Le viste indicizzate possono essere create in qualsiasi edizione di SQL Server, ma ci sono una serie di comportamenti da tenere presenti se vuoi sfruttarle al meglio.
Le statistiche automatiche richiedono un suggerimento NOEXPAND
SQL ServerSQL Server può creare statistiche automaticamente per facilitare la stima della cardinalità e il processo decisionale basato sui costi durante l'ottimizzazione delle query. Questa funzione funziona sia con le viste indicizzate che con le tabelle di base, ma solo se la vista è nominata esplicitamente nella query e nel NOEXPAND suggerimento è specificato. (C'è sempre un oggetto statistiche associato a ciascun indice in una vista, è la generazione e il mantenimento automatici di statistiche non associate a un indice di cui stiamo parlando qui.)
Se sei abituato a lavorare con edizioni non Enterprise di SQL Server, potresti non aver mai notato questo comportamento prima. Le edizioni inferiori di SQL Server richiedono NOEXPAND suggerimento per produrre un piano di query che acceda a una vista indicizzata. Quando NOEXPAND viene specificato, le statistiche automatiche vengono create sulle viste indicizzate esattamente come accade con le normali tabelle.
Esempio – Edizione Standard con NOEXPAND
Utilizzando SQL Server 2012 Standard Edition e il database di esempio Adventure Works, creiamo innanzitutto una vista che unisce due tabelle di vendita e calcola la quantità totale dell'ordine per cliente e prodotto:
CREATE VIEW dbo.CustomerOrders
WITH SCHEMABINDING AS
SELECT
SOH.CustomerID,
SOD.ProductID,
OrderQty = SUM(SOD.OrderQty),
NumRows = COUNT_BIG(*)
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY
SOH.CustomerID,
SOD.ProductID; Affinché questa vista supporti le statistiche, è necessario materializzarla aggiungendo un indice cluster univoco. La combinazione di Customer e Product ID è garantita per essere univoca nella vista (per definizione), quindi la useremo come chiave. Potremmo specificare le due colonne in entrambi i modi nell'indice, ma supponendo che ci aspettiamo più query per filtrare per prodotto, rendiamo Product ID la colonna principale. Questa azione crea anche statistiche sull'indice, con un istogramma costruito dai valori dell'ID prodotto.
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
Ora ci viene chiesto di scrivere una query che mostri la quantità totale di ordini per cliente, per una particolare gamma di prodotti. Ci aspettiamo che un piano di esecuzione che utilizzi la vista indicizzata sarà una strategia efficace, perché eviterà un join e opererà su dati già parzialmente aggregati. Poiché utilizziamo SQL Server Standard Edition, dobbiamo specificare esplicitamente la vista e utilizzare un NOEXPAND suggerimento per produrre un piano di query che acceda alla vista indicizzata:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
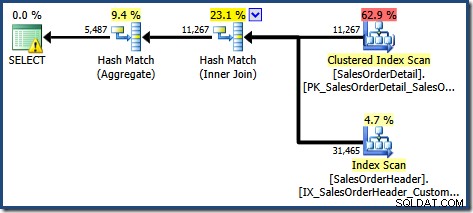
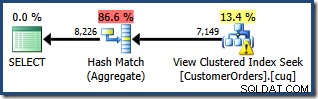
CO.CustomerID; Il piano di esecuzione prodotto mostra una ricerca sulla vista indicizzata per trovare le righe per i prodotti di interesse, seguita da un'aggregazione per calcolare la quantità totale per cliente:
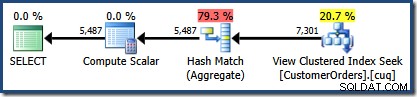
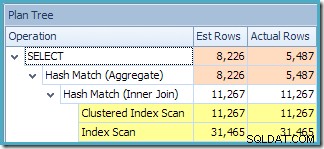
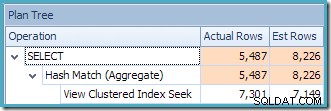
La vista Plan Tree di SQL Sentry Plan Explorer mostra che la stima della cardinalità è esattamente corretta per la ricerca della vista indicizzata e molto buona per il risultato dell'aggregazione:
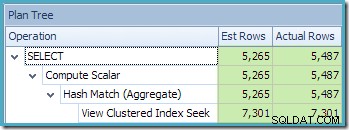
Nell'ambito del processo di compilazione e ottimizzazione per questa query, SQL Server ha creato un oggetto statistiche aggiuntivo nella colonna ID cliente della vista indicizzata. Questa statistica è costruita perché il numero e la distribuzione previsti degli ID cliente potrebbero essere importanti, ad esempio nella scelta di una strategia di aggregazione. Possiamo vedere la nuova statistica utilizzando Management Studio Object Explorer:
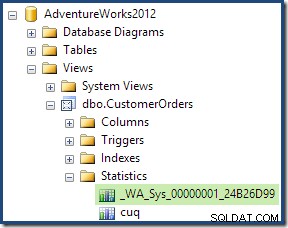
Facendo doppio clic sull'oggetto statistiche si conferma che è stato creato dalla colonna ID cliente nella vista (non una tabella di base):
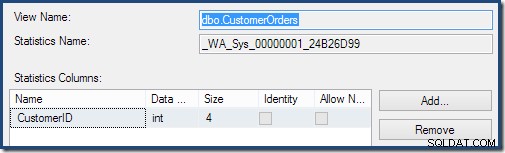
Le visualizzazioni indicizzate possono migliorare la stima della cardinalità
Sempre utilizzando la Standard Edition, ora rilasciamo e ricreiamo la vista indicizzata (che elimina anche le statistiche della vista) ed eseguiamo nuovamente la query, questa volta con NOEXPAND suggerimento commentato:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
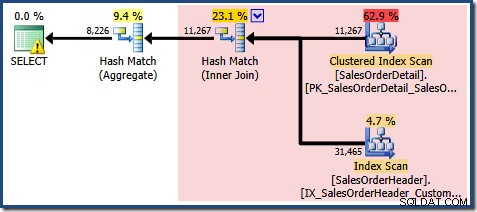
Come previsto quando si utilizza la Standard Edition senza NOEXPAND , il piano di query risultante opera sulle tabelle di base anziché direttamente sulla vista:

Il triangolo di avvertenza sull'operatore root nel piano sopra ci avvisa di un indice potenzialmente utile nella tabella dei dettagli dell'ordine di vendita, che non è importante per i nostri scopi attuali. Questa compilazione non crea alcuna statistica sulla vista indicizzata. L'unica statistica sulla vista dopo la compilazione della query è quella associata all'indice cluster:
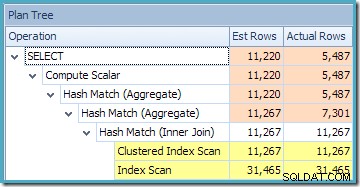
La vista Plan Tree per la query mostra che la stima della cardinalità è corretta per le due scansioni della tabella e il join, ma un po' peggio per gli altri operatori del piano:
Utilizzo della vista indicizzata con un NOEXPAND hint ha prodotto stime più accurate per la nostra query di test, perché le informazioni di migliore qualità erano disponibili dalle statistiche sulla vista, in particolare le statistiche associate all'indice della vista.
Come regola generale, l'accuratezza delle informazioni statistiche si riduce abbastanza rapidamente al passaggio e viene modificata dagli operatori del piano di query. I join semplici spesso non sono male in questo senso, ma le informazioni sul risultato di un'aggregazione spesso non sono migliori di un'ipotesi plausibile. Fornire a Query Optimizer informazioni più accurate utilizzando le statistiche sulle viste indicizzate può essere una tecnica utile per aumentare la qualità e la solidità del piano.
Una vista senza NOEXPAND può produrre un piano inferiore
Il piano di query mostrato sopra (edizione standard, senza NOEXPAND ) è in realtà meno ottimale rispetto a se avessimo scritto noi stessi la query sulle tabelle di base, anziché consentire a Query Optimizer di espandere la visualizzazione. La query seguente esprime lo stesso requisito logico, ma non fa riferimento alla vista:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID; Questa query produce il seguente piano di esecuzione:
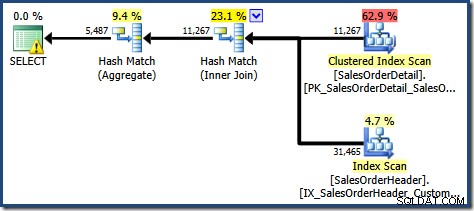
Questo piano prevede un'operazione di aggregazione in meno rispetto a prima. Quando è stata utilizzata l'espansione della vista, Query Optimizer purtroppo non è stato in grado di rimuovere un'operazione di aggregazione ridondante, risultando in un piano di esecuzione meno efficiente. Anche la stima della cardinalità finale per la nuova query è leggermente migliore rispetto a quando si faceva riferimento alla vista indicizzata senza NOEXPAND :
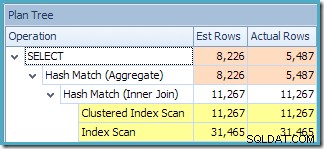
Tuttavia, le migliori stime sono ancora quelle prodotte quando si fa riferimento alla vista indicizzata con NOEXPAND (ripetuto di seguito per comodità):
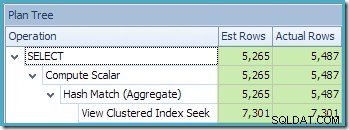
Enterprise Edition e Visualizza corrispondenza
In un'istanza Enterprise Edition, Query Optimizer potrebbe essere in grado di utilizzare una vista indicizzata anche se la query non menziona esplicitamente la vista. Se l'ottimizzatore è in grado di abbinare parte dell'albero delle query a una vista indicizzata, può scegliere di farlo in base alla sua stima dei costi di utilizzo o meno della vista. La logica di corrispondenza della vista è ragionevolmente intelligente, ma ha dei limiti che nella pratica sono abbastanza facili da raggiungere. Anche quando la corrispondenza delle viste ha esito positivo, l'ottimizzatore può comunque essere fuorviato da stime dei costi imprecise.
Il suggerimento per la query EXPAND VIEWS
A partire dalla più rara delle possibilità, potrebbero esserci occasioni in cui una query fa riferimento a una vista indicizzata, ma si otterrebbe invece un piano migliore accedendo alle tabelle di base. In queste circostanze, il suggerimento per la query EXPAND VIEWS può essere utilizzato:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID
OPTION (EXPAND VIEWS);
Su Enterprise Edition, questa query produce lo stesso piano visto su Standard Edition quando NOEXPAND suggerimento è stato omesso (inclusa l'operazione di aggregazione ridondante):

Per inciso, il EXPAND VIEWS suggerimento è mal chiamato, a mio parere. SQL Server espande sempre le definizioni di visualizzazione in una query a meno che non sia NOEXPAND suggerimento è specificato. Il EXPAND VIEWS hint disabilita le regole nell'ottimizzatore che possono far corrispondere parti dell'albero espanso alle viste indicizzate. In assenza di uno dei due suggerimenti, SQL Server espande prima una vista alla definizione della tabella di base, quindi considera la corrispondenza di nuovo con le viste indicizzate. Un nome migliore per EXPAND VIEWS il suggerimento potrebbe essere stato DISABLE INDEXED VIEW MATCHING , perché è quello che fa.
Il EXPAND VIEWS hint è probabilmente usato più spesso per impedire che una query sulle tabelle di base venga abbinata a una vista indicizzata:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID
OPTION (EXPAND VIEWS); L'hint per la query genera lo stesso piano di esecuzione e le stesse stime visti quando utilizzavamo l'edizione standard e la stessa query solo tabella di base:
Enterprise Visualizza corrispondenza e statistiche
Anche in Enterprise Edition, le statistiche di visualizzazione non indice vengono create solo se NOEXPAND viene utilizzato il suggerimento. Per essere assolutamente chiari, la funzione di corrispondenza delle viste solo Enterprise non comporta mai la creazione o l'aggiornamento delle statistiche delle viste. Vale la pena esplorare un po' questo comportamento non intuitivo, poiché può avere effetti collaterali sorprendenti.
Ora eseguiamo la nostra query di base sulla vista su un'istanza Enterprise Edition, senza alcun suggerimento:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
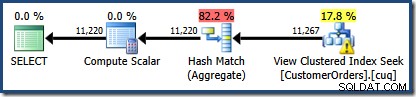
Una novità è il triangolo di avvertenza sulla ricerca dell'indice raggruppato di visualizzazione. Il suggerimento mostra i dettagli:
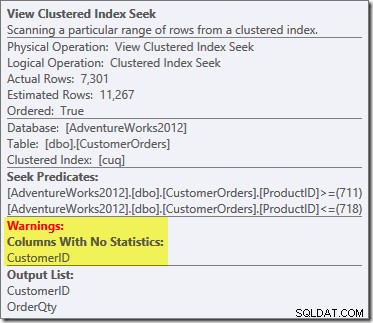
Non abbiamo utilizzato un NOEXPAND suggerimento, quindi le statistiche sulla colonna ID cliente della vista indicizzata non sono state create automaticamente. Le statistiche sull'ID cliente non sono in realtà molto importanti in questo esempio semplificato, ma non sarà sempre così.
Stime di cardinalità curiose
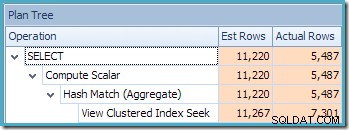
La seconda cosa interessante è che le stime della cardinalità sembrano essere peggiori di qualsiasi altro caso che abbiamo incontrato finora, inclusi gli esempi della Standard Edition.
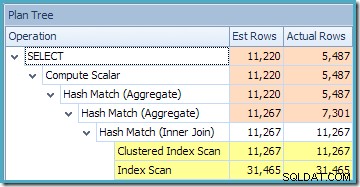
Inizialmente è difficile vedere da dove provenga la stima della cardinalità per View Clustered Index Seek (11.267). Ci si aspetterebbe che la stima si basi sulle informazioni dell'istogramma Product ID dalle statistiche associate all'indice di visualizzazione cluster. La parte rilevante di questo istogramma è mostrata di seguito:
DBCC SHOW_STATISTICS
('dbo.CustomerOrders', 'cuq')
WITH HISTOGRAM;
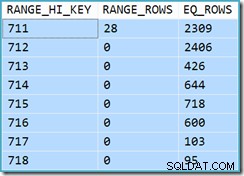
Dato che la tabella non è stata modificata da quando sono state create le statistiche, ci aspetteremmo che la stima fosse una semplice somma di RANGE_ROWS e EQ_ROWS per valori di ID prodotto compresi tra 711 e 718 (notare che la stima dovrebbe escludere le 28 RANGE_ROWS mostrate rispetto alla voce 711 poiché quelle righe esistono al di sotto del valore della chiave 711). La somma di EQ_ROWS mostrata è 7.301. Questo è esattamente il numero di righe effettivamente restituite dalla vista, quindi da dove viene la stima di 11.267?
La risposta sta nel modo in cui la corrispondenza delle viste funziona attualmente. La nostra query non ha specificato il NOEXPAND suggerimento, quindi le stime iniziali della cardinalità si basano sull'albero delle query con visualizzazione espansa. Questo è più facile da vedere guardando di nuovo il piano stimato per la stessa query con EXPAND VIEWS specificato:
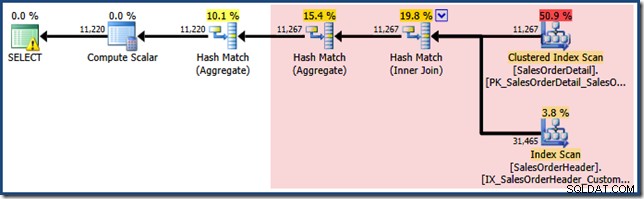
L'area ombreggiata in rosso rappresenta la parte dell'albero che viene sostituita dall'attività di corrispondenza delle viste. La cardinalità di output da quest'area è 11.267. La parte non ombreggiata con la stima di 11.220 non è influenzata dalla corrispondenza delle viste. Queste sono esattamente le stime che stavamo cercando di spiegare:
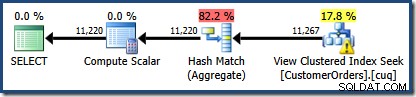
La corrispondenza della vista ha semplicemente sostituito l'area ombreggiata in rosso con una ricerca logicamente equivalente nella vista indicizzata. Non ha utilizzato le informazioni statistiche della vista per ricalcolare la stima della cardinalità.
In una certa misura, probabilmente puoi capire perché potrebbe funzionare in questo modo:in generale, non c'è motivo di aspettarsi che una stima calcolata da un insieme di informazioni statistiche sia migliore di un altro. Si potrebbe sostenere che è più probabile che le statistiche della vista indicizzata siano accurate qui, rispetto alle statistiche derivate dal post-unione nell'area ombreggiata in rosso, ma potrebbe essere difficile generalizzare ciò, o tenere conto correttamente della velocità con cui le varie fonti di le informazioni statistiche potrebbero non essere aggiornate poiché i dati sottostanti cambiano.
Si potrebbe anche sostenere che se fossimo così sicuri che le informazioni sulla vista indicizzata fossero migliori, avremmo usato un NOEXPAND suggerimento.
Stime di cardinalità ancora più curiose
Una situazione ancora più interessante si presenta con Enterprise Edition se scriviamo la query sulle tabelle di base e ci affidiamo alla corrispondenza automatica delle viste:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID;
L'avviso di statistiche mancanti è lo stesso di prima e ha la stessa spiegazione. La caratteristica più interessante è che ora abbiamo una stima più bassa per il numero di righe prodotte da View Clustered Index Seek (7.149) e una stima maggiore per il numero di righe restituite dall'aggregazione (8.226).
Per sottolineare il punto, questo piano di query sembra essere basato sull'idea che 7.149 righe di origine possono essere aggregate per produrre 8.226 righe!
Parte della spiegazione è la stessa di prima. Il EXPAND VIEWS il piano di query, che mostra la regione rossa che verrà sostituita dalla corrispondenza delle viste, è mostrato di seguito:
Questo spiega da dove viene la stima finale di 8.226, ma per quanto riguarda la stima di 7.149 righe? Seguendo la logica vista in precedenza, sembra che la vista debba mostrare una stima di 11.267 righe?
La risposta è che la stima di 7.149 è un'ipotesi. Sì davvero. La vista indicizzata contiene 79.433 righe in totale. La percentuale di ipotesi magica per il predicato ID prodotto BETWEEN è del 9%, ovvero 0,09 * 79433 =7148,97 righe. Il piano di query SSMS mostra che questo calcolo è esattamente corretto, anche prima dell'arrotondamento:
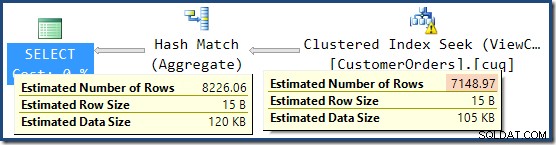
In questa situazione, l'ottimizzatore di SQL Server sembra aver preferito un'ipotesi basata sulla cardinalità della vista indicizzata rispetto alla stima della cardinalità post-unione dalla sottostruttura sostituita. Curioso.
Riepilogo
Usando il NOEXPAND hint garantisce che una vista indicizzata verrà utilizzata nel piano di query finale e consente la creazione, la gestione e l'utilizzo automatico di statistiche non indicizzate da Query Optimizer. Usando NOEXPAND assicura inoltre che le stime iniziali della cardinalità siano basate su informazioni di visualizzazione indicizzate anziché derivate da tabelle di base.
Se NOEXPAND non è specificato, i riferimenti alla vista vengono sempre sostituiti con le definizioni della tabella di base prima dell'inizio della compilazione della query (e quindi prima della stima della cardinalità iniziale). Solo negli SKU Enterprise, le viste indicizzate possono essere sostituite nell'albero delle query più avanti nel processo di ottimizzazione.
Il EXPAND VIEWS l'hint di query impedisce all'ottimizzatore di eseguire la corrispondenza della vista indicizzata Enterprise Edition. Ciò si applica indipendentemente dal fatto che la query facesse originariamente riferimento a una vista indicizzata o meno. Quando viene eseguita la corrispondenza delle viste, in alcune circostanze una stima della cardinalità esistente può essere sostituita con un'ipotesi.
Le statistiche mostrate come mancanti in una vista indicizzata possono essere create manualmente, ma l'ottimizzatore generalmente non le utilizza per le query che non utilizzano un NOEXPAND suggerimento.
L'uso di viste indicizzate può migliorare la stima della cardinalità, in particolare se la vista contiene join o aggregazioni. Le query hanno le migliori possibilità di beneficiare di statistiche di visualizzazione più accurate se NOEXPAND è specificato.