È abbastanza comune vedere database distribuiti in più posizioni geografiche. Uno scenario per eseguire questo tipo di configurazione è il ripristino di emergenza, in cui il data center di standby si trova in una posizione separata rispetto al data center principale. Potrebbe anche essere necessario in modo che i database si trovino più vicino agli utenti.
La sfida principale per ottenere questa configurazione consiste nel progettare il database in modo da ridurre la possibilità di problemi relativi al partizionamento della rete. Una delle soluzioni potrebbe essere quella di utilizzare Galera Cluster invece della normale replica asincrona (o semisincrona). In questo blog parleremo dei pro e dei contro di questo approccio. Questa è la prima parte di una serie di due blog. Nella seconda parte progetteremo il cluster Galera distribuito geograficamente e vedremo come ClusterControl può aiutarci a implementare tale ambiente.
Perché Galera Cluster invece della replica asincrona per cluster geodistribuiti?
Consideriamo le principali differenze tra la Galera e la replica regolare. La replica regolare fornisce un solo nodo su cui scrivere, ciò significa che ogni scrittura dal centro dati remoto dovrebbe essere inviata tramite la WAN (Wide Area Network) per raggiungere il master. Significa anche che tutti i proxy situati nel data center remoto dovranno essere in grado di monitorare l'intera topologia, coprendo tutti i data center coinvolti poiché devono essere in grado di dire quale nodo è attualmente il master.
Questo porta al numero di problemi. Innanzitutto, è necessario stabilire più connessioni attraverso la WAN, questo aggiunge latenza e rallenta i controlli che il proxy potrebbe essere in esecuzione. Inoltre, ciò aggiunge un sovraccarico non necessario sui proxy e sui database. La maggior parte delle volte sei interessato solo a instradare il traffico ai nodi del database locale. L'unica eccezione è il master e solo per questo i proxy sono costretti a controllare l'intera infrastruttura anziché solo la parte situata nel datacenter locale. Ovviamente, puoi provare a superare questo problema utilizzando proxy per instradare solo SELECT, mentre usando qualche altro metodo (nome host dedicato per master gestito da DNS) per indirizzare l'applicazione al master, ma questo aggiunge livelli di complessità non necessari e parti mobili, che potrebbe avere un serio impatto sulla tua capacità di gestire più nodi e guasti della rete senza perdere la coerenza dei dati.
Galera Cluster può supportare più writer. Anche la latenza è un fattore, poiché tutti i nodi del cluster Galera devono coordinarsi e comunicare per certificare i set di scrittura, può anche essere il motivo per cui potresti decidere di non utilizzare Galera quando la latenza è troppo alta. È anche un problema nei cluster di replica:nei cluster di replica la latenza influisce solo sulle scritture dai data center remoti mentre le connessioni dal data center in cui si trova il master trarrebbero vantaggio da un commit a bassa latenza.
In MySQL Replication devi anche prendere in considerazione lo scenario peggiore e assicurarti che l'applicazione sia a posto con scritture ritardate. Il master può sempre cambiare e non puoi essere sicuro che scriverai sempre a un nodo locale.
Un'altra differenza tra la replica e Galera Cluster è la gestione del ritardo di replica. I cluster geo-distribuiti possono essere seriamente interessati dal ritardo:latenza, throughput limitato della connessione WAN, tutto ciò influirà sulla capacità di un cluster replicato di tenere il passo con la replica. Tieni presente che la replica genera traffico uno su tutto.
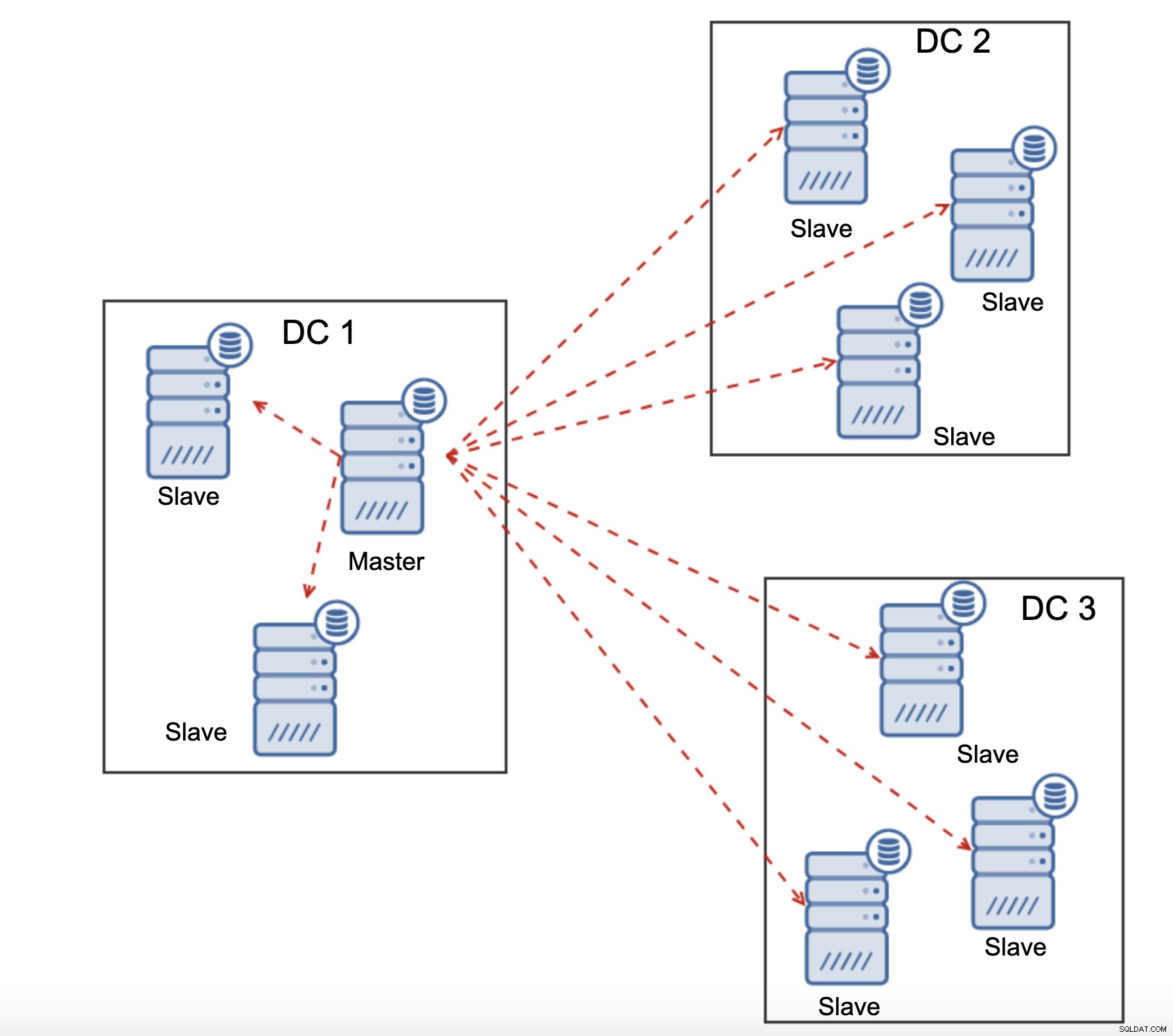
Tutti gli slave devono ricevere l'intero traffico di replica - la quantità di dati che hai da inviare a slave remoti su WAN aumenta con ogni slave remoto che aggiungi. Ciò può facilmente comportare la saturazione del collegamento WAN, soprattutto se si apportano molte modifiche e il collegamento WAN non ha un buon throughput. Come puoi vedere nel diagramma sopra, con tre data center e tre nodi in ciascuno di essi, il master deve inviare 6 volte il traffico di replica tramite connessione WAN.
Con il cluster Galera le cose sono leggermente diverse. Per cominciare, Galera utilizza il controllo del flusso per mantenere sincronizzati i nodi. Se uno dei nodi inizia a rimanere indietro, ha la capacità di chiedere al resto del cluster di rallentare e lasciarlo recuperare. Certo, questo riduce le prestazioni dell'intero cluster, ma è comunque meglio di quando non puoi davvero usare gli slave per SELECT poiché di tanto in tanto tendono a ritardare - in questi casi i risultati che otterrai potrebbero essere obsoleti e errati.
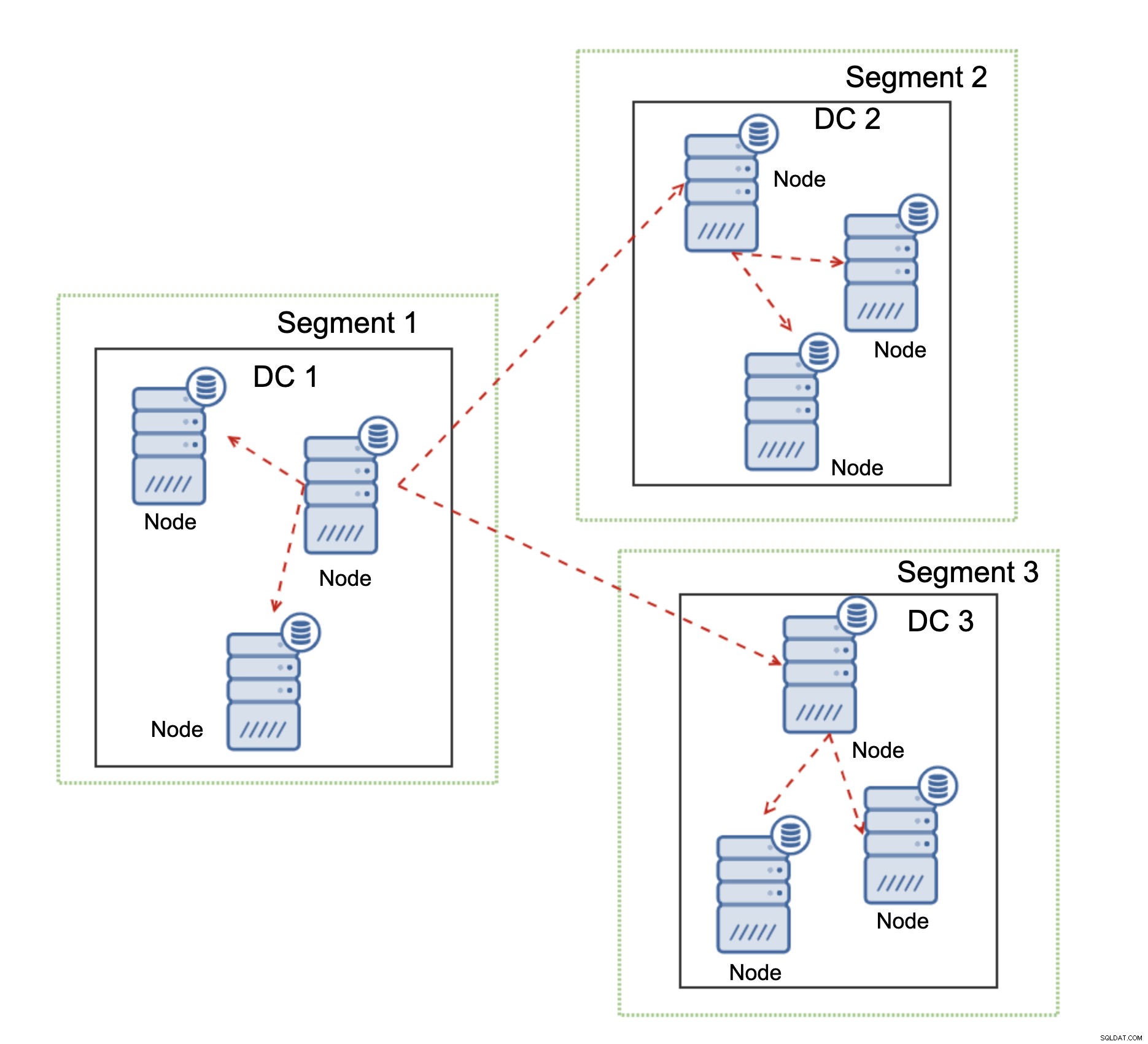
Un'altra caratteristica di Galera Cluster, che può migliorare significativamente le sue prestazioni se utilizzata su WAN, sono segmenti. Per impostazione predefinita, Galera usa tutte le comunicazioni e ogni set di scrittura viene inviato dal nodo a tutti gli altri nodi del cluster. Questo comportamento può essere modificato utilizzando i segmenti. I segmenti consentono agli utenti di dividere il cluster Galera in più parti. Ogni segmento può contenere più nodi e ne elegge uno come nodo di inoltro. Tale nodo riceve i set di scritture da altri segmenti e li ridistribuisce tra i nodi Galera locali al segmento. Di conseguenza, come puoi vedere nel diagramma sopra, è possibile ridurre il traffico di replica su WAN tre volte - solo due "repliche" del flusso di replica vengono inviate su WAN:una per datacenter rispetto a una per slave nella replica MySQL.
Galera Cluster Network Partitioning Handling
Il punto in cui Galera Cluster brilla è la gestione del partizionamento di rete. Galera Cluster monitora costantemente lo stato dei nodi nel cluster. Ogni nodo tenta di connettersi con i suoi peer e scambiare lo stato del cluster. Se il sottoinsieme di nodi non è raggiungibile, Galera tenta di inoltrare la comunicazione, quindi se c'è un modo per raggiungere quei nodi, verranno raggiunti.

Un esempio può essere visto nel diagramma sopra:DC 1 ha perso la connettività con DC2 ma DC2 e DC3 possono connettersi. In questo caso uno dei nodi in DC3 verrà utilizzato per trasmettere i dati da DC1 a DC2 assicurando che la comunicazione intra-cluster possa essere mantenuta.
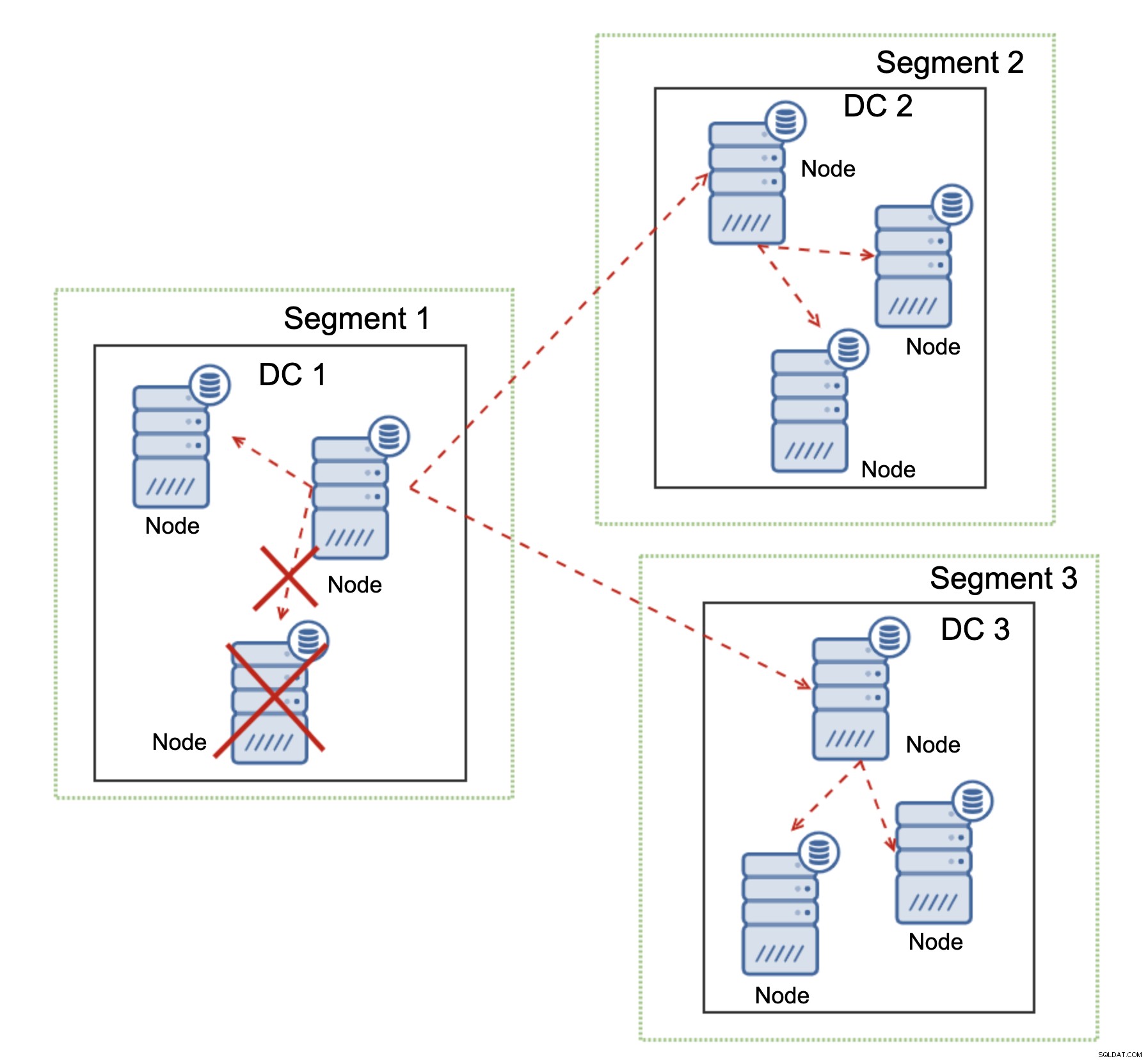
Galera Cluster è in grado di eseguire azioni in base allo stato del cluster. Implementa il quorum:la maggior parte dei nodi deve essere disponibile affinché il cluster possa funzionare. Se il nodo viene disconnesso dal cluster e non riesce a raggiungere nessun altro nodo, cesserà di funzionare.
Come si può vedere nel diagramma sopra, c'è una perdita parziale della comunicazione di rete in DC1 e il nodo interessato viene rimosso dal cluster, assicurando che l'applicazione non acceda a dati obsoleti.
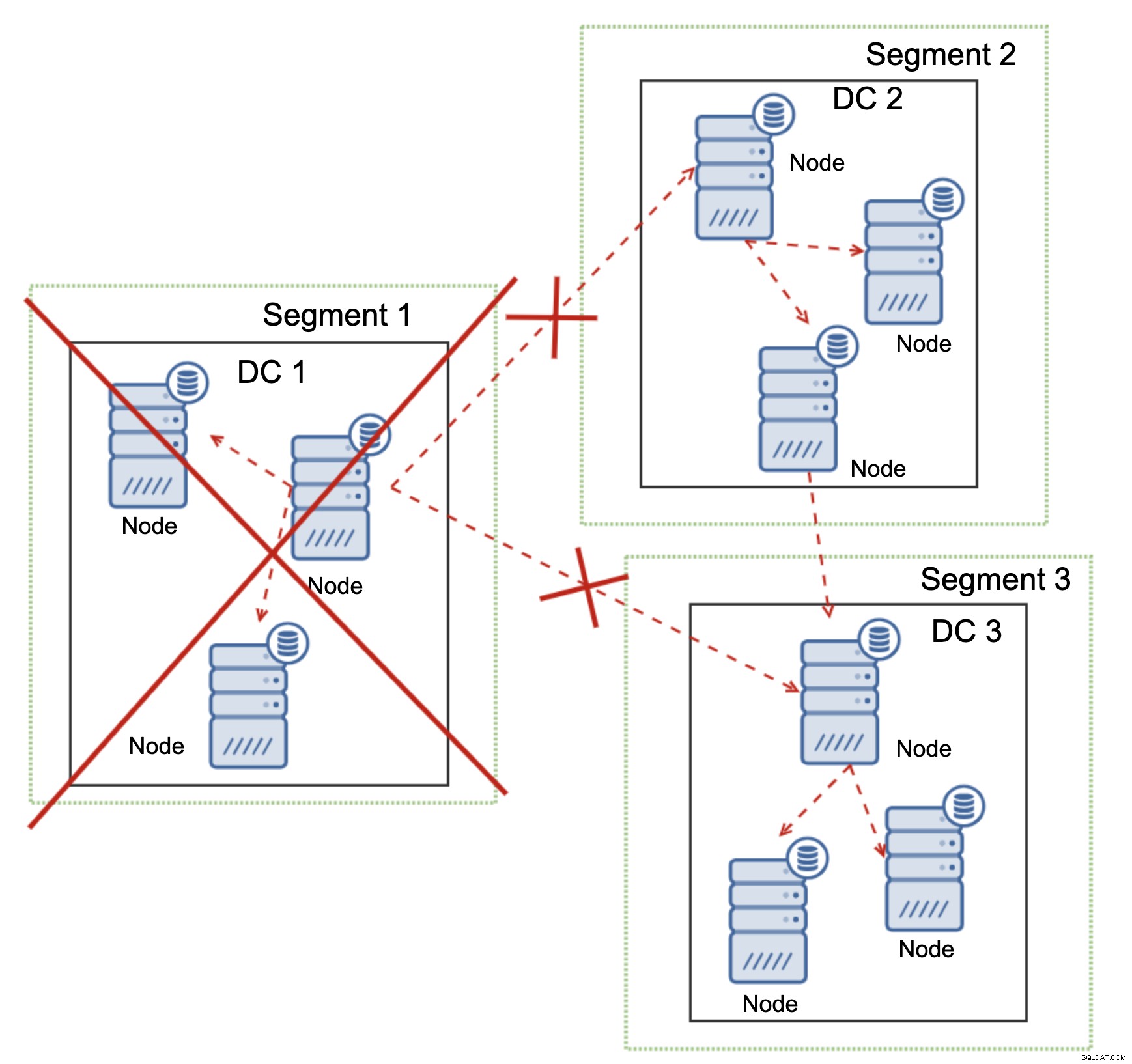
Questo vale anche su scala più ampia. Il DC1 ha interrotto tutte le comunicazioni. Di conseguenza, l'intero data center è stato rimosso dal cluster e nessuno dei suoi nodi servirà il traffico. Il resto del cluster ha mantenuto la maggioranza (sono disponibili 6 nodi su 9) e si è riconfigurato per mantenere la connessione tra DC 2 e DC3. Nel diagramma sopra abbiamo ipotizzato che la scrittura raggiunga il nodo in DC2, ma tieni presente che Galera è in grado di funzionare con più writer.
La replica MySQL non ha alcun tipo di riconoscimento del cluster, rendendo problematica la gestione dei problemi di rete. Non può spegnersi dopo aver perso la connessione con altri nodi. Non esiste un modo semplice per impedire che il vecchio master si presenti dopo la divisione della rete.
Le uniche possibilità sono limitate al livello proxy o anche superiore. È necessario progettare un sistema che tenti di comprendere lo stato del cluster e di intraprendere le azioni necessarie. Un modo possibile consiste nell'utilizzare strumenti compatibili con i cluster come Orchestrator e quindi eseguire script che verificherebbero lo stato del cluster RAFT di Orchestrator e, in base a questo stato, eseguirebbero le azioni richieste a livello di database. Questo è tutt'altro che l'ideale perché qualsiasi azione intrapresa su un livello più alto del database aggiunge ulteriore latenza:rende possibile che il problema si manifesti e la coerenza dei dati sia compromessa prima che possa essere intrapresa l'azione corretta. Galera, invece, interviene a livello di database, garantendo la reazione più rapida possibile.