Questo post fa parte di una serie di articoli sugli obiettivi di fila. Puoi trovare la prima parte qui:
- Parte 1:definizione e identificazione degli obiettivi di riga
È relativamente noto che usando TOP o un FAST n il suggerimento per la query può impostare un obiettivo di riga in un piano di esecuzione (consultare Impostazione e identificazione di obiettivi di riga nei piani di esecuzione se è necessario un aggiornamento sugli obiettivi di riga e sulle relative cause). È piuttosto meno comunemente apprezzato che anche i semi join (e gli anti join) possano introdurre un obiettivo di riga, sebbene ciò sia un po' meno probabile di quanto non avvenga per TOP , FAST e SET ROWCOUNT .
Questo articolo ti aiuterà a capire quando e perché un semi join richiama la logica dell'obiettivo di riga dell'ottimizzatore.
Semi join
Un semi join restituisce una riga da un input di join (A) se ce n'è almeno uno riga corrispondente sull'altro input di join (B).
Le differenze essenziali tra un semi join e un join regolare sono:
- Il semi join restituisce ciascuna riga dall'input A, oppure no. Non può verificarsi alcuna duplicazione di righe.
- L'unione regolare duplica le righe se sono presenti più corrispondenze nel predicato dell'unione.
- Il semi join è definito per restituire solo colonne dall'input A.
- Il join normale può restituire colonne da uno (o da entrambi) input di join.
Attualmente T-SQL non supporta la sintassi diretta come FROM A SEMI JOIN B ON A.x = B.y , quindi dobbiamo usare moduli indiretti come EXISTS , SOME/ANY (incluso l'equivalente abbreviazione IN per i confronti di uguaglianza) e impostare INTERSECT .
La descrizione di un semi join sopra suggerisce naturalmente l'applicazione di un goal di riga, poiché siamo interessati a trovare qualsiasi riga corrispondente in B, non tutte queste righe . Tuttavia, un semi join logico espresso in T-SQL potrebbe non portare a un piano di esecuzione che utilizza un obiettivo di riga per diversi motivi, che decomprimeremo in seguito.
Trasformazione e semplificazione
Un semi join logico potrebbe essere semplificato o sostituito con qualcos'altro durante la compilazione e l'ottimizzazione delle query. L'esempio AdventureWorks riportato di seguito mostra un semi join completamente rimosso, a causa di una relazione di chiave esterna affidabile:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
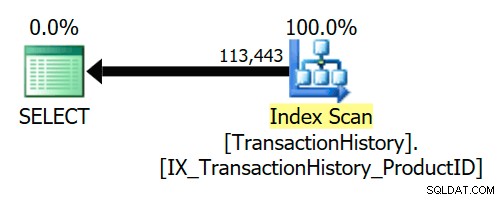
La chiave esterna garantisce che Product le righe esisteranno sempre per ogni riga della cronologia. Di conseguenza, il piano di esecuzione accede solo a TransactionHistory tabella:
Un esempio più comune si ha quando il semi join può essere trasformato in un inner join. Ad esempio:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
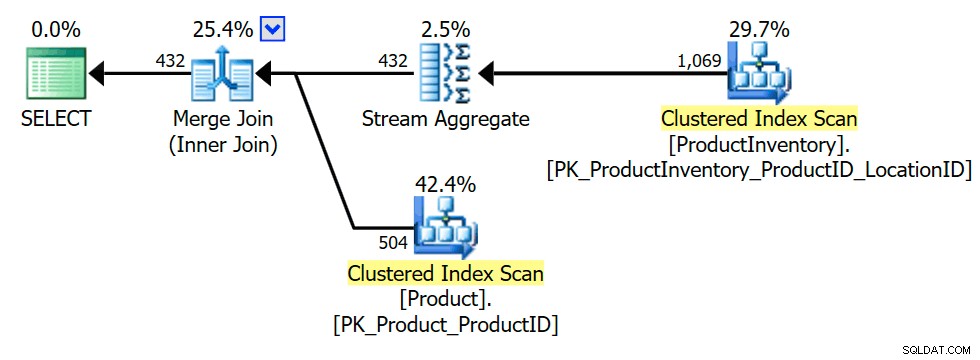
Il piano di esecuzione mostra che l'ottimizzatore ha introdotto un aggregato (raggruppamento su INV.ProductID ) per garantire che il join interno possa restituire solo Product righe una volta o per niente (come richiesto per preservare la semantica del semi join):
La trasformazione in inner join viene esplorata in anticipo perché l'ottimizzatore conosce più trucchi per gli inner equijoin che per i semi join, portando potenzialmente a maggiori opportunità di ottimizzazione. Naturalmente, la scelta del piano finale è ancora una decisione basata sui costi tra le alternative esplorate.
Ottimizzazioni anticipate
Sebbene T-SQL manchi di SEMI JOIN diretto sintassi, l'ottimizzatore sa tutto sui semi join in modo nativo e può manipolarli direttamente. Le comuni sintassi dei semi join per la soluzione alternativa vengono trasformate in un semi join interno "reale" all'inizio del processo di compilazione della query (molto prima che venga preso in considerazione anche un piano banale).
I due principali gruppi di sintassi per la soluzione alternativa sono EXISTS/INTERSECT e ANY/SOME/IN . Il EXISTS e INTERSECT i casi differiscono solo per il fatto che quest'ultimo viene fornito con un implicito DISTINCT (raggruppamento su tutte le colonne proiettate). Entrambi EXISTS e INTERSECT vengono analizzati come EXISTS con sottoquery correlata. Il ANY/SOME/IN le rappresentazioni sono tutte interpretate come ALCUNA operazione. Possiamo esplorare all'inizio questa attività di ottimizzazione con alcuni flag di traccia non documentati, che inviano informazioni sull'attività dell'ottimizzatore alla scheda dei messaggi SSMS.
Ad esempio, il semi join che abbiamo usato finora può anche essere scritto usando IN :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); L'albero di input dell'ottimizzatore è il seguente:

L'operatore scalare ScaOp_SomeComp è il SOME confronto appena menzionato. Il 2 è il codice per un test di uguaglianza, poiché IN è equivalente a = SOME . Se sei interessato, ci sono codici da 1 a 6 che rappresentano rispettivamente gli operatori di confronto (<, =, <=,>, !=,>=).
Tornando a EXISTS sintassi che preferisco usare più spesso per esprimere indirettamente un semi join:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); L'albero di input dell'ottimizzatore è:

Quell'albero è una traduzione abbastanza diretta del testo della query; tuttavia si noti che il SELECT * è già stato sostituito da una proiezione del valore intero costante 1 (vedi penultima riga di testo).
La prossima cosa che fa l'ottimizzatore è annullare l'annidamento della sottoquery nella selezione relazionale (=filtro) usando la regola RemoveSubqInSel . L'ottimizzatore esegue sempre questa operazione, poiché non può operare direttamente sulle sottoquery. Il risultato è una applicazione (aka unione correlata o laterale):

(La stessa regola di rimozione delle sottoquery produce lo stesso output per SOME anche l'albero di input).
Il passaggio successivo consiste nel riscrivere l'applicazione come un normale join utilizzando ApplyHandler governare la famiglia. Questo è qualcosa che l'ottimizzatore cerca sempre di fare, perché ha più regole di esplorazione per i join che per l'applicazione. Non tutte le candidature possono essere riscritte come join, ma l'esempio corrente è semplice e ha esito positivo:

Si noti che il tipo di unione è a sinistra semi. In effetti, questo è esattamente lo stesso albero che otterremmo immediatamente se T-SQL supportasse una sintassi come:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; Sarebbe bello poter esprimere domande in modo più diretto in questo modo. Ad ogni modo, il lettore interessato è incoraggiato a esplorare le attività di semplificazione di cui sopra con altri modi logicamente equivalenti di scrivere questo semi join in T-SQL.
L'importante in questa fase è che l'ottimizzatore rimuove sempre le sottoquery , sostituendoli con un'applicazione. Quindi prova a riscrivere l'applicazione come un normale join per massimizzare le possibilità di trovare un buon piano. Ricorda che tutto quanto precede avviene prima che venga preso in considerazione anche un piano banale. Durante l'ottimizzazione basata sui costi, l'ottimizzatore può anche prendere in considerazione la possibilità di unire la trasformazione in un'applicazione.
Hash e unisci semi join
SQL Server dispone di tre principali opzioni di implementazione fisica disponibili per un semi join logico. Finché è presente un predicato equijoin, sono disponibili hash e merge join; entrambi possono operare in modalità semi join sinistro e destro. Il join di loop nidificato supporta solo il semi join sinistro (non destro), ma non richiede un predicato equijoin. Diamo un'occhiata all'hash e alle opzioni fisiche di unione per la nostra query di esempio (scritta come un insieme si interseca questa volta):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
L'ottimizzatore può trovare un piano per tutte e quattro le combinazioni di semi join (sinistra/destra) e (cancelletto/unione) per questa query:
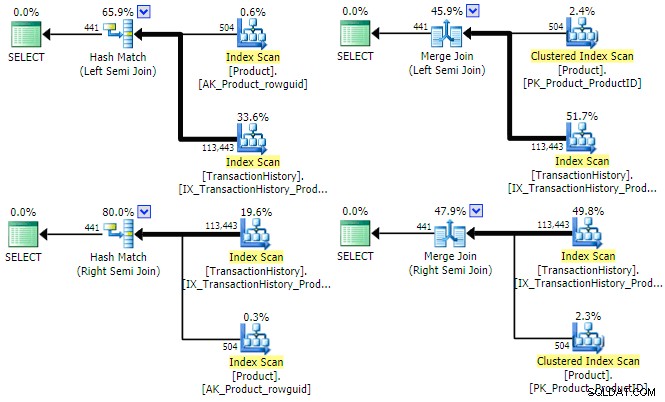
Vale la pena menzionare brevemente il motivo per cui l'ottimizzatore potrebbe considerare sia i semi join sinistro che destro per ogni tipo di join. Per hash semi join, un'importante considerazione sui costi è la dimensione stimata della tabella hash, che inizialmente è sempre l'input sinistro (superiore). Per merge semi join, le proprietà di ciascun input determinano se verrà utilizzata un'unione uno-a-molti o meno efficiente molti-a-molti con il tavolo di lavoro.
Potrebbe essere evidente dai piani di esecuzione di cui sopra che né hash né merge semi join trarrebbero vantaggio dall'impostazione di un obiettivo di riga . Entrambi i tipi di join verificano sempre il predicato di join nel join stesso e mirano a utilizzare tutte le righe da entrambi gli input per restituire un set di risultati completo. Ciò non significa che non esistano ottimizzazioni delle prestazioni per hash e merge join in generale, ad esempio, entrambi possono utilizzare bitmap per ridurre il numero di righe che raggiungono il join. Piuttosto, il punto è che un obiettivo di riga su uno dei due input non renderebbe più efficiente un hash o un merge semi join.
Cicli annidati e applica semi join
Il restante tipo di join fisico è nidificato loop, disponibile in due versioni:loop nidificati regolari (non correlati) e applica cicli nidificati (a volte indicati anche come correlati o laterale unisciti).
L'unione di cicli nidificati regolari è simile all'hash e all'unione di unione in quanto il predicato di unione viene valutato al momento dell'unione. Come prima, questo significa che non c'è alcun valore nell'impostare un obiettivo di riga su nessuno dei due input. L'input sinistro (superiore) alla fine verrà sempre consumato completamente e l'input interno non ha modo di determinare a quale riga (o righe) deve essere assegnata la priorità, poiché non possiamo sapere se una riga si unirà o meno fino a quando il predicato non viene testato al join .
Al contrario, un join di loop nidificato applicato ha uno o più riferimenti esterni (parametri correlati) al join, con il predicato join premuto il lato interno (inferiore) dell'unione. Questo crea un'opportunità per l'utile applicazione di un goal di fila. Ricordiamo che un semi join richiede solo di verificare l'esistenza di una riga sull'input di join B che corrisponda alla riga corrente sull'input di join A (pensando solo alle strategie di join dei loop nidificati ora).
In altre parole, ad ogni iterazione di un'applicazione, possiamo smettere di guardare l'input B non appena viene trovata la prima corrispondenza, usando il predicato join push-down. Questo è esattamente il genere di cose per cui è utile un obiettivo di riga:generare parte di un piano ottimizzato per restituire rapidamente le prime n righe corrispondenti (dove n = 1 qui).
Naturalmente, un goal di fila può essere una buona cosa o meno, a seconda delle circostanze. Non c'è niente di speciale nell'obiettivo di semi join a questo proposito. Si consideri una situazione in cui il lato interno del semi join è più complesso di un singolo semplice accesso a una tabella, ad esempio un join multi-tabella. L'impostazione di un obiettivo di riga può aiutare l'ottimizzatore a selezionare una strategia di navigazione efficiente solo per quel particolare sottoalbero , trovando la prima riga corrispondente per soddisfare il semi join tramite i join di loop nidificati e le ricerche di indice. Senza l'obiettivo di riga, l'ottimizzatore potrebbe naturalmente scegliere l'hash o unire i join con gli ordinamenti per ridurre al minimo il costo previsto per la restituzione di tutte le righe possibili. Nota che c'è un presupposto qui, vale a dire che le persone in genere scrivono semi join con l'aspettativa che esista effettivamente una riga che corrisponde alla condizione di ricerca. Questo mi sembra un presupposto abbastanza corretto.
In ogni caso, il punto importante in questa fase è:Solo applicare l'unione di loop nidificati ha un obiettivo di riga applicato dall'ottimizzatore (ricorda, tuttavia, un obiettivo di riga per l'applicazione di loop nidificati join viene aggiunto solo se l'obiettivo di riga è inferiore alla stima senza di esso). Esamineremo un paio di esempi concreti per chiarire tutto questo in seguito.
Esempi di semi join di loop nidificati
Lo script seguente crea due tabelle temporanee dell'heap. Il primo ha numeri da 1 a 20 inclusi; l'altro ha 10 copie di ogni numero nella prima tabella:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; Senza indici e un numero relativamente piccolo di righe, l'ottimizzatore sceglie un'implementazione di cicli nidificati (anziché hash o merge) per la seguente query di semi join). I flag di traccia non documentati ci consentono di vedere l'albero di output dell'ottimizzatore e le informazioni sugli obiettivi di riga:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
Il piano di esecuzione stimato prevede un join di cicli annidati semi join, con 200 righe per scansione completa della tabella #E2 . Le 20 iterazioni del ciclo danno una stima totale di 4.000 righe:
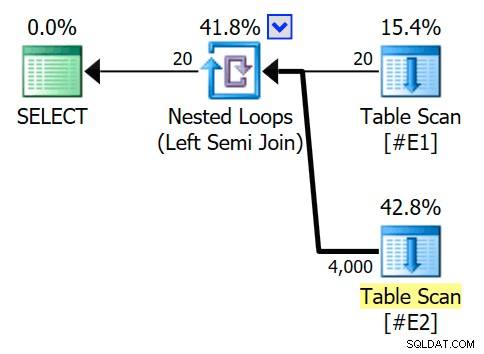
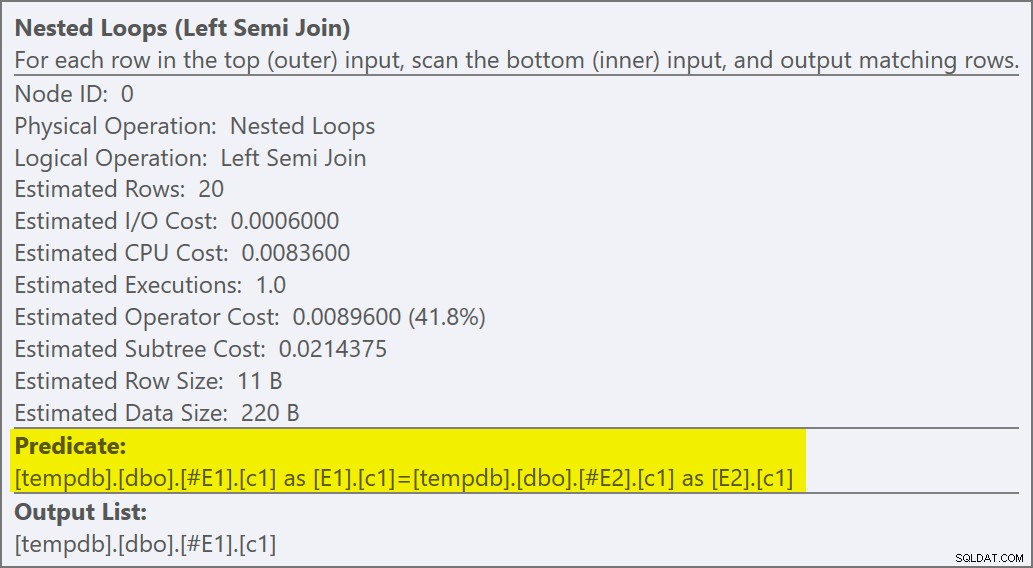
Le proprietà dell'operatore dei cicli annidati mostrano che il predicato viene applicato al join il che significa che si tratta di un unione di loop nidificati non correlati :
L'output del flag di traccia (nella scheda dei messaggi SSMS) mostra un semi join di loop nidificati e nessun obiettivo di riga (RowGoal 0):

Si noti che il piano di post-esecuzione per questa query sui giocattoli non mostrerà 4.000 righe lette dalla tabella #E2 in totale. I semi join dei cicli nidificati (correlati o meno) smetteranno di cercare più righe sul lato interno (per iterazione) non appena viene rilevata la prima corrispondenza per la riga esterna corrente. Ora, l'ordine delle righe rilevato dalla scansione dell'heap di #E2 su ogni iterazione non è deterministico (e può essere diverso su ogni iterazione), quindi in linea di principio quasi tutte le righe potrebbero essere testate ad ogni iterazione, nel caso in cui la riga corrispondente venga incontrata il più tardi possibile (o addirittura, nel caso di nessuna riga corrispondente, per niente).
Ad esempio, se assumiamo un'implementazione di runtime in cui le righe vengono scansionate nello stesso ordine (ad es. "ordine di inserzione") ogni volta, il numero totale di righe scansionate in questo esempio di giocattolo sarebbe 20 righe alla prima iterazione, 1 riga alla seconda iterazione, 2 righe alla terza iterazione e così via per un totale di 20 + 1 + 2 + (…) + 19 =210 righe. In effetti, è molto probabile che osservi questo totale, che dice di più sui limiti del semplice codice dimostrativo che su qualsiasi altra cosa. Non si può fare affidamento sull'ordine delle righe restituite da un metodo di accesso non ordinato più di quanto si possa fare affidamento sull'output apparentemente ordinato di una query senza un ORDER BY di livello superiore clausola.
Applica semi join
Ora creiamo un indice non cluster sulla tabella più grande (per incoraggiare l'ottimizzatore a scegliere un semi join applicato) ed eseguiamo nuovamente la query:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); Il piano di esecuzione ora presenta un semi join applicato, con 1 riga per ricerca dell'indice (e 20 iterazioni come prima):
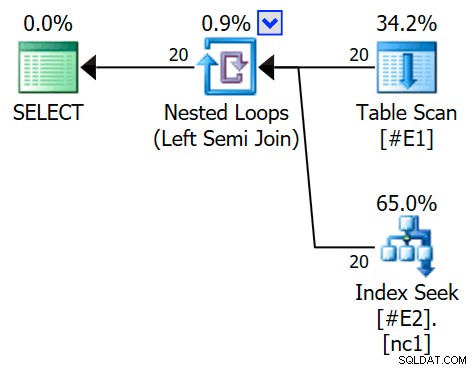
Possiamo dire che è un applica semi join perché le proprietà del join mostrano un riferimento esterno piuttosto che un predicato join:
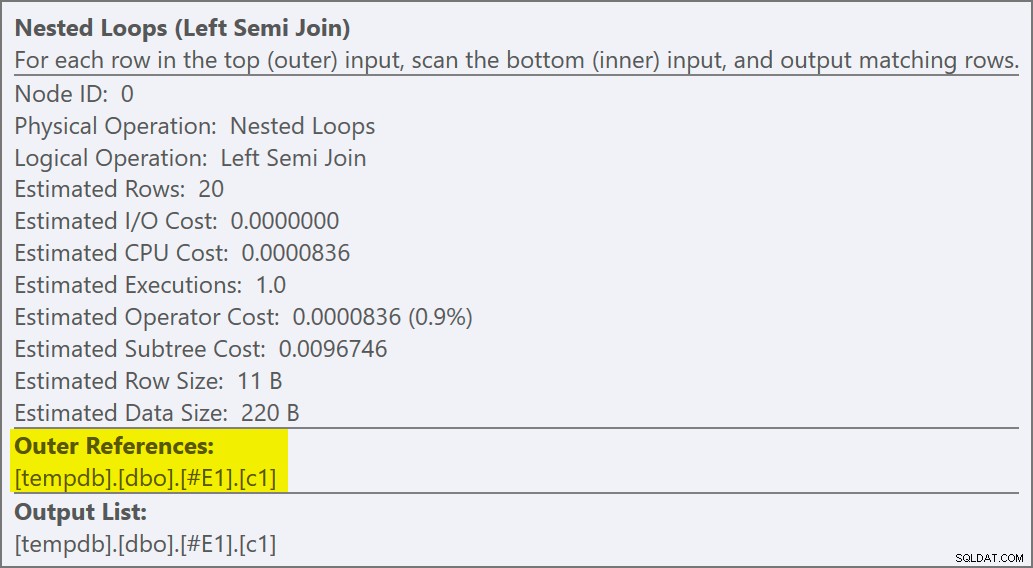
Il predicato di unione è stato abbassato il lato interno della domanda e abbinato al nuovo indice:
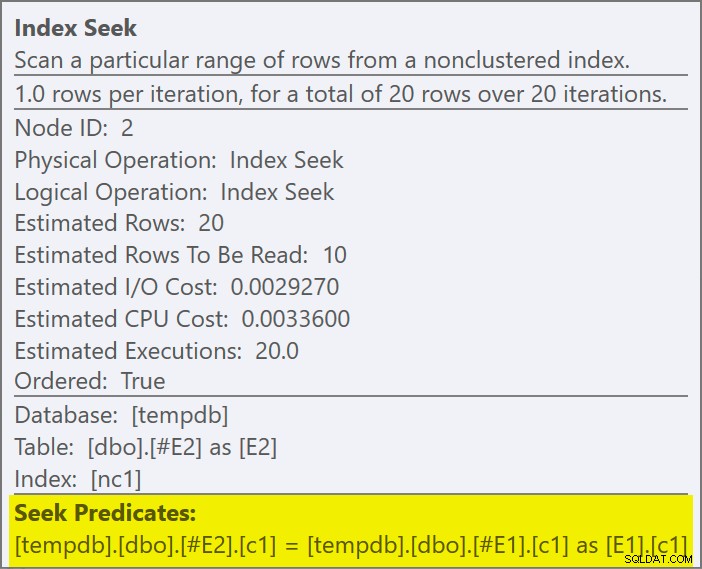
Ogni ricerca dovrebbe restituire 1 riga, nonostante ogni valore sia duplicato 10 volte in quella tabella; questo è un effetto dell'obiettivo di riga . L'obiettivo della riga sarà più facile da identificare nelle build di SQL Server che espongono EstimateRowsWithoutRowGoal attributo plan (SQL Server 2017 CU3 al momento della scrittura). In una prossima versione di Plan Explorer, questo sarà esposto anche nei suggerimenti per gli operatori interessati:

L'output del flag di traccia è:
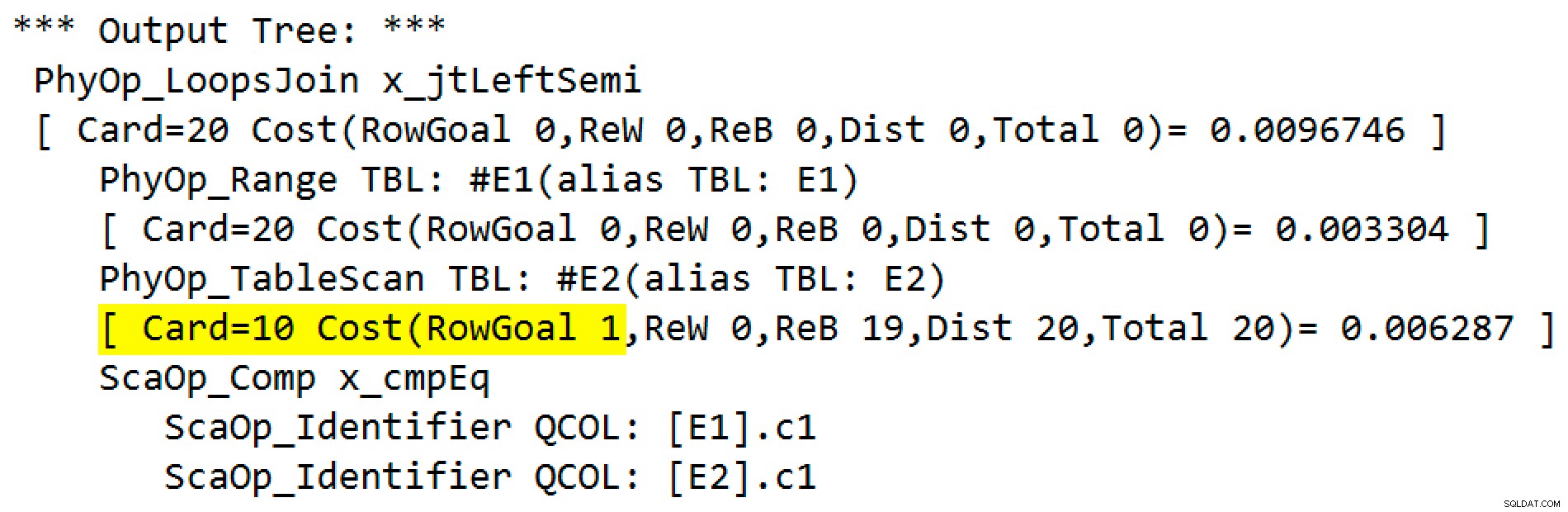
L'operatore fisico è cambiato da un join loop a un'applicazione in esecuzione in modalità semi join sinistro. Accesso alla tabella #E2 ha acquisito un goal di fila di 1 (la cardinalità senza il goal di fila è indicata come 10). L'obiettivo di riga non è un grosso problema in questo caso perché il costo per recuperare una stima di dieci righe per ricerca non è molto più che per una riga. Disabilitazione degli obiettivi di riga per questa query (utilizzando il flag di traccia 4138 o il DISABLE_OPTIMIZER_ROWGOAL suggerimento per la query) non cambierebbe la forma del piano.
Tuttavia, in query più realistiche, la riduzione dei costi dovuta all'obiettivo della riga interna può fare la differenza tra le opzioni di implementazione concorrenti. Ad esempio, la disabilitazione dell'obiettivo di riga potrebbe far sì che l'ottimizzatore scelga invece un hash o unisci semi join o una qualsiasi delle molte altre opzioni considerate per la query. Se non altro, l'obiettivo della riga qui riflette accuratamente il fatto che un semi join applicato interromperà la ricerca nel lato interno non appena viene trovata la prima corrispondenza e passerà alla riga del lato esterno successivo.
Nota che i duplicati sono stati creati nella tabella #E2 in modo che l'obiettivo di applicare la riga semi join (1) sia inferiore alla stima normale (10, dalle informazioni sulla densità delle statistiche). Se non sono presenti duplicati, la stima di riga per ogni ricerca in #E2 sarebbe anche 1 riga, quindi un obiettivo di riga di 1 non verrebbe applicato (ricorda la regola generale su questo!)
Obiettivi di fila rispetto ai migliori
Dato che i piani di esecuzione non indicano affatto la presenza di un obiettivo di riga prima di SQL Server 2017 CU3, si potrebbe pensare che sarebbe stato più chiaro implementare questa ottimizzazione usando un operatore Top esplicito, piuttosto che una proprietà nascosta come un obiettivo di riga. L'idea sarebbe quella di posizionare semplicemente un operatore Top (1) sul lato interno di un semi/anti join applicato invece di impostare un obiettivo di riga al join stesso.
L'utilizzo di un operatore Top in questo modo non sarebbe stato del tutto privo di precedenti. Ad esempio, esiste già una versione speciale di Top, nota come numero massimo di righe visualizzato nei piani di esecuzione della modifica dei dati quando un SET ROWCOUNT diverso da zero è in vigore (si noti che questo utilizzo specifico è stato deprecato dal 2005 sebbene sia ancora consentito in SQL Server 2017). L'implementazione dell'inizio del conteggio delle righe è un po' goffa in quanto l'operatore principale viene sempre mostrato come Primo (0) nel piano di esecuzione, indipendentemente dal limite di conteggio delle righe effettivo in vigore.
Non vi è alcun motivo convincente per cui l'obiettivo di riga applica semi join non può essere stato sostituito con un operatore Top (1) esplicito. Detto questo, ci sono alcuni motivi per preferire non farlo:
- L'aggiunta di un Top esplicito (1) richiede un maggiore sforzo di codifica e test dell'ottimizzatore rispetto all'aggiunta di un obiettivo di riga (che è già utilizzato per altre cose).
- Top non è un operatore relazionale; l'ottimizzatore ha scarso supporto per ragionare al riguardo. Ciò potrebbe influire negativamente sulla qualità del piano limitando la capacità dell'ottimizzatore di trasformare parti di un piano di query, ad es. spostando aggregati, unioni, filtri e join.
- Introdurrebbe uno stretto accoppiamento tra l'implementazione applicata del semi join e la parte superiore. Casi speciali e accoppiamento stretto sono ottimi modi per introdurre bug e rendere le modifiche future più difficili e soggette a errori.
- Il Top (1) sarebbe logicamente ridondante e presente solo per il suo effetto collaterale del goal di fila.
Vale la pena approfondire quest'ultimo punto con un esempio:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
Il TOP (1) nella sottoquery esistente viene semplificata dall'ottimizzatore, fornendo un semplice piano di esecuzione semi join:
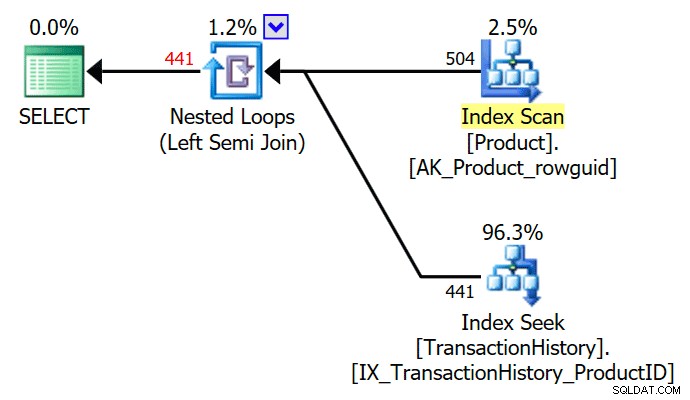
L'ottimizzatore può anche rimuovere un DISTINCT ridondante o GROUP BY nella sottoquery. I seguenti producono tutti lo stesso piano di cui sopra:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Riepilogo e considerazioni finali
Solo applica il semi join dei loop nidificati può avere un obiettivo di riga impostato dall'ottimizzatore. Questo è l'unico tipo di join che spinge i predicati di join verso il basso dal join, consentendo di eseguire il test dell'esistenza di una corrispondenza in anticipo . I loop nidificati non correlati si uniscono a semi quasi mai* imposta un obiettivo di riga e nemmeno un hash o un merge semi join. I loop nidificati Applica possono essere distinti dai loop nidificati non correlati uniti dalla presenza di riferimenti esterni (anziché un predicato) sull'operatore di join dei cicli nidificati per un'applicazione.
Le possibilità di vedere un semi join applicato nel piano di esecuzione finale dipendono in qualche modo dall'attività di ottimizzazione iniziale. In mancanza di sintassi T-SQL diretta, dobbiamo esprimere semi join in termini indiretti. Questi vengono analizzati in un albero logico contenente una sottoquery, che l'attività dell'ottimizzatore iniziale trasforma in un'applicazione e quindi in un semi join non correlato, ove possibile.
Questa attività di semplificazione determina se un semi join logico viene presentato all'ottimizzatore basato sui costi come un semi join applicato o regolare. Quando presentato come una applicazione logica semi join, il CBO è quasi certo di produrre un piano di esecuzione finale con cicli di applicazione nidificati fisici (e quindi l'impostazione di un obiettivo di riga). Quando viene presentato con un semi join non correlato, il CBO può considerare la trasformazione in una candidatura (o potrebbe non esserlo). La scelta finale del piano consiste, come al solito, in una serie di decisioni basate sui costi.
Come tutti i goal di fila, il goal di semi join può essere positivo o negativo per le prestazioni. Sapere che un'applicazione semi join imposta un obiettivo di riga aiuterà almeno le persone a riconoscere e affrontare la causa se dovesse verificarsi un problema. La soluzione non sarà sempre (o anche di solito) disabilitare gli obiettivi di riga per la query. È spesso possibile apportare miglioramenti all'indicizzazione (e/o alla query) per fornire un modo efficiente per individuare la prima riga corrispondente.
Tratterò gli anti semi join in un articolo separato, continuando la serie di goal di fila.
* L'eccezione è un semi join di cicli annidati non correlato senza predicato di join (una vista non comune). Questo imposta un obiettivo di fila.