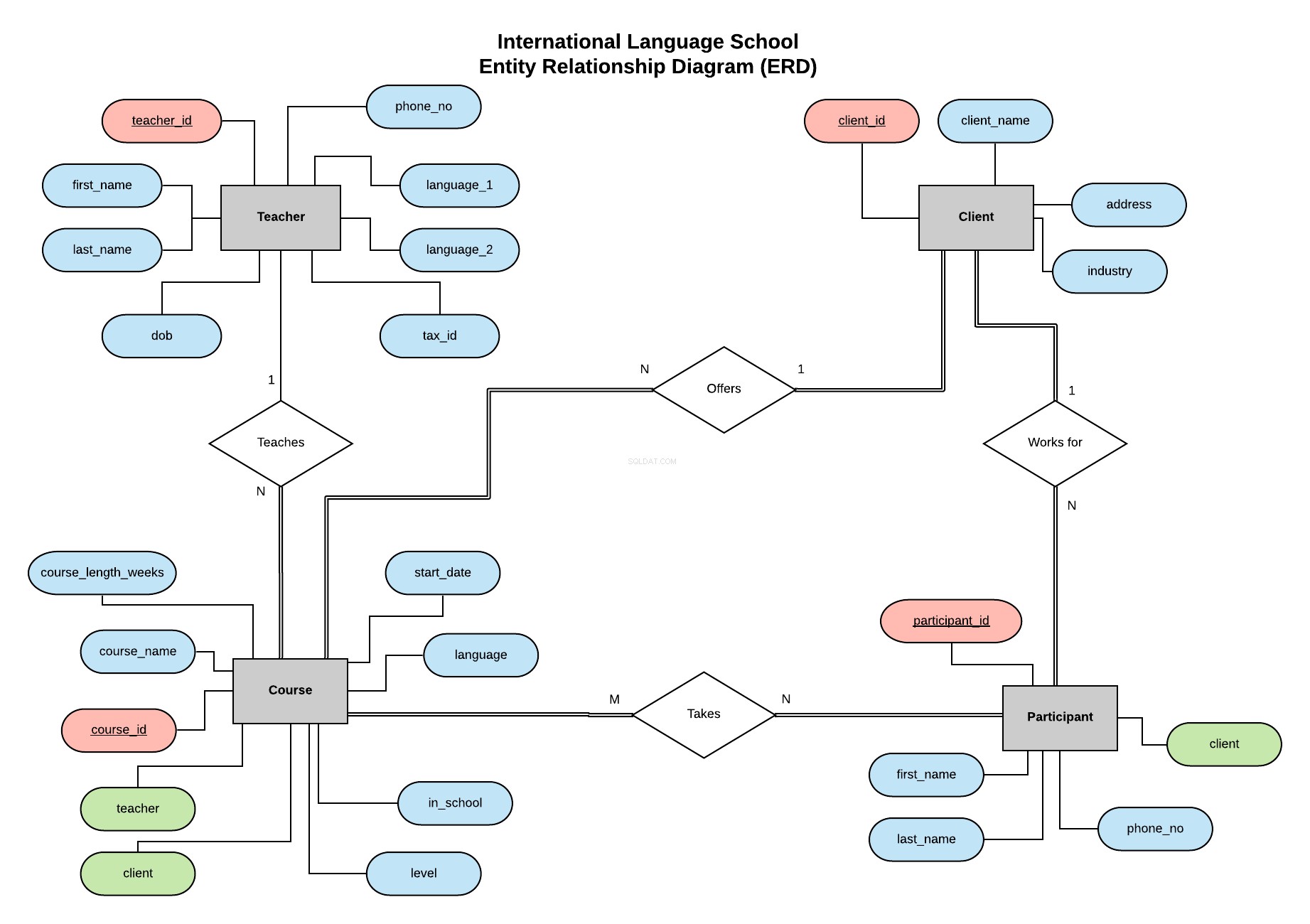
Seguendo l'esempio della mia serie precedente, implementeremo il database per la International Language School, una scuola di formazione linguistica immaginaria che offre lezioni di lingua professionale a clienti aziendali.
Questo diagramma di relazione tra entità (ERD) illustra le nostre entità (insegnante, cliente, corso e partecipante) e definisce le relazioni tra di loro.
Tutte le informazioni su cos'è un ERD e cosa considerare durante la creazione e la progettazione di un database sono disponibili in questo articolo.
Il codice SQL grezzo, i requisiti del database e i dati da inserire nel database sono tutti contenuti in questo repository GitHub, ma lo vedrai anche durante questo tutorial.
Connessione al database
Ora che abbiamo creato un database in MySQL Server, possiamo modificare la nostra funzione create_server_connection per connetterci direttamente a questo database.
Tieni presente che è possibile - comune, infatti - avere più database su un server MySQL, quindi vogliamo connetterci sempre e automaticamente al database che ci interessa.
Possiamo farlo in questo modo:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionQuesta è esattamente la stessa funzione, ma ora prendiamo un altro argomento, il nome del database, e lo passiamo come argomento al metodo connect().
Creazione di una funzione di esecuzione di query
La funzione finale che creeremo (per ora) è estremamente vitale:una funzione di esecuzione di query. Questo prenderà le nostre query SQL, memorizzate in Python come stringhe, e le passerà al metodo cursor.execute() per eseguirle sul server.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Questa funzione è esattamente la stessa della nostra funzione create_database di prima, tranne per il fatto che utilizza il metodo connection.commit() per assicurarsi che i comandi dettagliati nelle nostre query SQL siano implementati.
Questa sarà la nostra funzione di cavallo di battaglia, che useremo (insieme a create_db_connection) per creare tabelle, stabilire relazioni tra quelle tabelle, popolare le tabelle con dati e aggiornare ed eliminare i record nel nostro database.
Se sei un esperto di SQL, questa funzione ti consentirà di eseguire tutti i comandi e le query complessi che potresti avere in giro, direttamente da uno script Python. Questo può essere uno strumento molto potente per la gestione dei tuoi dati.
Creazione di tabelle
Ora siamo pronti per iniziare a eseguire i comandi SQL nel nostro server e per iniziare a costruire il nostro database. La prima cosa che vogliamo fare è creare le tabelle necessarie.
Iniziamo con il nostro tavolo Insegnante:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryPer prima cosa assegniamo il nostro comando SQL (spiegato in dettaglio qui) ad una variabile con un nome appropriato.
In questo caso utilizziamo la notazione a virgolette triple di Python per le stringhe multiriga per memorizzare la nostra query SQL, quindi la inseriamo nella nostra funzione execute_query per implementarla.
Si noti che questa formattazione su più righe è puramente a beneficio degli esseri umani che leggono il nostro codice. Né SQL né Python "si preoccupano" se il comando SQL è distribuito in questo modo. Finché la sintassi è corretta, entrambe le lingue la accetteranno.
A beneficio degli esseri umani che leggeranno il tuo codice, tuttavia, (anche se quello sarà solo il tuo futuro!) è molto utile farlo per rendere il codice più leggibile e comprensibile.
Lo stesso vale per la MAIUSCOLA degli operatori in SQL. Questa è una convenzione ampiamente utilizzata che è fortemente raccomandata, ma il software effettivo che esegue il codice non fa distinzione tra maiuscole e minuscole e tratterà "CREA TABELLA insegnante" e "Crea tavolo insegnante" come comandi identici.

L'esecuzione di questo codice ci fornisce i nostri messaggi di successo. Possiamo anche verificarlo nel client della riga di comando di MySQL Server:
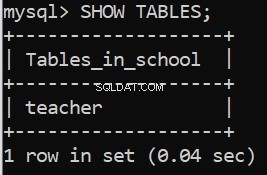
Grande! Ora creiamo le restanti tabelle.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Questo crea le quattro tabelle necessarie per le nostre quattro entità.
Ora vogliamo definire le relazioni tra di loro e creare un'altra tabella per gestire la relazione molti-a-molti tra il partecipante e le tabelle del corso (vedi qui per maggiori dettagli).
Lo facciamo esattamente allo stesso modo:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Ora vengono create le nostre tabelle, insieme ai vincoli appropriati, alla chiave primaria e alle relazioni di chiave esterna.
Popolare le tabelle
Il passaggio successivo consiste nell'aggiungere alcuni record alle tabelle. Ancora una volta utilizziamo execute_query per alimentare i nostri comandi SQL esistenti nel server. Ricominciamo con la tabella Insegnante.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)funziona? Possiamo ricontrollare nel nostro client MySQL Command Line:
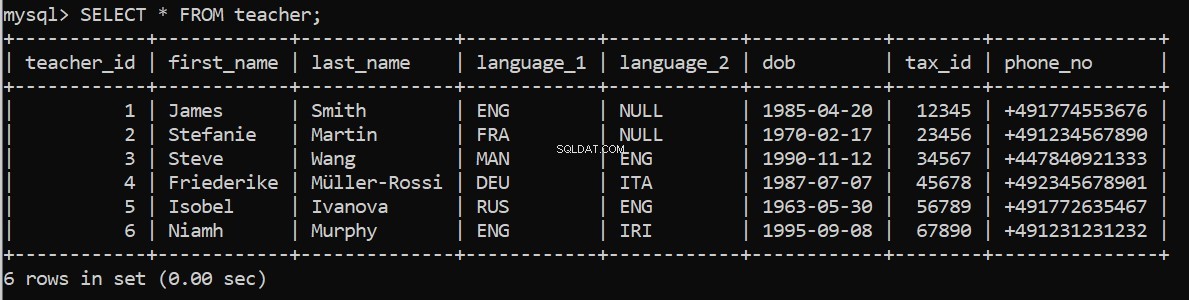
Ora per popolare le restanti tabelle.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Sorprendente! Ora abbiamo creato un database completo di relazioni, vincoli e record in MySQL, utilizzando nient'altro che comandi Python.
Abbiamo esaminato questo passo dopo passo per renderlo comprensibile. Ma a questo punto puoi vedere che tutto questo potrebbe essere scritto molto facilmente in uno script Python ed eseguito in un comando nel terminale. Roba potente.
Lettura dei dati
Ora abbiamo un database funzionale con cui lavorare. In qualità di Data Analyst, è probabile che entri in contatto con i database esistenti nelle organizzazioni in cui lavori. Sarà molto utile sapere come estrarre i dati da quei database in modo che possano essere inseriti nella pipeline di dati Python. Questo è ciò su cui lavoreremo dopo.
Per questo, avremo bisogno di un'altra funzione, questa volta usando cursor.fetchall() invece di cursor.commit(). Con questa funzione, leggiamo i dati dal database e non apporteremo modifiche.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Ancora una volta, lo implementeremo in un modo molto simile a execute_query. Proviamolo con una semplice query per vedere come funziona.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)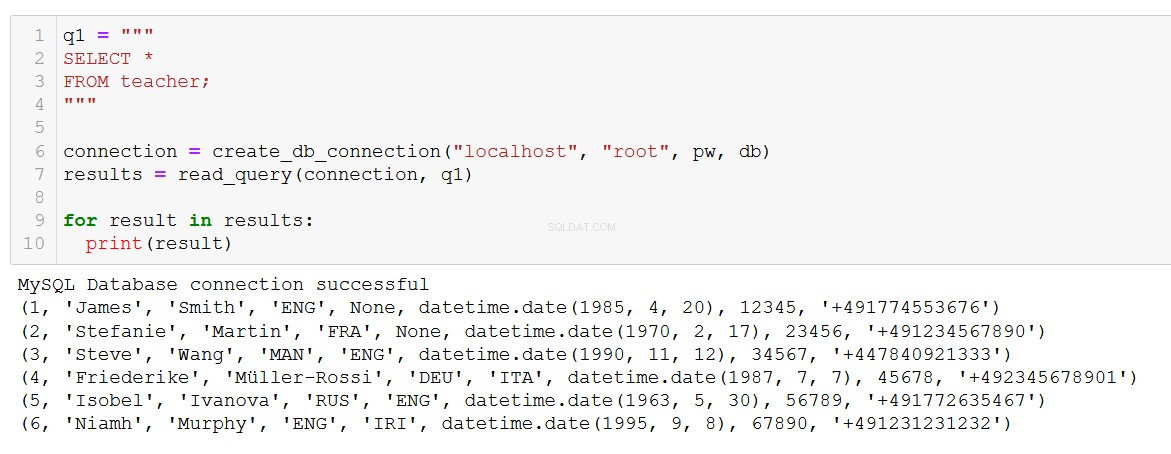
Esattamente quello che ci aspettiamo. La funzione funziona anche con query più complesse, come questa che coinvolge un JOIN sul corso e tabelle client.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)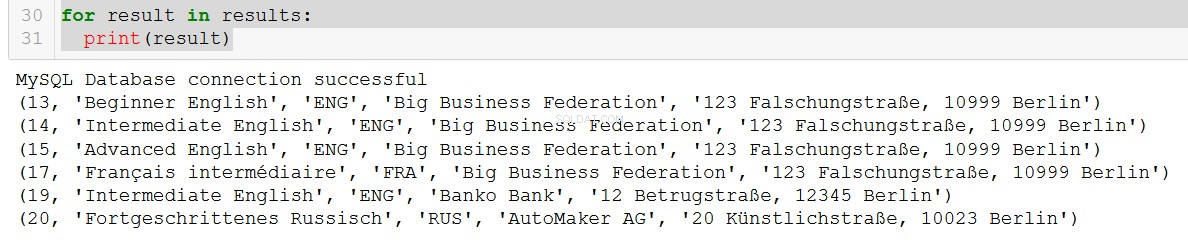
Molto bello.
Per le nostre pipeline di dati e flussi di lavoro in Python, potremmo voler ottenere questi risultati in formati diversi per renderli più utili o pronti per la manipolazione.
Esaminiamo un paio di esempi per vedere come possiamo farlo.
Formattazione dell'output in un elenco
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formattazione dell'output in un elenco di elenchi
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formattazione dell'output in un DataFrame panda
Per gli analisti di dati che utilizzano Python, i panda sono i nostri vecchi amici belli e fidati. È molto semplice convertire l'output del nostro database in un DataFrame e da lì le possibilità sono infinite!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)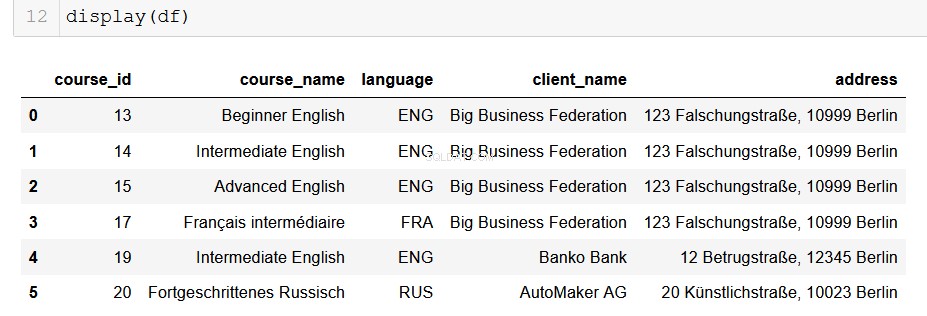
Spero che tu possa vedere le possibilità che si aprono di fronte a te qui. Con poche righe di codice, possiamo estrarre facilmente tutti i dati che possiamo gestire dai database relazionali in cui risiedono e inserirli nelle nostre pipeline di analisi dei dati all'avanguardia. Questa è roba davvero utile.
Aggiornamento dei record
Durante la manutenzione di un database, a volte sarà necessario apportare modifiche ai record esistenti. In questa sezione vedremo come farlo.
Diciamo che l'ILS è stata informata che uno dei suoi clienti esistenti, la Big Business Federation, sta trasferendo gli uffici a 23 Fingiertweg, 14534 Berlino. In questo caso, l'amministratore del database (siamo noi!) dovrà apportare alcune modifiche.
Per fortuna, possiamo farlo con la nostra funzione execute_query insieme all'istruzione SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Si noti che la clausola WHERE è molto importante qui. Se eseguiamo questa query senza la clausola WHERE, tutti gli indirizzi per tutti i record nella nostra tabella Client verrebbero aggiornati a 23 Fingiertweg. Non è proprio quello che stiamo cercando di fare.
Nota inoltre che abbiamo utilizzato "WHERE client_id =101" nella query UPDATE. Sarebbe stato anche possibile utilizzare "WHERE client_name ='Big Business Federation'" o "WHERE address ='123 Falschungstraße, 10999 Berlin'" o anche "WHERE address LIKE '%Falschung%'".
L'importante è che la clausola WHERE ci consenta di identificare in modo univoco il record (o i record) che vogliamo aggiornare.
Eliminazione dei record
È anche possibile utilizzare la nostra funzione execute_query per eliminare i record, utilizzando DELETE.
Quando si utilizza SQL con database relazionali, è necessario prestare attenzione utilizzando l'operatore DELETE. Questo non è Windows, non c'è "Sei sicuro di voler eliminare questo?" pop-up di avviso e non c'è un cestino per il riciclaggio. Una volta che eliminiamo qualcosa, non c'è più.
Detto questo, a volte abbiamo davvero bisogno di eliminare le cose. Quindi diamo un'occhiata eliminando un corso dalla nostra tabella dei corsi.
Prima di tutto ricordiamoci di quali corsi abbiamo.
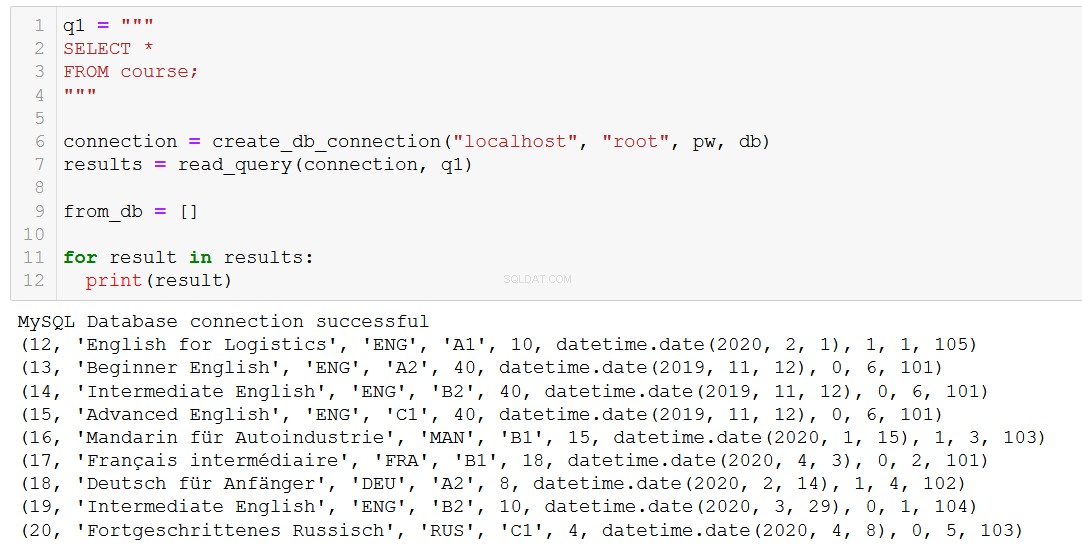
Diciamo che il corso 20, "Fortgeschrittenes Russisch" (che è "Russo avanzato" per te e me), sta volgendo al termine, quindi dobbiamo rimuoverlo dal nostro database.
A questo punto, non sarai affatto sorpreso da come lo facciamo:salva il comando SQL come stringa, quindi inseriscilo nella nostra funzione di esecuzione_query cavallo di battaglia.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Controlliamo per confermare che ha avuto l'effetto previsto:
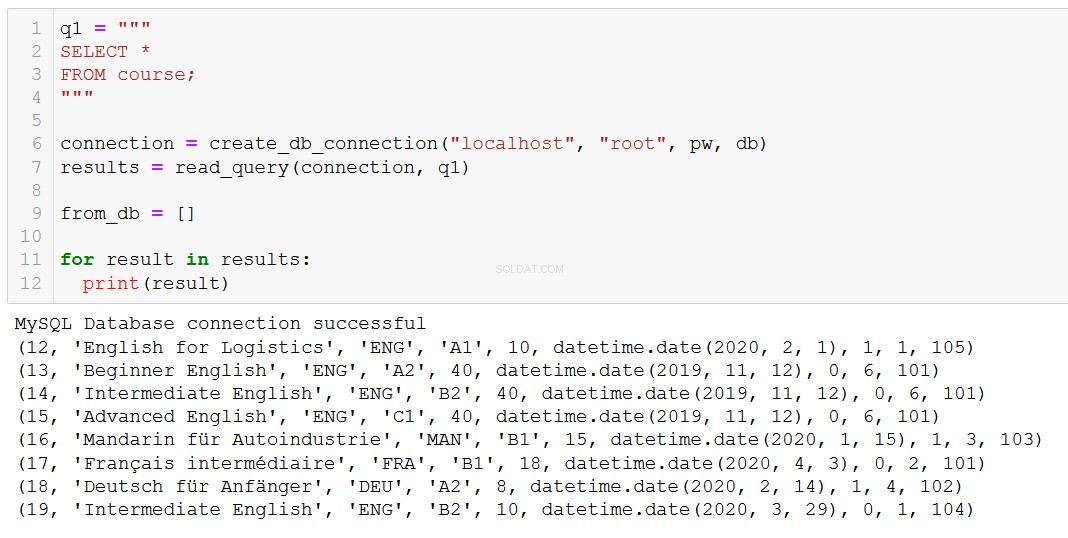
"Advanced Russian" è sparito, come ci aspettavamo.
Funziona anche con l'eliminazione di intere colonne utilizzando DROP COLUMN e intere tabelle utilizzando i comandi DROP TABLE, ma non le tratteremo in questo tutorial.
Vai avanti e sperimentali, tuttavia:non importa se elimini una colonna o una tabella da un database per una scuola immaginaria, ed è una buona idea familiarizzare con questi comandi prima di passare a un ambiente di produzione.
Oh CRUD
A questo punto, siamo ora in grado di completare le quattro operazioni principali per l'archiviazione persistente dei dati.
Abbiamo imparato a:
- Crea:database, tabelle e record completamente nuovi
- Leggi:estrae i dati da un database e archivia i dati in più formati
- Aggiorna - apporta modifiche ai record esistenti nel database
- Elimina - rimuove i record che non sono più necessari
Queste sono cose straordinariamente utili da poter fare.
Prima di finire le cose qui, abbiamo un'altra abilità molto utile da imparare.
Creazione di record da elenchi
Abbiamo visto durante il popolamento delle nostre tabelle che possiamo utilizzare il comando SQL INSERT nella nostra funzione execute_query per inserire record nel nostro database.
Dato che stiamo usando Python per manipolare il nostro database SQL, sarebbe utile poter prendere una struttura dati Python (come una lista) e inserirla direttamente nel nostro database.
Questo potrebbe essere utile quando desideriamo archiviare i registri delle attività degli utenti su un'app di social media che abbiamo scritto in Python o l'input degli utenti in un Wiki che abbiamo creato, ad esempio. Ci sono tutti gli usi possibili per questo che puoi pensare.
Questo metodo è anche più sicuro se il nostro database è aperto ai nostri utenti in qualsiasi momento, poiché aiuta a prevenire attacchi di SQL Injection, che possono danneggiare o addirittura distruggere l'intero database.
Per fare ciò, scriveremo una funzione usando il metodo executemany(), invece del più semplice metodo execute() che abbiamo usato finora.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Ora abbiamo la funzione, dobbiamo definire un comando SQL ('sql') e una lista contenente i valori che vogliamo inserire nel database ('val'). I valori devono essere archiviati come un elenco di tuple, che è un modo abbastanza comune per archiviare i dati in Python.
Per aggiungere due nuovi insegnanti al database, possiamo scrivere del codice come questo:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Nota qui che nel codice 'sql' utilizziamo '%s' come segnaposto per il nostro valore. La somiglianza con il segnaposto '%s' per una stringa in python è solo casuale (e francamente, molto confusa), vogliamo usare '%s' per tutti i tipi di dati (stringhe, int, date, ecc.) con MySQL Python Connettore.
Puoi vedere una serie di domande su Stackoverflow in cui qualcuno si è confuso e ha provato a usare i segnaposto '%d' per i numeri interi perché sono abituati a farlo in Python. In questo caso non funzionerà:dobbiamo utilizzare '%s' per ogni colonna a cui vogliamo aggiungere un valore.
La funzione executemany prende quindi ogni tupla nel nostro elenco 'val' e inserisce il valore rilevante per quella colonna al posto del segnaposto ed esegue il comando SQL per ogni tupla contenuta nell'elenco.
Questa operazione può essere eseguita per più righe di dati, purché formattate correttamente. Nel nostro esempio aggiungeremo solo due nuovi insegnanti, a scopo illustrativo, ma in linea di principio possiamo aggiungerne quanti ne vogliamo.
Andiamo avanti ed eseguiamo questa query e aggiungiamo gli insegnanti al nostro database.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)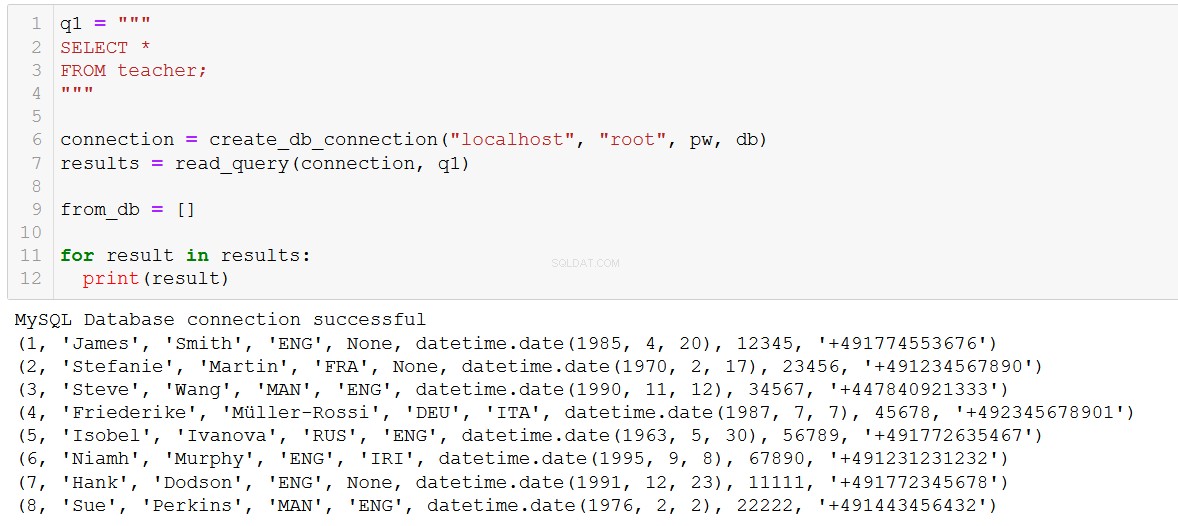
Benvenuto nell'ILS, Hank e Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!