C'è molto da tenere a mente quando si progetta un database e pochissimi di noi possono ricordare tutti i preziosi suggerimenti e trucchi che abbiamo imparato. Quindi, diamo un'occhiata ad alcune risorse online che presentano suggerimenti e best practice per la progettazione di database. Mentre procediamo, condividerò le mie opinioni sulle idee presentate, sulla base della mia esperienza nella progettazione di database.
Ovviamente, questo articolo non è un elenco esaustivo, ma ho cercato di rivedere e commentare uno spaccato di fonti. Si spera che troverai le informazioni più adatte alle tue esigenze e ai tuoi obiettivi.
Come nota a margine, sono stato sorpreso di scoprire che molti articoli relativi alle pratiche di progettazione di database avevano pochissimi esempi; le risorse online che ho recensito per l'articolo sugli errori e gli errori ne avevano una percentuale più alta. Questa mancanza è uno svantaggio, perché gli esempi sono estremamente importanti per ottenere il punto.
Suggerimenti per il database per designer esperti
Innanzitutto, iniziamo con le fonti con suggerimenti e best practice per la progettazione di database avanzati. Questi sono per i progettisti che stanno già lavorando nella modellazione dei dati e lo sono stati per un po' di tempo. Alcuni articoli sono rivolti a un livello più intermedio, ma se trattano concetti avanzati, li ho inclusi in questo elenco.
Linee guida del database (RDBMS/SQL)
di Steve Djajasaputra | SOA, Java, Sviluppo software – BlogSpot | 16 gennaio 2013
Questo articolo del signor Djajasaputra è piuttosto impressionante:elenca numerosi suggerimenti per lo schema, gli indici e le viste; fornisce anche una convenzione di denominazione piuttosto dettagliata. E i suoi consigli continuano (e avanti). L'ampiezza è impressionante, ma non ci sono quasi esempi. Alcuni dei suoi punti potrebbero essere considerati discutibili, ma nel complesso questa è una presentazione molto solida.
In particolare, sono rimasto colpito dal fatto che fornisca una regola precisa sull'uso delle chiavi primarie naturali rispetto a quelle artificiali (cioè surrogate o generate). Lo mantiene bello e semplice, specificando che dovremmo preferire una chiave naturale perché è significativa. Fornisce inoltre le linee guida per il miglior uso di una chiave artificiale, in particolare quando la chiave naturale non è unica o quando è necessario modificare il valore della chiave naturale. Con le sue stesse parole:
Per prima cosa preferire utilizzare la chiave naturale poiché è più significativa e per evitare duplicazioni (riutilizza la colonna esistente). Ma ci sono casi in cui è necessaria una chiave artificiale:quando la chiave naturale non è univoca (es. nomi) o se è necessario modificare il valore.Dato che la sua lista di consigli è così lunga, non riesco a immaginare di ricordarmeli tutti. Tuttavia, è possibile fare riferimento a ciascuna sezione quando si lavora sulla progettazione del database, sulle prestazioni, sulle procedure archiviate e sul controllo delle versioni. C'è anche una sezione sui punti specifici di Oracle che sarebbe utile se stai lavorando o hai intenzione di supportare Oracle.
Tutto sommato, questa è una risorsa molto utile e completa.
9 suggerimenti per una migliore progettazione del database
di Jeffrey Edison | Blog verticale | 22 settembre 2015
Mi concederò una piccola autopromozione qui.
Questo articolo di 9 suggerimenti per una migliore progettazione del database si basa sulla mia esperienza come designer e architetto. Ho anche trovato ulteriori approfondimenti dalla ricerca delle migliori pratiche di altri per la progettazione di database.
Il mio elenco rappresenta alcuni dei principali problemi che possono verificarsi quando si lavora con i modelli di dati. Ho organizzato i suggerimenti nell'ordine in cui si verificano durante il ciclo di vita del progetto (piuttosto che in base all'importanza o alla frequenza con cui si presentano) poiché sarebbe molto utile, almeno a mio avviso. I lettori possono seguire questo elenco di controllo delle migliori pratiche durante il ciclo di vita di un progetto.
Dall'articolo:
Per parafrasare Al Capone (o John Van Buren, figlio dell'8° presidente degli Stati Uniti), “provate presto, provate spesso”. In questo modo segui il percorso dell'Integrazione Continua. Il test in una fase iniziale di sviluppo consente di risparmiare tempo e denaro. Nel testare il database, l'obiettivo dovrebbe essere quello di simulare un ambiente di produzione:"Un giorno nella vita del database". Quali volumi ci si può aspettare? Quali interazioni dell'utente sono probabili? I casi limite vengono gestiti?Prestando attenzione a questi suggerimenti, ho scoperto che i database diventano meglio progettati e più robusti. Sebbene nessuna di queste attività richieda un'enorme quantità di tempo, ognuna può avere un enorme impatto sulla qualità del tuo modello di dati.
Spero che il mio elenco di suggerimenti sia utile per designer di livello intermedio e avanzato.
20 best practice per la progettazione di database
di Cagdas Basaraner | Saldo del codice – BlogSpot | 24 luglio 2011
Mr. Basaraner ci presenta un interessante elenco di 20 migliori pratiche di progettazione di database. Avrei preferito che ne avesse raggruppati alcuni; ad esempio, i primi quattro elementi potrebbero essere tutti coperti in "Usa convenzioni di denominazione corretta".
Inoltre, afferma che l'utilizzo di un ID sintetico generato (intero) come chiave primaria di tutte le tabelle è una procedura consigliata. In realtà, questo è ancora un argomento dibattuto, con argomenti a favore e contro. Alcune delle sue migliori pratiche sono piuttosto generiche, come "Per ... sistemi di database mission critical [sic], utilizzare il ripristino di emergenza e il servizio di sicurezza ..." Non sono d'accordo con questo punto, ma è di livello molto alto.
Tra i lati positivi, questo articolo è stato uno dei pochi a menzionare l'utilizzo di un framework di mappatura relazionale a oggetti (ORM). Alcuni commentatori non erano d'accordo con come è stato formulato il suggerimento, ma almeno viene menzionato l'utilizzo di un framework ORM:
Utilizzare un framework ORM (mappatura relazionale degli oggetti) (ad esempio, Hibernate, iBatis ...) se il codice dell'applicazione è sufficientemente grande. I problemi di prestazioni dei framework ORM possono essere gestiti da parametri di configurazione dettagliati.Tuttavia, questo elenco avrebbe potuto essere migliorato. Dovrebbe identificare chiaramente i punti che sono specifici solo per alcuni sistemi di gestione di database (ad esempio SQL Server). Statistiche precise su prestazioni, euristica o importanza di dedicare tempo alla progettazione piuttosto che su manutenzione e ridisegnare sarebbe stato bello. Erano necessari anche altri esempi, ma questo è un problema per la maggior parte di questi articoli.
Se stai lavorando con SQL Server, stai pensando di utilizzare un framework ORM o hai bisogno di un elenco puntato di suggerimenti piuttosto che di un articolo lungo e dettagliato, allora questo pezzo fa per te.
(Nota:questo articolo è apparso anche su molti altri siti, inclusi CodeBuild, Java Code Geeks e DZone.)
Essenziali per la progettazione del database. 10 Cose che devi assolutamente fare
di Michelle A. Poolet | SQL Server Pro | 1 marzo 2011
Una parte dei suggerimenti della signora Poolet sono piuttosto standard e possono essere trovati in molte altre risorse, ma ci sono anche alcuni punti piuttosto insoliti. Tra i suoi punti generici, promuove l'uso di sottotipi e supertipi (con i quali sono fortemente d'accordo) poiché rispecchia il design orientato agli oggetti e può essere facilmente compreso dagli sviluppatori. Dal suo articolo:
Non aver paura di includere entità di supertipo e sottotipo nel tuo progetto nel CDM e successivi. I sottotipi rappresentano classificazioni o categorie del supertipo... Le entità sono rappresentate come sottotipi quando è necessaria più di una singola parola o frase per classificare l'entità.
Se una categoria ha una vita propria, con attributi separati che descrivono l'aspetto e il comportamento della categoria e relazioni separate con altre entità, allora è il momento di invocare la struttura del supertipo/sottotipo . In caso contrario, inibirà una comprensione completa dei dati e delle regole aziendali che guidano la raccolta dei dati.
Alcuni dei suoi commenti fanno riferimento specifico a MS SQL Server anche se i commenti sono in realtà problemi generici. Un punto principale che la signora Poolet fa è molto specifico di SQL Server:"Memorizza il codice che tocca i dati di un database come procedura memorizzata".
Questo va bene se stai pianificando di supportare solo un singolo sistema di gestione del database, come SQL Server. Ma per le implementazioni portatili, questo non sarebbe un buon consiglio. In generale, progetto per la portabilità su almeno due sistemi di gestione con supporto di linguaggi di stored procedure diversi. Pertanto, eviterei questa pratica.
Questo articolo è particolarmente utile per le persone che sviluppano per SQL Server e si concentrano sul mercato americano (piuttosto che su un sistema internazionale). Come americana che vive all'estero, però, ho scoperto che alcuni dei suoi esempi sono un po' troppo “centrici agli USA”. Ad esempio, un non americano potrebbe non capire cosa sia un Zip+4 dominio è e quindi non avrebbe alcuna comprensione del motivo per cui un dominio this dovrebbe avere una caratteristica NOT NULL.
Per illustrare questo, ho creato un modello di dati per entrambi gli indirizzi americani non americani. Assumiamo che il nostro modello di dati potrebbe richiedere che le entità siano collegate a più di un indirizzo:ad esempio, uno per la fatturazione, uno per la spedizione. Il primo indirizzo sarebbe associato a un metodo di pagamento; in questo caso, l'indirizzo verrebbe utilizzato per verificare il tuo diritto ad autorizzare tale pagamento. L'indirizzo di spedizione, ovviamente, è quello dove verrà consegnato l'ordine.
Creiamo un indirizzo americano come parte di un modello di database degli ordini dei clienti. (Nota:questo non è un modello completo, ma un esempio di memorizzazione degli ordini di prodotti.)
Wise Coders Solutions consiglia di definire campi separati per i numeri civici e i nomi delle strade e di impostare questi campi come NOT NULL; questo non consentirebbe qualsiasi indirizzo che non abbia un numero civico e il nome della via. Ma che dire delle persone che usano caselle postali? I loro indirizzi sono generalmente scritti come "casella postale 123". Dovremmo costringerli a mettere il numero della casella postale come numero civico e "casella postale" come nome della via? Non credo.
Invece, utilizzeremo un modulo con "Riga indirizzo 1" e "Riga indirizzo 2". Diverse persone si sono opposte all'uso di numeri nei nomi dei campi, ma per me questa è una soluzione piuttosto ovvia. Inoltre, ho definito le lunghezze massime dei campi (35 e 70 caratteri) tipiche dei pagamenti internazionali.
Si noti che i design statunitensi e non statunitensi hanno entrambi un campo per le regioni all'interno di un paese, ma il design statunitense richiede che sia inclusa un'abbreviazione di stato di 2 caratteri. Inoltre, nota che il design statunitense non consente indirizzi in altri paesi.
Se hai dubbi sull'utilizzo globale del tuo database, devi pensare a livello globale durante la fase di progettazione. I nostri database sono preparati per l'utilizzo multinazionale delle nostre applicazioni?
Lezioni apprese da una progettazione di data warehouse scadente
di Michelle A. Poolet | SQL Server Pro | 15 giugno 2009
Questo articolo esamina il Data Warehouse (DWH) e alcuni dei suoi problemi di progettazione e implementazione. C'è una leggera attenzione su SQL Server, ma è una panoramica abbastanza ortodossa della progettazione per il data warehousing e la business intelligence. Avere il buy-in e la creazione di interfacce intuitive potrebbe non essere il più utile dei suggerimenti, ma non sono in disaccordo con loro:semplicemente non penso che facciano parte del design DWH.
La signora Poolet afferma che il processo di estrazione-trasformazione-carico (ETL) dovrebbe eseguire controlli sulla qualità dei dati e dati potenzialmente "puliti" fino a quando non esiste uno standard accettabile di qualità dei dati. Questo, a mio avviso, rischia di creare un data warehouse che non rispecchia adeguatamente le informazioni estratte dal sistema sorgente. La pulizia dei dati deve essere eseguita nei sistemi di origine. ETL dovrebbe solo trasformare i dati in modo che possano essere caricati nel data warehouse.
Una nota positiva, la raccomandazione di riciclare o creare routine ETL riutilizzabili è molto rilevante. Inoltre, sono d'accordo con la signora Poolet sulla scalabilità. I suoi commenti sulla gestione del rischio e sulla conformità, in particolare il Sarbanes-Oxley Act, sembrano piuttosto specifici; Presumo che provengano dalla sua area di attività.
Infine, ha una bella lista di controllo di punti relativi a dimensioni, tabelle dei fatti e scelte di schemi durante la progettazione OLAP (elaborazione analitica online). Questi sembrano essere molto rilevanti durante il processo di progettazione del database. Avrei voluto che questo elenco fosse più lungo, con maggiori dettagli o esempi, ma sono stato felice che questi consigli pratici siano stati inclusi.
11 Regole importanti per la progettazione di database che seguo
di Shivprasad Koirala | Codice Progetto | 25 febbraio 2014
Mi piacciono molto i consigli sensati e chiari all'inizio di questo articolo. Concetti come "considerare la natura dell'applicazione" e "scomporre i dati in parti logiche" sono azzeccati. Questi sono aiuti importanti durante la creazione del modello di dati. Come dice il signor Koirala:
Quando si avvia la progettazione del database, la prima cosa da analizzare è la natura dell'applicazione per la quale si sta progettando, sia essa transazionale o analitica. Troverai molti sviluppatori che applicano le regole di normalizzazione per impostazione predefinita senza pensare alla natura dell'applicazione e poi entrare in problemi di prestazioni e personalizzazione.Tuttavia, ci sono un paio di punti che mi lasciano perplesso. Ad esempio, prendi la centralizzazione delle coppie Nome-Valore in un'unica tabella. Questo progetto One True Lookup Table (OTLT) è dibattuto, ma è generalmente considerato una cattiva pratica o almeno un anti-modello nel design. mi schiero con il gruppo anti-OTLT; queste tabelle introducono numerosi problemi. Potremmo utilizzare l'analogia dello sviluppo software dell'utilizzo di un singolo enumeratore per rappresentare tutti i possibili valori di tutte le possibili costanti come equivalente a questa pratica.
Per ricordarti, la tabella OTLT in genere è simile a questa, con voci di più domini lanciate nella stessa tabella. Sono d'accordo con il gruppo anti-OTLT; queste tabelle introducono numerosi problemi.
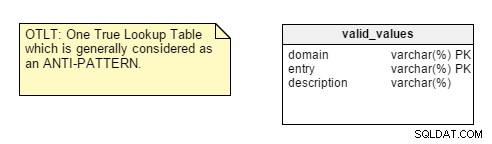
Inoltre, alcuni punti sembrano un po' esoterici, come "osservare i dati separati da separatori". Sebbene questo sia un punto valido, non è uno a cui di solito penso quando creo un nuovo modello di dati.
Il Sig. Koirala ha un paio di elementi di progettazione OLAP che generalmente non sono menzionati in altri elenchi di migliori pratiche. La sua inclusione di una dimensione e di una progettazione dei fatti può essere utile, ma potrebbe anche essere pericolosa per i designer principianti.
Questo articolo è interessante se si passa dall'inizio alla modellazione dei dati più avanzata. Ti aiuterà a considerare la natura analitica rispetto a quella transazionale dei tuoi modelli futuri.
Big Data:cinque semplici suggerimenti per le prestazioni di progettazione di database
di Dave Beulke | davebeulke.com | 19 marzo 2013

L'articolo del signor Beulke esamina i suggerimenti di progettazione incentrati sulle prestazioni. Mostra come verificare la corretta normalizzazione:né troppo né troppo poco. (L'eccessiva normalizzazione avrà un impatto negativo sulle prestazioni del database.)
Inoltre, l'utilizzo di chiavi aziendali naturali anziché di chiavi primarie generate è un valido consiglio quando si desidera evitare la conversione da una chiave aziendale a un ID riga generato per ogni accesso al database.
Anche l'uso di standard di denominazione e tipi di colonna corretti è un buon consiglio. Il punto sull'uso eccessivo di colonne nullable è valido:creare tutte le colonne come nullable è un errore, ma definire una colonna come nullable potrebbe essere necessario per una particolare funzione aziendale. Nelle stesse parole dell'autore:
Tutte le colonne sono NULLable? All'interno delle definizioni delle colonne del database, è necessario analizzare, valutare e creare prototipi per l'applicazione aziendale di buoni domini di dati, intervalli e valori. Avere buoni valori predefiniti, un ambito limitato di valori e sempre un valore sono i migliori per le prestazioni e la logica dell'applicazione. Le colonne NULLable sono valide solo quando i dati sono sconosciuti o non hanno ancora un valore. I dati sulla data di morte di qualcuno sono il classico esempio di colonna NULLable perché sono sconosciuti a meno che non siano già morti. Assicurati che la progettazione del tuo database rappresenti dati noti e utilizzi solo un minimo di colonne NULLable.I consigli del signor Beulke sono tutti molto solidi, anche se alquanto poco originali. Mi sarebbero piaciuti più elementi Big Data, questo è, dopotutto, il titolo dell'articolo. Alla fine, ho sentito che l'articolo mancava sia di profondità che di ampiezza e non aveva esempi per chiarire i punti. Tuttavia, offre preziosi consigli relativi alla normalizzazione e alle chiavi naturali.
10 best practice per la progettazione di database
di Ann All | Applicazioni aziendali oggi | 15 luglio 2014
Ten Database Design Best Practices è in realtà presentato come una serie di diapositive. Ms. All include informazioni da sviluppatori esperti, come Michael Blaha. Incoraggia il riutilizzo delle tue migliori pratiche e modelli. Questi sono compresi e provati e, in questo senso, sono preferibili ai modelli di dati che devono essere creati da zero. Dall'articolo di Ms. All:
Ad esempio, spesso eseguo il reverse engineering dei database:database di un'applicazione da sostituire e database di applicazioni correlate. Questi database esistenti spesso non dispongono di un modello di dati disponibile. Ma un modello di dati è implicito nello schema del database e può essere almeno parzialmente estratto con tecniche di reverse engineering del database. … Ci sono rappresentazioni dei dati collaudate che spesso si verificano e non devono essere ricreate da zero.Questa è una breve presentazione che i progettisti di modelli di dati possono esaminare rapidamente e raccogliere i suggerimenti che risuonano con loro. Per me, il consiglio di riutilizzo è uno dei miei preferiti.
Best practice per il database
di Cunningham &Cunningham, Inc.
Queste best practice sono iniziate bene, ma poi sono entrate in alcuni problemi persistenti. Non sono convinto che i consigli offerti siano sempre azzeccati.
Il lato positivo è che ci sono descrizioni molto belle di "migliori pratiche" controverse come l'utilizzo sempre di chiavi surrogate generate automaticamente e l'utilizzo o l'evitamento di stored procedure. Ad esempio:
Un precedente autore ha scritto:"In genere, evita le chiavi primarie che hanno un significato. I nomi non sono univoci e molti identificatori apparentemente univoci come i numeri di previdenza sociale in realtà non lo sono, a causa di problemi di affidabilità dei dati nel mondo reale". In breve, questa è una raccomandazione per avere sempre una SurrogateKey generata automaticamente (in genere numerica) anziché una LogicalKey basata sul dominio. Questa è una risposta piuttosto banale a un problema complesso, sebbene sia sufficiente in un certo numero di casi ed è almeno preferibile alla mancanza di PrimaryKey.(Nota dell'autore:non sono riuscito a trovare questo "autore precedente" durante la ricerca di queste due frasi su Google.)
E viene fornito un collegamento a un articolo di riepilogo sugli argomenti principali su ciascun lato del dibattito tra chiavi automatiche e chiavi di dominio.
D'altra parte, ho trovato i suggerimenti per "dividere il sistema operativo, i dati e l'accesso su diversi dischi fisici" e "usare RAID" un po' arcani. Non fraintendermi:questo è probabilmente un buon consiglio in alcune circostanze, ma non lo includerei nella mia lista dei 20 migliori.
Suggerimenti per la progettazione del database
di Wise Coders
Ci sono alcuni suggerimenti unici e interessanti in questa raccolta, come una raccomandazione di chiudere le transazioni il prima possibile.
Tuttavia, non sono completamente d'accordo con tutti i suggerimenti di progettazione qui. Ad esempio:
Presuppone un campo 'Stato' con valori 'Attivo', 'Non attivo' e 'Inattivo'. È possibile salvare il valore come nome completo, ma ciò può essere inefficiente. La memorizzazione di un'enumerazione o di un char(1) con possibili valori 'a', 'i', 'd', ad esempio, utilizzerà meno spazio nel database.Questo è controverso, per non dire altro:altre fonti raccomandano di non utilizzare "codici segreti" come questo. Utilizza invece una tabella separata per memorizzare questi codici di stato.
Inoltre, le statistiche associate ai suggerimenti sulle prestazioni sono discutibili e non ci sono esempi nell'articolo.
Una nota positiva, questo è un breve elenco di suggerimenti che dovrebbero essere accessibili ai modellatori di database intermedi.
Risorse per i progettisti di database principianti
Ora esaminiamo alcuni articoli per coloro che hanno appena iniziato a progettare database.
Le basi di una buona progettazione di database nello sviluppo Web
di Kayla Knight | Onextrapixel.com | 17 marzo 2011
Qui diventiamo un po' più avanzati, con consigli che vanno dalla funzionalità agli strumenti di modellazione.
La signora Knight ci guida attraverso un'introduzione alla progettazione di database. Il suo articolo è interessante perché enfatizza i database per lo sviluppo web. Anche così, i suoi punti sono abbastanza universali e possono essere applicati alla progettazione di database in molte situazioni.
L'articolo inizia chiedendoci di pensare in modo ampio alla funzionalità, non solo al database:
Pensa fuori dal database. Prova a pensare a cosa dovrà fare il sito web. Ad esempio, se è necessario un sito Web in abbonamento, il primo istinto potrebbe essere quello di iniziare a pensare a tutti i dati che ogni utente dovrà archiviare. Lascia perdere, è per dopo. Piuttosto, annota che gli utenti e le loro informazioni dovranno essere archiviati nel database e cos'altro? Cosa dovranno fare questi membri sul sito? Faranno post, caricheranno file o foto o invieranno messaggi? Quindi il database avrà bisogno di un posto per file/foto, post e messaggi.Da lì, la signora Knight porta il lettore negli strumenti di progettazione del database e nei passaggi coinvolti nel processo. Il suo articolo fornisce esempi e collegamenti ad altre risorse.
Penso che questo articolo sarebbe un'ottima introduzione per i progettisti di database principianti e dovrebbe funzionare bene con Geek Girl's serie.
Esplorazione dei suggerimenti per la progettazione di database
di Doug Lowe | Per i manichini
L'elenco dei "Dummies" di Mr. Lowe è un'ampia serie di suggerimenti di progettazione di base. Puoi trovarne molti altrove, ma è utile averli in un unico posto. Non troverai nulla di unico o altamente controverso, ad eccezione di una raccomandazione per l'utilizzo di stored procedure. Metto sempre in dubbio questa affermazione forte, poiché sono molto preoccupato per la portabilità del modello di dati per più sistemi DBM.
Ecco uno dei consigli di buon senso del signor Lowe:
Evita i campi con nomi come CustomerType, in cui il valore del campo è una delle numerose costanti che non sono definite altrove nel database, come R per Retail o W per Wholesale. Potresti avere solo questi due tipi di clienti oggi, ma le esigenze dell'applicazione potrebbero cambiare in futuro, richiedendo un terzo tipo di cliente.Questi consigli sono più appropriati quando si lavora con SQL Server.
Cinque semplici suggerimenti per la progettazione di database
di Lamont Adams | TechRepubblica | 25 giugno 2001
La parola chiave per questa risorsa è “semplice”. Puoi trovare queste informazioni, con ulteriori spiegazioni ed esempi, in altri articoli.
Tuttavia, il consiglio del signor Adams di "portare via le chiavi dell'utente" è un punto interessante, raramente menzionato in altri luoghi. Continua:
Quando si decide quale campo o campi utilizzare come chiavi in una tabella, considerare sempre i campi che gli utenti modificheranno. Di solito è una cattiva idea scegliere un campo modificabile dall'utente come chiave.Il significato di Mr. Adams è che dovresti considerare il potenziale requisito dell'utente di modificare i campi quando decidi quali campi utilizzare come chiavi. Mi sarebbe piaciuto avere più spiegazioni riguardo alle alternative, come chiavi sintetiche/generate, ma il concetto è buono.
Non sono d'accordo con l'ultimo punto. Consiglia un "fattore fondente" per ogni tavolo che disegni:
Non c'è niente di peggio che scoprire, o essere informati, che nel database "finito" manca un campo per un'informazione cruciale. In un'azienda per cui lavoravo, questo era un evento così comune che abbiamo iniziato a riferirci a "blocchi di database" come "granite di database".Nella mia mente, questo è fondamentalmente "aggiungere un paio di campi di testo extra alla fine". Questo sembra contraddire alcuni degli altri suggerimenti del signor Adams, in particolare quelli riguardanti la comprensione delle esigenze aziendali e l'uso di nomi significativi. Questi campi extra fudge sarebbero semplicemente chiamati qualcosa come "extra1" o "extra2". Qual è la loro esigenza aziendale? E come sono questi nomi significativi? Anche se la maggior parte dei suoi suggerimenti di progettazione mi piace, questo "fattore caramella" non è qualcosa a cui mi attengo.
Progettazione database:menzioni d'onore
Ovviamente, ci sono altri articoli che descrivono suggerimenti e best practice per la progettazione di database. Puoi trovare materiale aggiuntivo ai seguenti link:
Progettazione di database relazionali:una guida alle migliori pratiche | di Digital Ethos | 24 dicembre 2012
Procedure consigliate per la progettazione di schemi di database (principianti) | di Jim Murphy | 28 marzo 2011
Migliori pratiche IT:progettazione di database | dall'Università del Nebraska–Lincoln
Risorse per la progettazione di database online:dove andresti?
Come accennato, questo elenco non vuole assolutamente essere un esame esauriente di ogni articolo di progettazione di database su Internet. Piuttosto, abbiamo identificato diversi articoli che riteniamo utili o che hanno un focus particolare che potresti trovare utile.
Non esitare a consigliare altri articoli.