Se la tua infrastruttura IT è in esecuzione su AWS, probabilmente hai sentito parlare di Amazon Relational Database Service (RDS), un modo semplice per configurare, utilizzare e ridimensionare un database relazionale nel cloud. Fornisce una capacità ridimensionabile e conveniente, automatizzando al contempo attività di amministrazione che richiedono tempo, come il provisioning dell'hardware, l'impostazione del database, l'applicazione di patch e i backup. Esistono numerose offerte di motori di database per RDS come MySQL, MariaDB, PostgreSQL, Microsoft SQL Server e Oracle Server.
ClusterControl 1.7.3 agisce in modo simile a RDS poiché supporta la distribuzione, la gestione, il monitoraggio e il ridimensionamento del cluster di database sulla piattaforma AWS. Supporta anche una serie di altre piattaforme cloud come Google Cloud Platform e Microsoft Azure. ClusterControl comprende la topologia del database ed è in grado di eseguire il ripristino automatico, la gestione della topologia e molte altre funzionalità avanzate per assumere il controllo del database.
In questo post del blog confronteremo i tempi di failover automatico per Amazon Aurora, Amazon RDS per MySQL e una configurazione di replica MySQL distribuita e gestita da ClusterControl. Il tipo di failover che faremo è la promozione dello slave nel caso in cui il master si interrompa. È qui che lo slave più aggiornato assume il ruolo di master nel cluster per riprendere il servizio di database.
Il nostro test di failover
Per misurare il tempo di failover, eseguiremo un semplice test di aggiornamento della connessione MySQL, con un ciclo per contare lo stato dell'istruzione SQL che si connette a un singolo endpoint del database. Lo script si presenta così:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Lo script Bash sopra si collega semplicemente a un host MySQL ed esegue un aggiornamento su una singola riga con un timeout di 1 secondo sia sui comandi del client Bash che su mysql. I parametri relativi ai timeout sono richiesti in modo da poter misurare correttamente il tempo di inattività in secondi poiché il client mysql per impostazione predefinita si riconnette sempre fino a quando non raggiunge il wait_timeout di MySQL. Abbiamo popolato in anticipo un set di dati di test con il seguente comando:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareLo script segnala se la query precedente è riuscita (OK) o non è riuscita (Fail). Gli output di esempio sono mostrati più in basso.
Failover con Amazon RDS per MySQL
Nel nostro test, utilizziamo l'offerta RDS più bassa con le seguenti specifiche:
- Versione MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Tipo di archiviazione:IOPS (SSD) con provisioning
- IOPS:1000
- Archiviazione:100Gib
- Replica multi-AZ:Sì
Dopo che Amazon RDS effettua il provisioning dell'istanza database, puoi utilizzare qualsiasi applicazione o utilità client MySQL standard per connetterti all'istanza. Nella stringa di connessione, specifichi l'indirizzo DNS dall'endpoint dell'istanza database come parametro host e specifichi il numero di porta dall'endpoint dell'istanza database come parametro della porta.
Secondo la pagina della documentazione di Amazon RDS, in caso di interruzione pianificata o non pianificata dell'istanza database, Amazon RDS passa automaticamente a una replica in standby in un'altra zona di disponibilità se hai abilitato Multi-AZ. Il tempo necessario per il completamento del failover dipende dall'attività del database e da altre condizioni nel momento in cui l'istanza database primaria è diventata non disponibile. I tempi di failover sono in genere di 60-120 secondi.
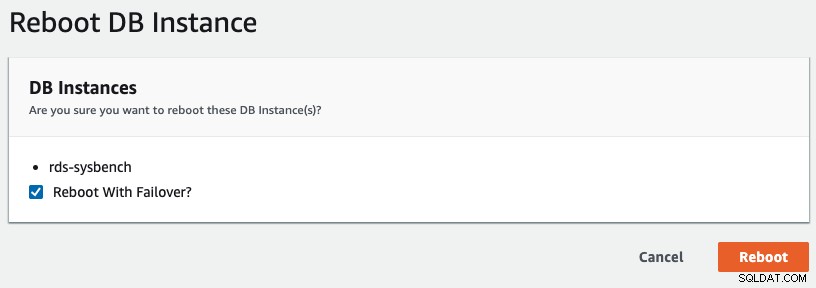
Per avviare un failover multi-AZ in RDS, abbiamo eseguito un'operazione di riavvio con "Riavvia con failover" selezionato, come mostrato nella schermata seguente:
Quanto segue è ciò che viene osservato dalla nostra applicazione:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...Il tempo di inattività di MySQL visto dal lato applicazione è iniziato dalle 03:41:09 alle 03:41:36, che è di circa 27 secondi in totale. Dagli eventi RDS, possiamo vedere che il failover multi-AZ si è verificato solo 15 secondi dopo il tempo di inattività effettivo:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Dopo il riavvio della nuova istanza del database intorno alle 03:41:33, il servizio MySQL era accessibile circa 3 secondi dopo.
Failover con Amazon Aurora per MySQL
Amazon Aurora può essere considerata una versione superiore di RDS, con molte caratteristiche degne di nota come la replica più veloce con lo storage condiviso, nessuna perdita di dati durante il failover e fino a 64 TB di limite di storage. Amazon Aurora per MySQL si basa sull'edizione open source MySQL, ma non è open source di per sé; è un database proprietario e chiuso. Funziona in modo simile con la replica MySQL (uno e un solo master, con più slave) e il failover viene gestito automaticamente da Amazon Aurora.
In base alle domande frequenti su Amazon Aurora, se disponi di una replica Amazon Aurora, nella stessa zona di disponibilità o in una diversa, durante il failover, Aurora capovolge il record del nome canonico (CNAME) affinché la tua istanza database punti alla replica integra, che si trova in turno è promosso a diventare il nuovo primario. Dall'inizio alla fine, il failover in genere viene completato entro 30 secondi.
Se non disponi di una replica Amazon Aurora (ovvero una singola istanza), Aurora tenterà prima di creare una nuova istanza database nella stessa zona di disponibilità dell'istanza originale. Se non è in grado di farlo, Aurora tenterà di creare una nuova istanza database in una zona di disponibilità diversa. Dall'inizio alla fine, il failover in genere viene completato in meno di 15 minuti.
La tua applicazione dovrebbe ritentare le connessioni al database in caso di perdita di connessione.
Dopo che Amazon Aurora effettua il provisioning dell'istanza database, otterrai due endpoint, uno per lo scrittore e uno per il lettore. L'endpoint di lettura fornisce il supporto per il bilanciamento del carico per le connessioni di sola lettura al cluster di database. I seguenti endpoint sono presi dalla nostra configurazione di test:
- scrittore - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- lettore - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
Nel nostro test, abbiamo utilizzato le seguenti specifiche Aurora:
- Tipo di istanza:db.r5.large
- Versione MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Replica multi-AZ:Sì
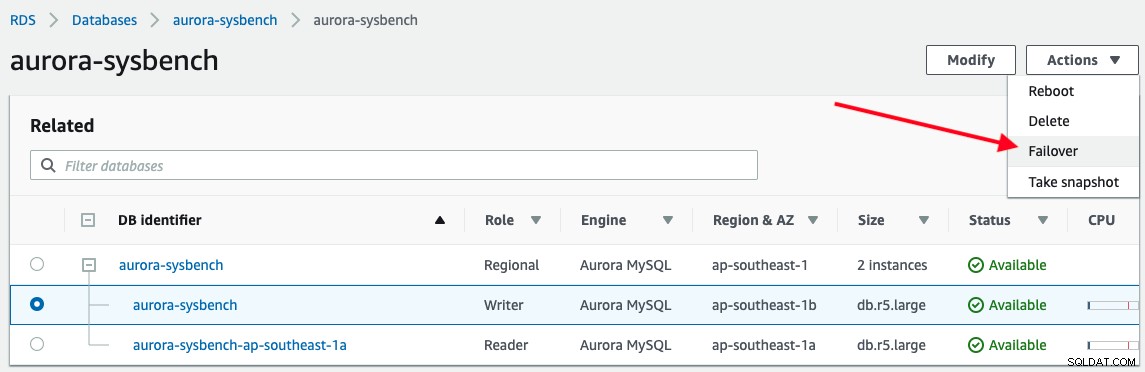
Per attivare un failover, seleziona semplicemente l'istanza del writer -> Azioni -> Failover, come mostrato nella schermata seguente:
Il seguente output viene segnalato dalla nostra applicazione durante la connessione all'endpoint del writer Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Il tempo di inattività del database è iniziato alle 12:35:49 fino alle 12:35:56 con un importo totale di 7 secondi. È piuttosto impressionante.
Osservando l'evento del database dalla console di gestione Aurora, si sono verificati solo questi due eventi:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedNon ci vuole molto tempo prima che Aurora promuova uno schiavo a diventare un padrone e declassi il padrone a diventare uno schiavo. Tieni presente che tutte le repliche di Aurora condividono lo stesso volume sottostante con l'istanza primaria e ciò significa che la replica può essere eseguita in millisecondi poiché gli aggiornamenti effettuati dall'istanza primaria sono immediatamente disponibili per tutte le repliche di Aurora. Pertanto, ha un ritardo di replica minimo (Amazon ha affermato di essere di 100 millisecondi e meno). Ciò ridurrà notevolmente il tempo di controllo dello stato di salute e migliorerà notevolmente il tempo di recupero.
Failover con ClusterControl
In questo esempio, imitiamo una configurazione simile con Amazon RDS utilizzando istanze m5.xlarge, con un ProxySQL in mezzo per automatizzare il failover dall'applicazione utilizzando un unico accesso all'endpoint, proprio come RDS. Il diagramma seguente illustra la nostra architettura:
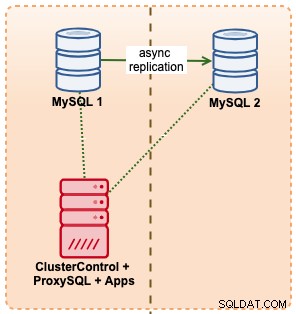
Dato che abbiamo accesso diretto alle istanze del database, attiveremmo un failover automatico semplicemente interrompendo il processo MySQL sul master attivo:
$ kill -9 $(pidof mysqld)Il comando precedente ha attivato un ripristino automatico all'interno di ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Mentre dal nostro punto di vista dell'applicazione di test, il tempo di inattività si è verificato nel momento seguente durante la connessione alla porta host ProxySQL 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Osservando sia gli eventi del processo di ripristino che l'output della nostra applicazione, il nodo del database MySQL era inattivo 4 secondi prima dell'inizio del processo di ripristino del cluster, dalle 11:08:28 alle 11:08:39, con un tempo di inattività MySQL totale di 11 secondi . Una delle cose più impressionanti di ClusterControl è che puoi tenere traccia dell'avanzamento del ripristino in base all'azione intrapresa ed eseguita da ClusterControl durante il failover. Fornisce un livello di trasparenza che non sarai in grado di ottenere con le offerte di database dei fornitori di servizi cloud.
Per la replica MySQL/MariaDB/PostgreSQL, ClusterControl ti consente di avere una maggiore precisione rispetto ai tuoi database con il supporto della configurazione e dei parametri avanzati seguenti:
- Gestione della topologia di replica master-master
- Gestione della topologia della replica a catena
- Visualizzatore di topologia
- Slave whitelist/blacklist da promuovere come master
- Controllo transazione errata
- Gli eventi pre/post, failover/switchover di successo/fallito si collegano a uno script esterno
- Rigenerazione automatica dello slave in caso di errore
- Espandi lo slave dal backup esistente
Riepilogo tempo di failover
In termini di tempo di failover, Amazon RDS Aurora per MySQL è il chiaro vincitore con 7 secondi , seguito da ClusterControl 11 secondi e Amazon RDS per MySQL con 27 secondi .
Tieni presente che questo è solo un semplice test, con un client e una transazione al secondo per misurare il tempo di ripristino più veloce. Transazioni di grandi dimensioni o un lungo processo di ripristino possono aumentare i tempi di failover, ad esempio, transazioni di lunga durata potrebbero richiedere molto tempo per tornare indietro quando si spegne MySQL.