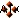Questo post fa parte del tutorial Oracle SQL e discuteremo delle funzioni analitiche in Oracle (Over by partition) con esempi, spiegazioni dettagliate.
Abbiamo già studiato la funzione Oracle Aggregate come avg ,sum ,count. Facciamo un esempio
Per prima cosa creiamo i dati di esempio
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Ora l'esempio di funzioni aggregate verrà fornito come di seguito
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Qui possiamo vedere che riduce il numero di righe in ciascuna delle query. Ora arrivano le domande su cosa fare se dobbiamo avere tutte le righe restituite anche con count(*)
Per quell'oracolo ha fornito una serie di funzioni analitiche. Quindi, per risolvere l'ultimo problema, possiamo scrivere come
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
Qui count(*) over (partition by dept_no) è la versione analitica della funzione di aggregazione count. Il lavoro chiave principale che è diverso per funzione di aggregazione è sulla partizione per
Le funzioni analitiche calcolano un valore aggregato in base a un gruppo di righe. Differiscono dalle funzioni di aggregazione in quanto restituiscono più righe per ogni gruppo. Il gruppo di righe è chiamato finestra ed è definito dalla clausola_analytics.
Ecco la sintassi generale
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Esempio
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Esaminiamo ogni parte
query_partition_clause
Ha definito il gruppo di righe. Può piacere di seguito
partizione per deptno :gruppo di righe dello stesso deptno
o
() :tutte le righe
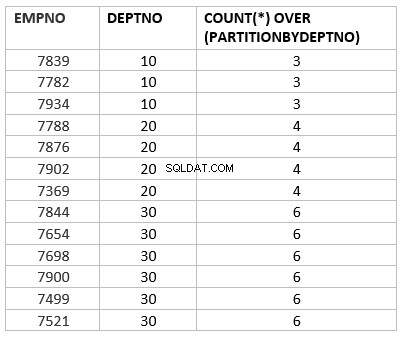
SQL> select empno ,deptno , count(*) over () from emp;
[ order_by_clause [ windowing_clause ] ]
Questa clausola viene utilizzata quando si desidera ordinare le righe nella partizione. Ciò è particolarmente utile se si desidera che la funzione analitica consideri l'ordine delle righe.
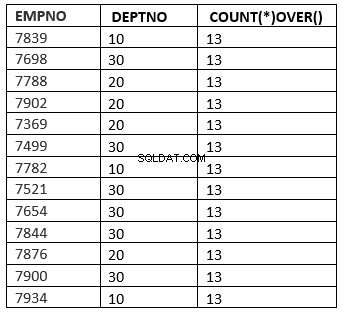
Un esempio sarà la funzione numero_riga
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
Un altro esempio potrebbe essere
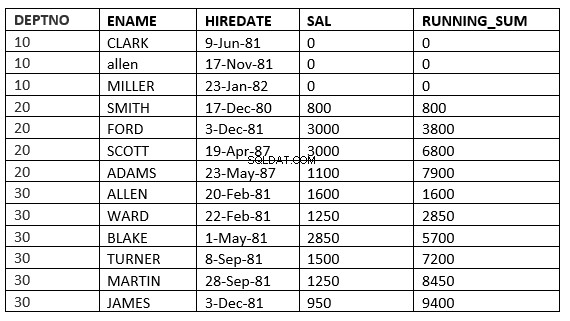
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Finestra_clausola
Viene sempre utilizzato con la clausola order by e offre un maggiore controllo sull'insieme delle righe nel gruppo
Con la clausola Windowing, per ogni riga viene definita una finestra scorrevole di righe. La finestra determina l'intervallo di righe utilizzate per eseguire i calcoli per la riga corrente. Le dimensioni delle finestre possono essere basate su un numero fisico di righe o su un intervallo logico come il tempo.
Quando si utilizza la clausola order by e non viene fornito nulla per windowing_clause, viene preso il valore predefinito al di sotto della windowing_clause
INTERVALLO TRA UNBOUNDED PRECEDING E CURRENT ROW o RANGE UNBOUNDED PRECEDING
Significa "La riga corrente e precedente nella riga corrente partizione sono le righe che dovrebbero essere utilizzate nel calcolo”
L'esempio seguente lo afferma chiaramente. Questa è la media corrente nel dipartimento
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Ora windowing_clause può essere definito in diversi modi
Per prima cosa comprendiamo la terminologia
RIGHE specifica la finestra in unità fisiche (righe).
RANGE specifica la finestra come offset logico. la clausola di windowing RANGE può essere utilizzata solo con clausole ORDER BY contenenti colonne o espressioni di tipi di dati numerici o di data
PRECEDING – prendi le righe prima di quella corrente.
SEGUENTE – ottieni le righe dopo quella corrente.
UNBOUNDED – se utilizzato con PRECEDING o FOLLOWING restituisce tutto prima o dopo. RIGA ATTUALE
Quindi è generalmente definito come
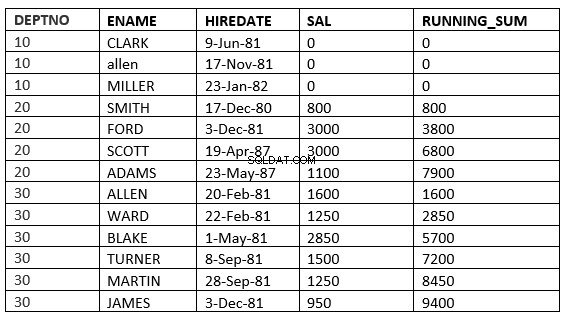
RIGHE PRECEDENTI SENZA LIMITI :le righe correnti e precedenti nella partizione corrente sono le righe che dovrebbero essere utilizzate nel calcolo
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
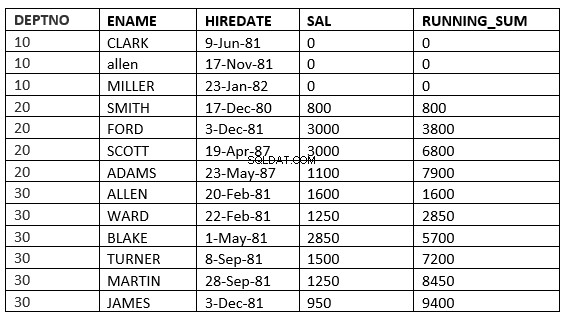
GAMMA SENZA LIMITI PRECEDENTE :le righe correnti e precedenti nella partizione corrente sono le righe che dovrebbero essere utilizzate nel calcolo. Inoltre, poiché è specificato l'intervallo, tutto prende quei valori che sono uguali alle righe correnti.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
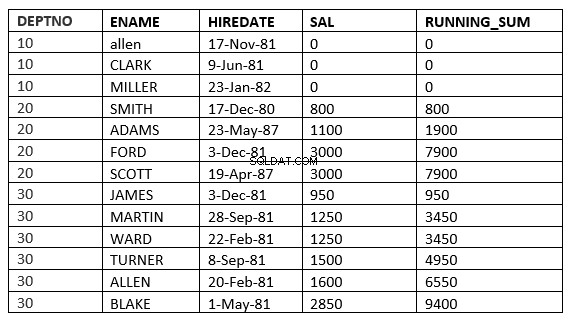
Potresti non vedere la differenza tra intervallo e righe poiché la data_assunzione è diversa per tutti. La differenza diventerà più chiara se utilizziamo sal come clausola per ordine
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
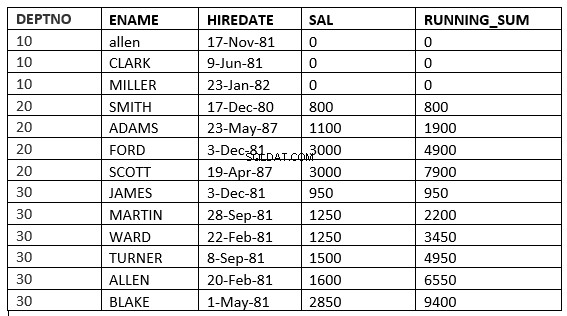
Puoi trovare la differenza alla riga 6
RANGE value_expr PRECEDENTE :la finestra inizia con la riga il cui valore ORDER BY è l'espressione numerica righe inferiori o precedenti alla riga corrente e termina con l'elaborazione della riga corrente.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
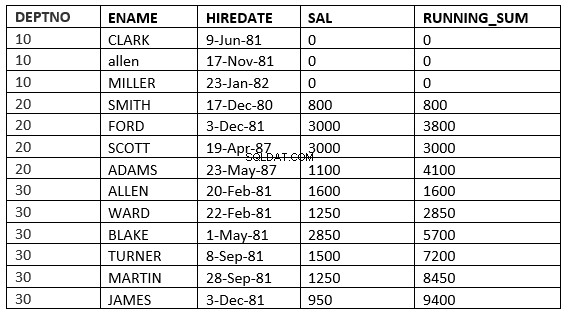
Qui prende tutte le righe in cui il valore di data di assunzione rientra nei 365 giorni precedenti il valore di data di assunzione della riga corrente
RIGHE value_expr PRECEDENTI :La finestra inizia con la riga data e termina con la riga corrente in elaborazione
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
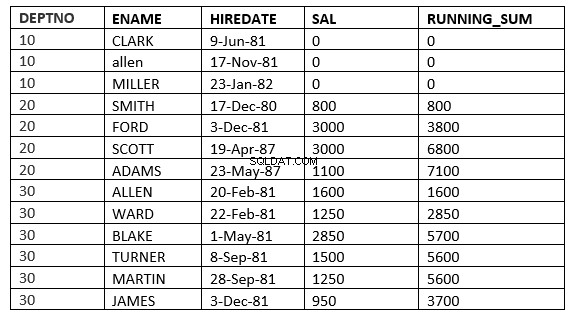
Qui la finestra inizia da 2 righe che precedono la riga corrente
INTERVALLO TRA RIGA ATTUALE e value_expr SEGUENTE :la finestra inizia con la riga corrente e termina con la riga il cui valore ORDER BY è un'espressione numerica righe inferiori o successive
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
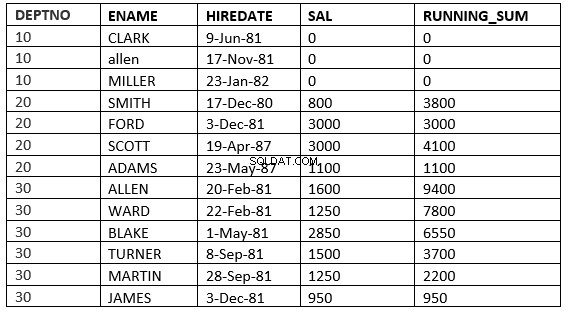
RIGHE TRA RIGA CORRENTE e value_expr SEGUENTI :La finestra inizia con la riga corrente e termina con le righe successive a quella corrente
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
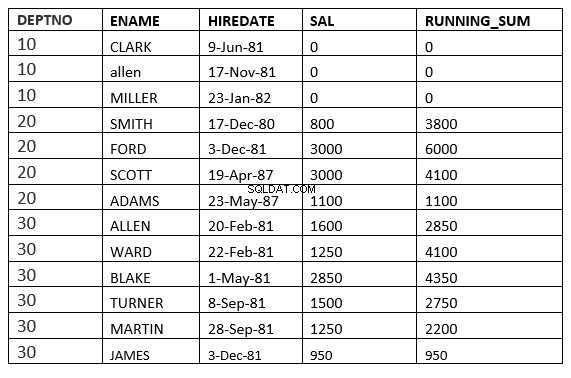
INTERVALLO TRA UNBOUNDED PRECEDING e UNBOUNDED FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
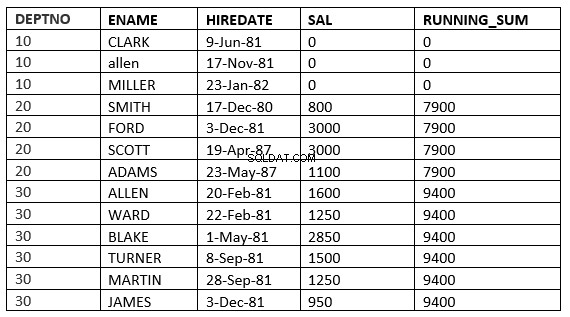
INTERVALLO TRA value_expr PRECEDENTE e value_expr SEGUENTE
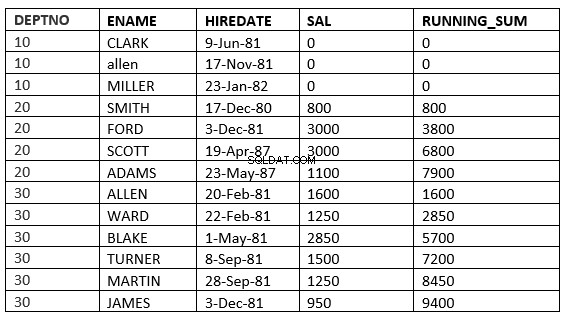
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Alcune note importanti
(1)Le funzioni analitiche sono l'ultimo insieme di operazioni eseguite in una query ad eccezione della clausola ORDER BY finale. Tutti i join e tutte le clausole WHERE, GROUP BY e HAVING vengono completate prima che le funzioni analitiche vengano elaborate. Pertanto, le funzioni analitiche possono essere visualizzate solo nell'elenco di selezione o nella clausola ORDER BY.
(2)Le funzioni analitiche vengono comunemente utilizzate per calcolare aggregati cumulativi, mobili, centrati e di reporting.
Spero che ti piaccia questa spiegazione dettagliata delle funzioni analitiche in Oracle (over by Partition Clause)
Articoli correlati
Funzione LEAD in Oracle
Funzione DENSE in Oracle
Funzione Oracle LISTAGG
Aggregazione dei dati utilizzando le funzioni di gruppo
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm