Un singolo punto di errore (SPOF) è un motivo comune per cui le organizzazioni stanno lavorando per distribuire la presenza dei loro ambienti di database in un'altra posizione geografica. Fa parte dei piani strategici di Disaster Recovery e Business Continuity.
La pianificazione del Disaster Recovery (DR) comprende procedure tecniche che coprono la preparazione per problemi imprevisti come disastri naturali, incidenti (come l'errore umano) o incidenti (come atti criminali).
Nell'ultimo decennio, la distribuzione dell'ambiente di database in più posizioni geografiche è stata una configurazione piuttosto comune, poiché i cloud pubblici offrono molti modi per affrontarlo. La sfida arriva nella creazione di ambienti di database. Crea difficoltà quando provi a gestire i database, a spostare i tuoi dati in un'altra geolocalizzazione o ad applicare la sicurezza con un alto livello di osservabilità.
In questo blog, mostreremo come puoi farlo usando MySQL Replication. Tratteremo come puoi copiare i tuoi dati su un altro nodo di database situato in un paese diverso dall'attuale geografia del cluster MySQL. Per questo esempio, la nostra regione di destinazione si basa su noi-est, mentre il mio locale si trova in Asia, nelle Filippine.
Perché ho bisogno di un cluster di database di geolocalizzazione?
Anche Amazon AWS, il principale provider di cloud pubblico, afferma di soffrire di tempi di inattività o interruzioni non intenzionali (come quella avvenuta nel 2017). Supponiamo che tu stia utilizzando AWS come data center secondario oltre al tuo locale. Non puoi avere alcun accesso interno al suo hardware sottostante oa quelle reti interne che gestiscono i tuoi nodi di calcolo. Si tratta di servizi completamente gestiti che hai pagato, ma non puoi evitare il fatto che possa subire un'interruzione in qualsiasi momento. Se una tale posizione geografica subisce un'interruzione, è possibile che si verifichino lunghi tempi di inattività.
Questo tipo di problema deve essere previsto durante la pianificazione della continuità aziendale. Deve essere stato analizzato e implementato sulla base di quanto definito. La continuità aziendale per i database MySQL dovrebbe includere tempi di attività elevati. Alcuni ambienti stanno eseguendo benchmark e impostano un livello elevato di test rigorosi, incluso il lato debole, al fine di esporre qualsiasi vulnerabilità, quanto può essere resiliente e quanto scalabile la tua architettura tecnologica, inclusa l'infrastruttura del database. Per le aziende, in particolare quelle che gestiscono transazioni elevate, è fondamentale garantire che i database di produzione siano sempre disponibili per le applicazioni anche quando si verifica una catastrofe. In caso contrario, potrebbero verificarsi tempi di inattività e potrebbero costarti una grande quantità di denaro.
Con questi scenari identificati, le organizzazioni iniziano a estendere la propria infrastruttura a diversi provider di cloud e a posizionare i nodi in diverse geolocalizzazioni per avere tempi di attività più elevati (se possibile a 99,999999999999), un RPO inferiore e non hanno SPOF.
Per garantire che i database di produzione sopravvivano a un disastro, è necessario configurare un sito di Disaster Recovery (DR). I siti di produzione e DR devono far parte di due datacenter geograficamente distanti. Ciò significa che è necessario configurare un database di standby nel sito di ripristino di emergenza per ogni database di produzione in modo che le modifiche ai dati che si verificano nel database di produzione vengano immediatamente sincronizzate con il database di standby tramite i registri delle transazioni. Alcune configurazioni utilizzano anche i loro nodi DR per gestire le letture in modo da fornire il bilanciamento del carico tra l'applicazione e il livello dati.
La configurazione architettonica desiderata
In questo blog, la configurazione desiderata è un'implementazione semplice e tuttavia molto comune al giorno d'oggi. Vedi sotto sulla configurazione architettonica desiderata per questo blog:
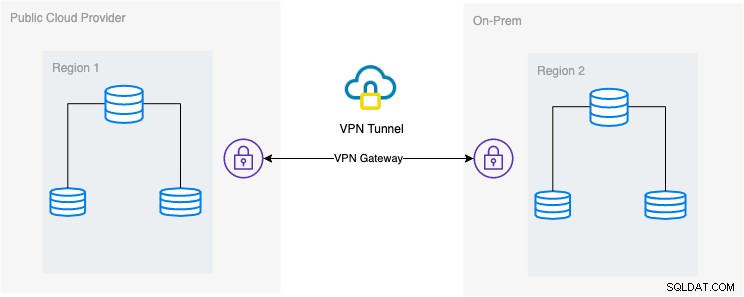
In questo blog, scelgo Google Cloud Platform (GCP) come pubblico provider cloud e utilizzando la mia rete locale come ambiente di database in loco.
È fondamentale che quando si utilizza questo tipo di design, sia necessario sia l'ambiente che la piattaforma per comunicare in modo molto sicuro. Utilizzando VPN o utilizzando alternative come AWS Direct Connect. Sebbene questi cloud pubblici al giorno d'oggi offrano servizi VPN gestiti che puoi utilizzare. Ma per questa configurazione utilizzeremo OpenVPN poiché non ho bisogno di hardware o servizi sofisticati per questo blog.
Il modo migliore e più efficiente
Per gli ambienti di database MySQL/Percona/MariaDB, il modo migliore ed efficiente è prendere una copia di backup del database, inviarla al nodo di destinazione per essere implementata o istanziata. Esistono diversi modi per utilizzare questo approccio:puoi utilizzare mysqldump, mydumper, rsync o utilizzare Percona XtraBackup/Mariabackup e trasmettere i dati in streaming al tuo nodo di destinazione.
Utilizzo di mysqldump
mysqldump crea un backup logico dell'intero database oppure puoi scegliere selettivamente un elenco di database, tabelle o persino record specifici di cui desideri eseguire il dump.
Un semplice comando che puoi utilizzare per eseguire un backup completo può essere,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsCon questo semplice comando, eseguirà direttamente le istruzioni MySQL sul nodo del database di destinazione, ad esempio il nodo del database di destinazione su un Google Compute Engine. Questo può essere efficiente quando i dati sono più piccoli o hai una larghezza di banda veloce. In caso contrario, può essere la tua opzione imballare il database in un file e quindi inviarlo al nodo di destinazione.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathQuindi esegui mysqldump sul nodo del database di destinazione in quanto tale,
zcat mydata.db | mysqlLo svantaggio dell'utilizzo del backup logico tramite mysqldump è che è più lento e consuma spazio su disco. Utilizza anche un singolo thread, quindi non puoi eseguirlo in parallelo. Facoltativamente, puoi usare mydumper soprattutto quando i tuoi dati sono troppo grandi. mydumper può essere eseguito in parallelo ma non è così flessibile rispetto a mysqldump.
Utilizzo di xtrabackup
xtrabackup è un backup fisico in cui puoi inviare flussi o file binari al nodo di destinazione. Questo è molto efficiente e viene utilizzato principalmente durante lo streaming di un backup sulla rete, specialmente quando il nodo di destinazione ha un'area geografica diversa o una regione diversa. ClusterControl utilizza xtrabackup durante il provisioning o la creazione di un'istanza di un nuovo slave indipendentemente da dove si trovi, purché l'accesso e l'autorizzazione siano stati impostati prima dell'azione.
Se stai usando xtrabackup per eseguirlo manualmente, puoi eseguire il comando come tale,
## Nodo di destinazione
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## nodo di origine
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Per elaborare questi due comandi, il primo comando deve essere eseguito o eseguito prima sul nodo di destinazione. Il comando del nodo di destinazione è in ascolto sulla porta 9999 e scriverà qualsiasi flusso ricevuto dalla porta 9999 nel nodo di destinazione. Dipende dai comandi socat e xbstream, il che significa che devi assicurarti di aver installato questi pacchetti.
Sul nodo sorgente, esegue lo script perl innobackupex che richiama xtrabackup in background e utilizza xbstream per trasmettere i dati che verranno inviati sulla rete. Il comando socat apre la porta 9999 e invia i suoi dati all'host desiderato, che in questo esempio è 192.168.10.70. Tuttavia, assicurati di aver installato socat e xbstream quando usi questo comando. Un modo alternativo di usare socat è nc ma socat offre funzionalità più avanzate rispetto a nc come la serializzazione come più client possono ascoltare su una porta.
ClusterControl usa questo comando durante la ricostruzione di uno slave o la creazione di un nuovo slave. È veloce e garantisce che la copia esatta dei dati di origine venga copiata sul nodo di destinazione. Quando si esegue il provisioning di un nuovo database in una posizione geografica separata, l'utilizzo di questo approccio offre maggiore efficienza e maggiore velocità per completare il lavoro. Sebbene possano esserci pro e contro quando si utilizza il backup logico o binario durante lo streaming attraverso il cavo. L'utilizzo di questo metodo è un approccio molto comune quando si configura un nuovo cluster di database di geolocalizzazione in una regione diversa e si crea una copia esatta dell'ambiente del database.
Efficienza, osservabilità e velocità
Le domande poste dalla maggior parte delle persone che non hanno familiarità con questo approccio riguardano sempre i problemi "COME, COSA, DOVE". In questa sezione, illustreremo come configurare in modo efficiente il database di geolocalizzazione con meno lavoro da gestire e con l'osservabilità del motivo per cui non riesce. L'utilizzo di ClusterControl è molto efficiente. In questa configurazione attuale ho il seguente ambiente come inizialmente implementato:
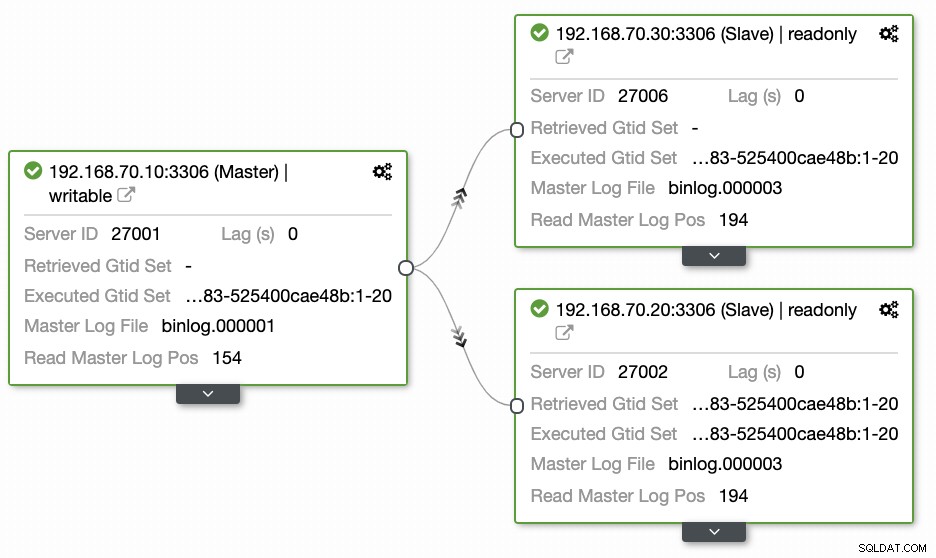
Estensione del nodo a GCP
Iniziando a configurare il tuo cluster di database di geo-localizzazione, per estendere il tuo cluster e creare una copia snapshot del tuo cluster, puoi aggiungere un nuovo slave. Come accennato in precedenza, ClusterControl utilizzerà xtrabackup (mariabackup per MariaDB 10.2 in poi) e distribuirà un nuovo nodo all'interno del cluster. Prima di poter registrare i nodi di calcolo GCP come nodi di destinazione, è necessario configurare prima l'utente di sistema appropriato come l'utente di sistema registrato in ClusterControl. Puoi verificarlo nel tuo /etc/cmon.d/cmon_X.cnf, dove X è cluster_id. Ad esempio, vedi sotto:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (in questo esempio) deve essere presente nei nodi di calcolo GCP. L'utente nei tuoi nodi GCP deve disporre dei privilegi sudo o super amministratore. Deve inoltre essere configurato con un accesso SSH senza password. Si prega di leggere la nostra documentazione di più sull'utente di sistema e sui suoi privilegi richiesti.
Di seguito un elenco di server di esempio (dalla console GCP:dashboard di Compute Engine):
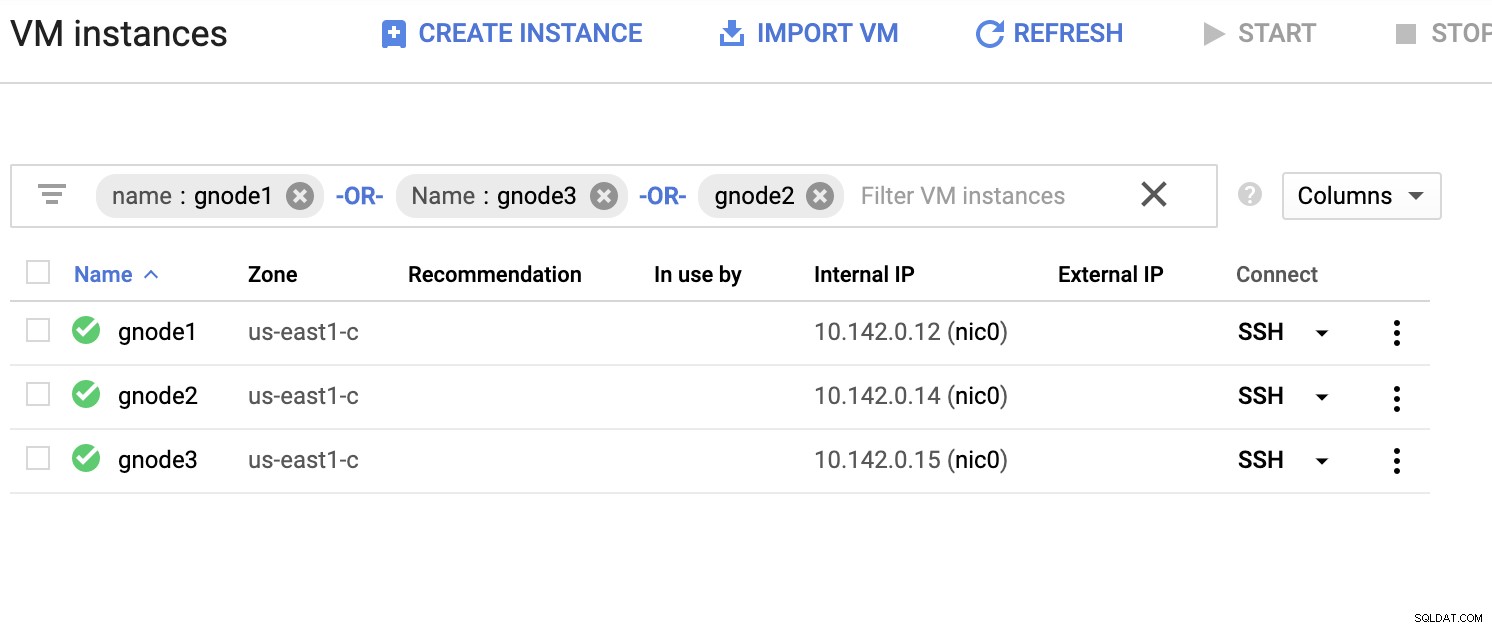
Nello screenshot qui sopra, la nostra regione di destinazione si basa sugli Stati Uniti orientali regione. Come notato in precedenza, la mia rete locale è configurata su un livello sicuro che passa attraverso GCP (viceversa) utilizzando OpenVPN. Quindi anche la comunicazione da GCP che va alla mia rete locale è incapsulata sul tunnel VPN.
Aggiungi un nodo slave a GCP
Lo screenshot qui sotto mostra come puoi farlo. Vedi le immagini sotto:
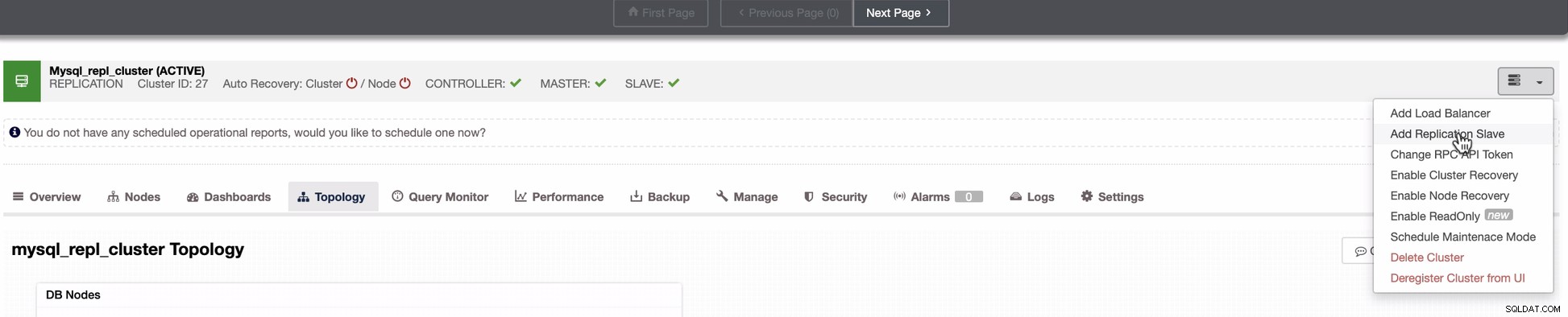
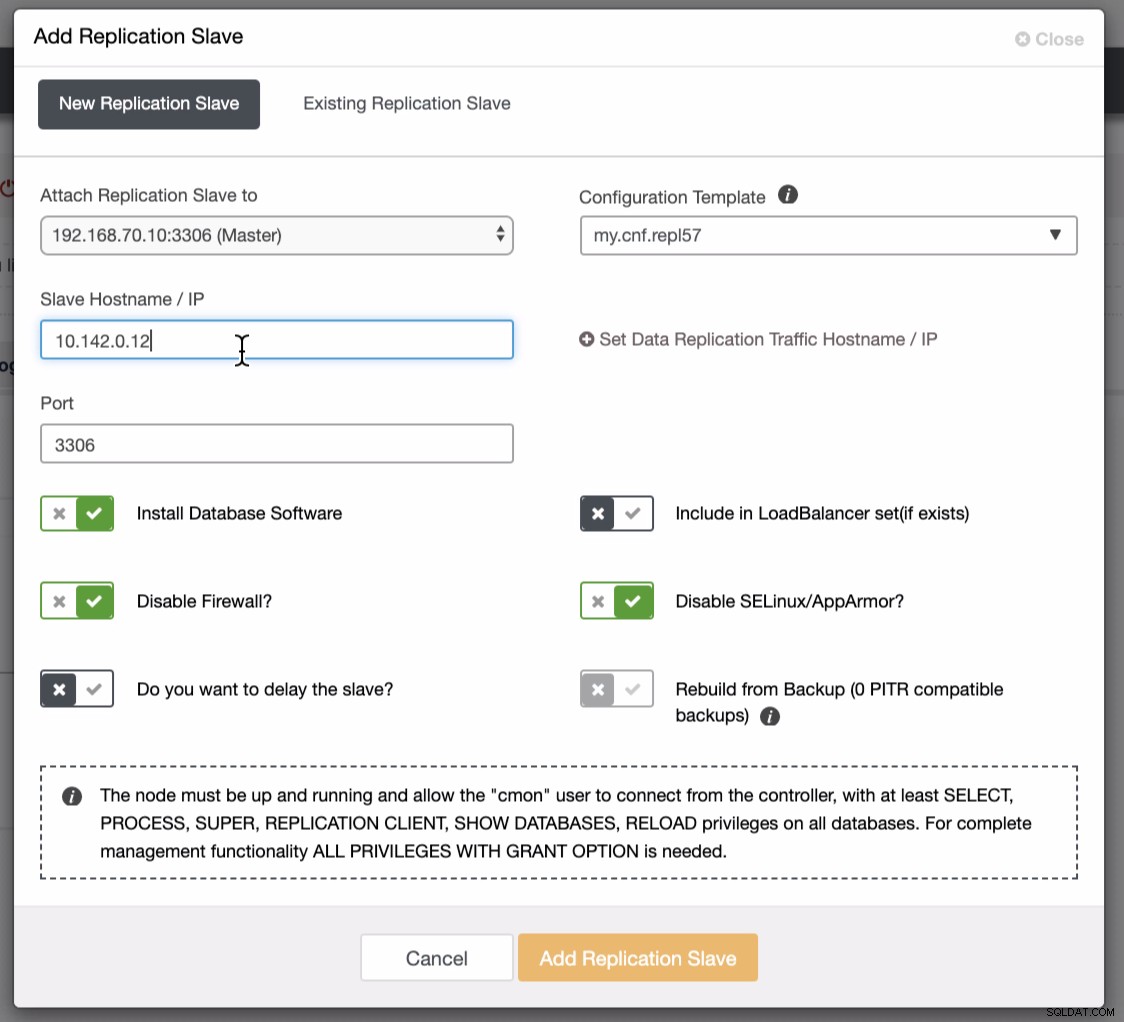
Come si vede nel secondo screenshot, stiamo prendendo di mira il nodo 10.142.0.12 e il suo master di origine è 192.168.70.10. ClusterControl è abbastanza intelligente da determinare firewall, moduli di sicurezza, pacchetti, configurazione e configurazione che devono essere eseguiti. Vedi sotto un esempio di registro delle attività lavorative:
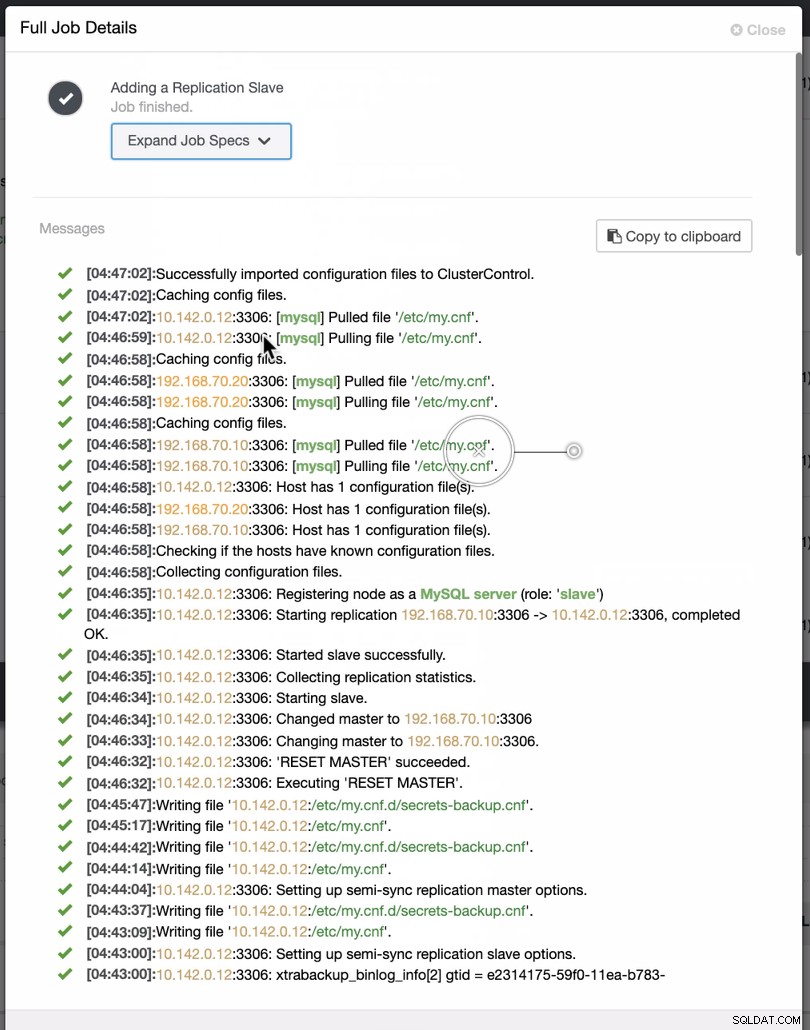
Un compito abbastanza semplice, vero?
Completa il cluster MySQL GCP
Dobbiamo aggiungere altri due nodi al cluster GCP per avere una topologia di bilanciamento come quella che avevamo nella rete locale. Per il secondo e il terzo nodo, assicurati che il master indichi il tuo nodo GCP. In questo esempio, il master è 10.142.0.12. Vedi sotto come farlo,
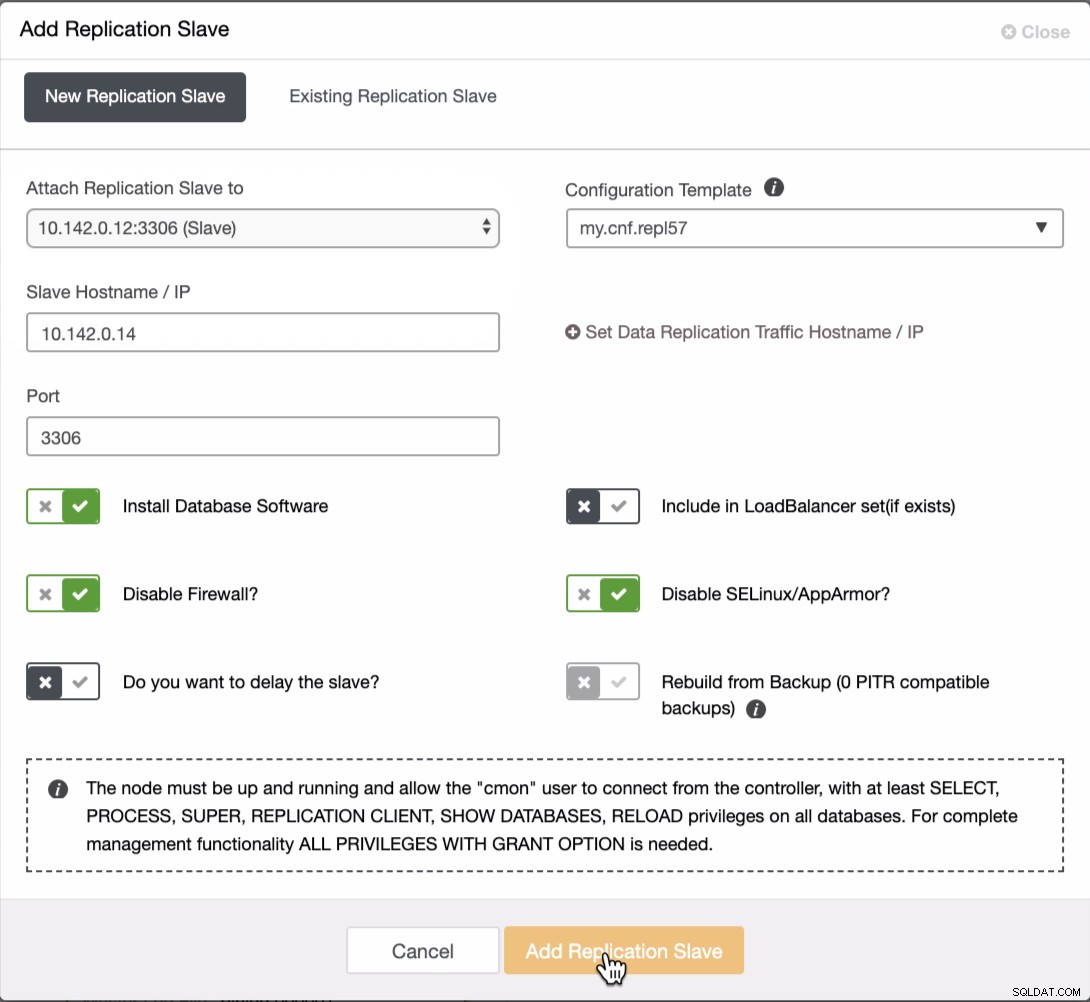
Come si vede nello screenshot qui sopra, ho selezionato 10.142.0.12 (slave ) che è il primo nodo che abbiamo aggiunto al cluster. Il risultato completo viene mostrato come segue,
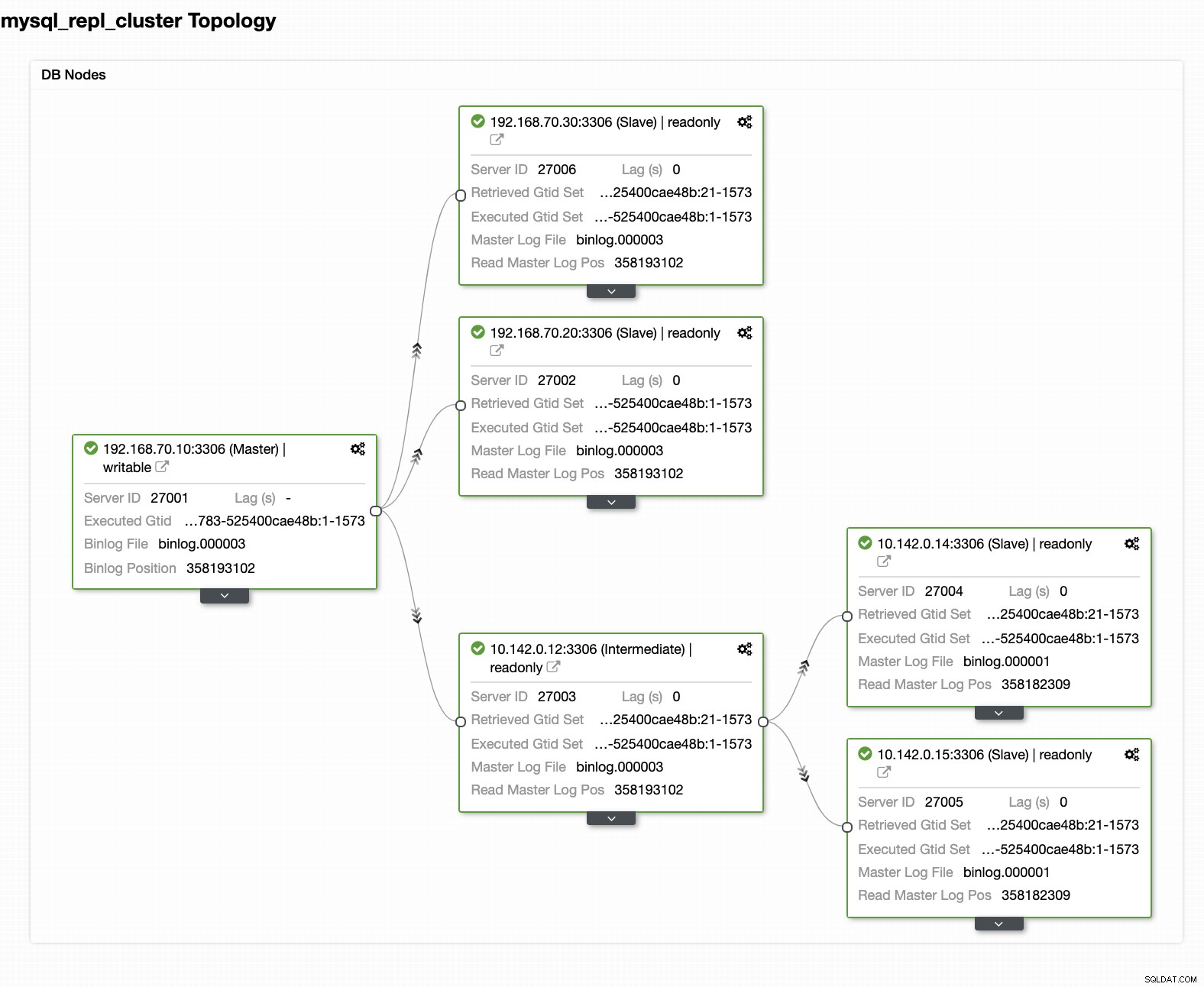
La configurazione finale del cluster di database di geolocalizzazione
Dall'ultimo screenshot, questo tipo di topologia potrebbe non essere la configurazione ideale. Per lo più, deve essere una configurazione multi-master, in cui il tuo cluster di ripristino di emergenza funge da cluster di standby, mentre il tuo locale funge da cluster attivo principale. Per fare ciò, è abbastanza semplice in ClusterControl. Guarda gli screenshot seguenti per raggiungere questo obiettivo.
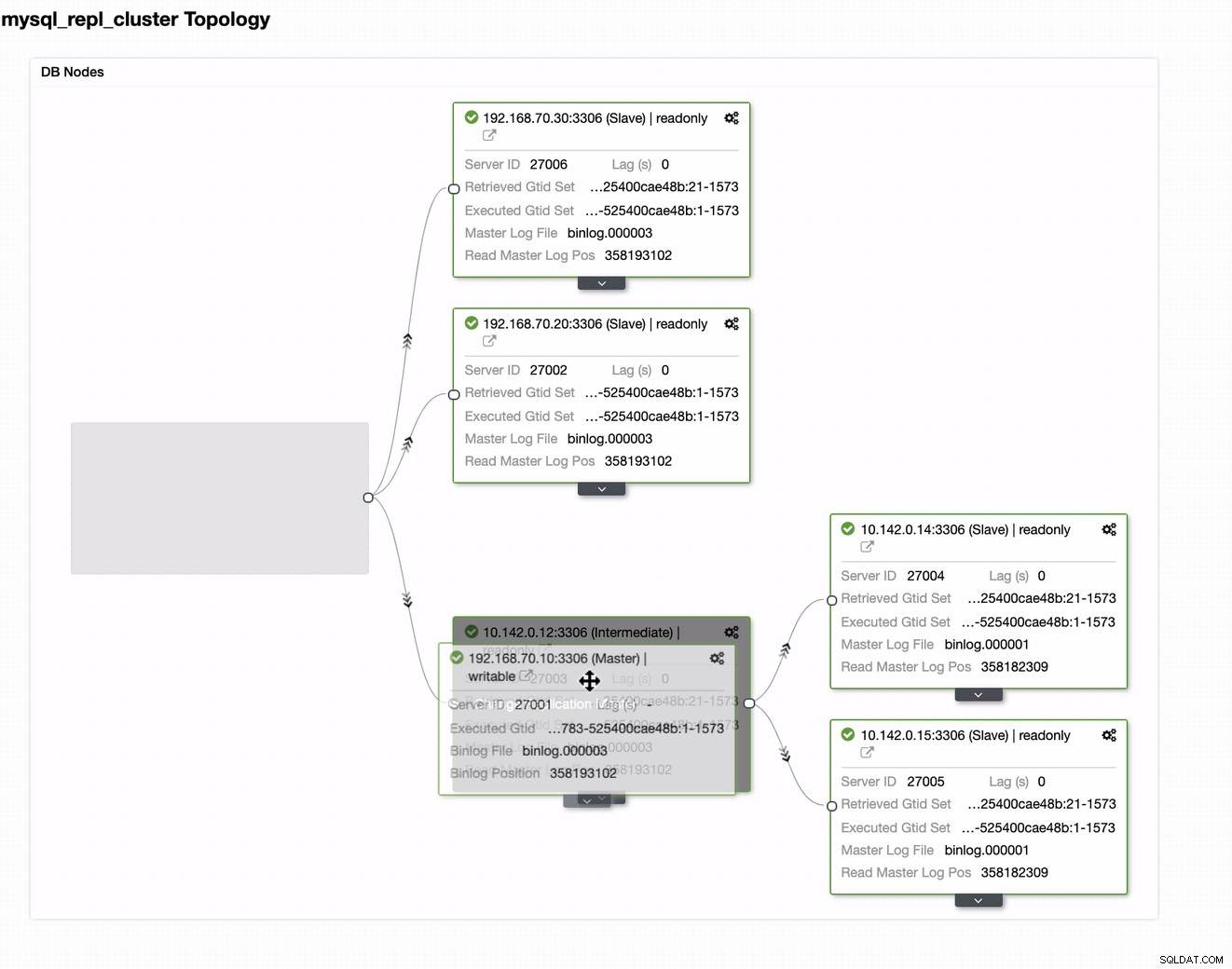
Puoi semplicemente trascinare il tuo master attuale sul master di destinazione che deve essere impostato come scrittore di standby primario nel caso in cui il tuo locale sia in pericolo. In questo esempio, trasciniamo l'host di destinazione 10.142.0.12 (nodo di calcolo GCP). Il risultato finale è mostrato di seguito:
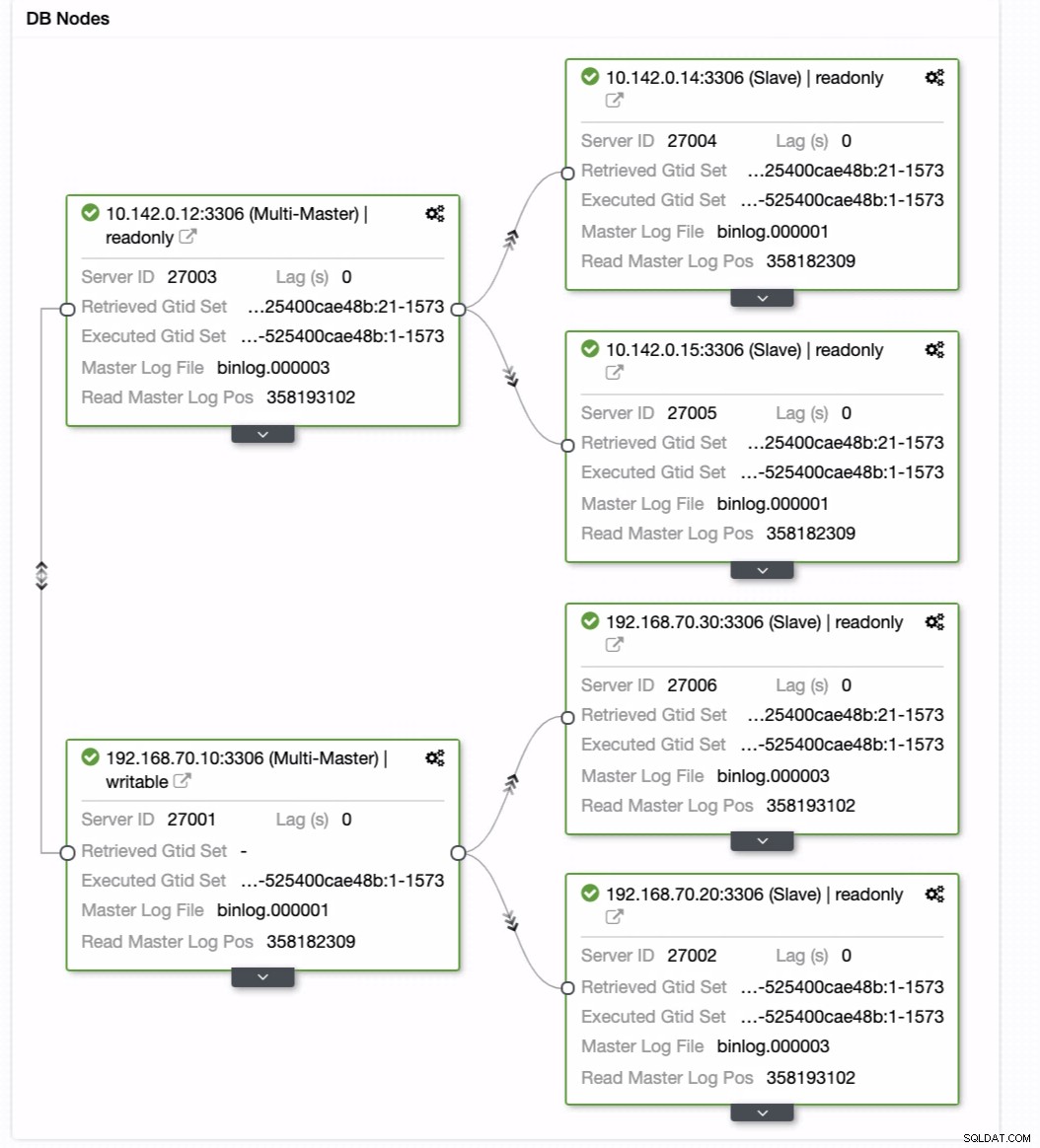
Quindi ottiene il risultato desiderato. Facile e molto veloce per generare il tuo cluster di database di geolocalizzazione utilizzando la replica MySQL.
Conclusione
Avere un cluster di database di geolocalizzazione non è una novità. È stata una configurazione desiderata per le aziende e le organizzazioni che evitano SPOF che desiderano resilienza e un RPO inferiore.
Gli aspetti principali di questa configurazione sono sicurezza, ridondanza e resilienza. Descrive anche quanto fattibile ed efficiente puoi distribuire il tuo nuovo cluster in un'area geografica diversa. Sebbene ClusterControl possa offrire questo, ci aspettiamo che possiamo ottenere ulteriori miglioramenti su questo prima, in cui puoi creare in modo efficiente da un backup e generare il tuo nuovo cluster diverso in ClusterControl, quindi resta sintonizzato.