Dipende...
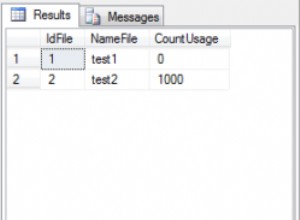
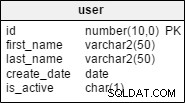
È abbastanza improbabile che un indice sia solo su column1 sarà utile se hai già un indice composito su column1, column2 . Da column1 è l'indice principale, interroga la tabella che ha solo column1 come predicato sarà in grado di utilizzare l'indice composito. Se esegui frequentemente query che richiedono una scansione completa dell'indice e la presenza di column2 aumenta notevolmente la dimensione dell'indice, è possibile che un indice sia solo su column1 sarebbe più efficiente poiché la scansione completa dell'indice richiederebbe meno I/O. Ma questa è una situazione piuttosto insolita.
Un indice solo su column2 può essere utile se alcune delle tue query sulla tabella specificano predicati solo su column2 . Se ci sono relativamente pochi valori distinti di column1 , è possibile che Oracle possa eseguire una scansione di salto dell'indice utilizzando l'indice composito per soddisfare le query che specificano solo column2 come predicato. Ma è probabile che una scansione con salto sia molto meno efficiente di una scansione con intervallo, quindi è ragionevolmente probabile che un indice solo su column2 gioverebbe a quelle domande. Se è presente un numero elevato di valori distinti per column1 , la scansione di salto sarebbe ancora meno efficiente e un indice solo su column2 sarebbe più vantaggioso. Ovviamente, se non esegui mai query sulla tabella utilizzando column2 senza specificare anche un predicato su column1 , non avresti bisogno di un indice solo su column2 .