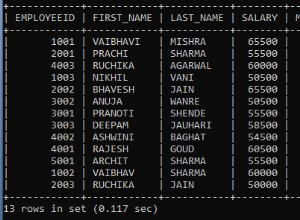
Probabilmente hai duplicati nei dati. DISTINCT non garantisce che tu abbia IdToUpdate unico quando lo utilizzi con altre colonne. Vedi:
CREATE TABLE #MyTable(IdToUpdate INT, LogSetIdToUpdateTo INT);
INSERT INTO #MyTable VALUES (1,1), (1,2), (2,1),(3,1);
SELECT DISTINCT IdToUpdate, LogSetIdToUpdateTo
FROM #MyTable;
Riceverai IdToUpdate due volte. Controlla i tuoi dati:
with cte AS (
select distinct nullLogSetId.Id as IdToUpdate,
knownLogSetId.LogSetId LogSetIdToUpdateTo
from MyTable knownLogSetId
join MyTable nullLogSetId
on knownLogSetId.IdentifierType = nullLogSetId.IdentifierType
and knownLogSetId.Identifier = nullLogSetId.Identifier
where
knownLogSetId.IdentifierType = 'DEF'
and knownLogSetId.LogSetId >= 0
and nullLogSetId.LogSetId = -1
)
SELECT IdToUpdate, COUNT(*) AS c
FROM cte
GROUP BY IdToUpdate
HAVING COUNT(*) > 1;
Un modo per procedere è utilizzare la funzione di aggregazione(MAX/MIN) invece di DISTINCT :
merge into MyTable
using
(
select nullLogSetId.Id as IdToUpdate,
MAX(knownLogSetId.LogSetId) AS LogSetIdToUpdateTo
from MyTable knownLogSetId
join MyTable nullLogSetId
on knownLogSetId.IdentifierType = nullLogSetId.IdentifierType
and knownLogSetId.Identifier = nullLogSetId.Identifier
where
knownLogSetId.IdentifierType = 'DEF'
and knownLogSetId.LogSetId >= 0
and nullLogSetId.LogSetId = -1
GROUP BY nullLogSetId.Id
) on (Id = IdToUpdate)
when matched then
update set LogSetId = LogSetIdToUpdateTo