In un articolo precedente abbiamo discusso del modello dello schema a stella. Lo schema del fiocco di neve è accanto allo schema a stella in termini di importanza nella modellazione del data warehouse. È stato sviluppato partendo dallo schema a stella e offre alcuni vantaggi rispetto al suo predecessore. Ma questi vantaggi hanno un costo. In questo articolo, discuteremo quando e come utilizzare lo schema del fiocco di neve.
Lo schema del fiocco di neve
Il nome dello schema del fiocco di neve deriva dal fatto che le tabelle delle dimensioni si ramificano e assomigliano a un fiocco di neve. Quando osserviamo il modello sopra, noteremo che è una tabella dei fatti circondata da alcune tabelle dimensionali, alcune delle quali eseguono la suddetta ramificazione. A differenza dello schema a stella, le tabelle delle dimensioni nello schema del fiocco di neve possono avere le proprie categorie.
L'idea dominante dietro lo schema del fiocco di neve è che le tabelle dimensionali siano completamente normalizzate. Ciascuna tabella delle dimensioni può essere descritta da una o più tabelle di ricerca. Ciascuna tabella di ricerca può essere descritta da una o più tabelle di ricerca aggiuntive. Questo viene ripetuto fino a quando il modello non è completamente normalizzato. Il processo di normalizzazione delle tabelle dimensionali dello schema a stella è chiamato snowflaking.
Sentirai molto sulla normalizzazione in questo articolo. Cos'è la normalizzazione? Fondamentalmente, sta organizzando un database in modo da ridurre al minimo le ridondanze e proteggere l'integrità dei dati. Dai un'occhiata a questo post per saperne di più sulla normalizzazione e denormalizzazione.
Esempio di schema del fiocco di neve:modello di vendita
In precedenza, utilizzavamo uno schema a stella per modellare un reparto vendite fittizio:sarebbe simile a un data mart utilizzato per tenere traccia delle attività di vendita e dei risultati. Il modello ha cinque dimensioni:prodotto , tempo , negozio , vendite digitare e dipendente . Nel fact_sales tabella, prezzo e quantità vengono memorizzati e raggruppati in base ai valori nelle tabelle dimensionali. Per un aggiornamento, dai un'occhiata al modello di vendita dello schema a stella di seguito:
Ecco lo stesso modello organizzato come schema a fiocco di neve:
Il dim_employee e dim_sales_type le tabelle delle dimensioni sono esattamente le stesse del modello dello schema a stella perché sono già normalizzate.
D'altra parte, abbiamo applicato le regole di normalizzazione al resto delle tabelle delle dimensioni.


Il dim_product la tabella delle dimensioni dello schema a stella è suddivisa in due tabelle nel modello del fiocco di neve. Il dim_product_type è stata aggiunta la tabella per fare riferimento al tipo di corrispondenza nel dim_product tavolo. Usando questo, abbiamo evitato alcuni problemi di integrità dei dati.
È logico presumere che avremo già tutti i nomi di prodotto e i relativi tipi inseriti come parte del processo ETL, ma supponiamo di dover aggiungere più nomi e tipi di prodotto. In uno schema a stella potremmo erroneamente inserire nella tabella il tipo di prodotto sbagliato. Nello schema del fiocco di neve:
- Se incontriamo un nuovo nome di tipo di prodotto, possiamo aggiungere un nuovo tipo di prodotto e quindi collegare quel tipo a un record appena aggiunto. Tuttavia, ciò potrebbe comportare l'inserimento da parte dell'utente di informazioni errate, proprio come nello schema a stella.
- Potremmo verificare se il nome del prodotto che vogliamo aggiungere esiste già. In tal caso, possiamo ottenere il suo ID; in caso contrario, verrà visualizzato un avviso che ci chiede se vogliamo aggiungere un nuovo prodotto e un tipo correlato.

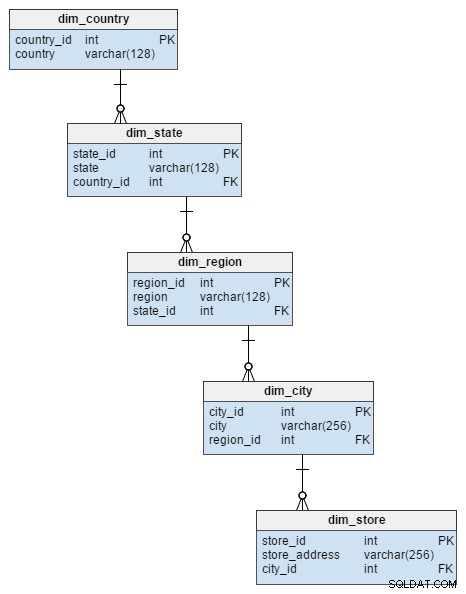
Il dim_store la tabella delle dimensioni dello schema a stella è rappresentata da 5 tabelle nello schema del fiocco di neve. Questi dividono gli attributi di città, regione, stato e paese che sono stati memorizzati nel dim_store tavolo. La normalizzazione di questa tabella non solo ha evitato il rischio di integrità dei dati, ma ha anche risparmiato spazio su disco.
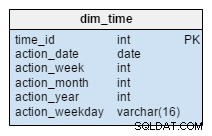
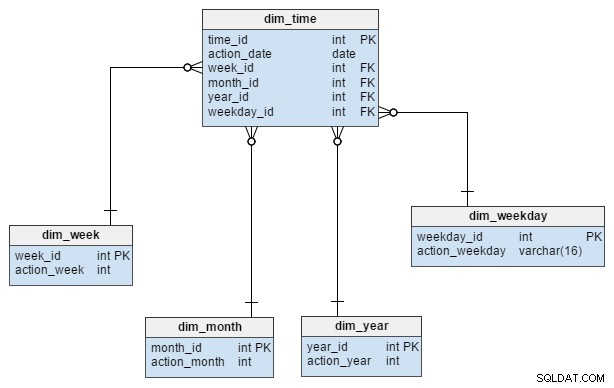
Il dim_time la dimensione è rappresentata con cinque tabelle. Possiamo pensare a dim_week , dim_month , dim_year e il dim_weekday tabelle come dizionari che descrivono il dim_time tavolo.
Il dim_week , dim_month , dim_year e dim_weekday le tabelle sono quattro diverse gerarchie usate per descrivere la nostra dimensione temporale. Potremmo aggiungere più dimensioni come quarti o altre tabelle correlate se ne avessimo bisogno. In questo esempio, dim_month è un dizionario contenente 12 mesi; solo da questa dimensione non abbiamo modo di sapere a quale anno appartenga quel mese; questa è la funzione del dim_year tavolo.
Esempio di schema del fiocco di neve:modello degli ordini di fornitura
L'altro data mart di cui abbiamo discusso riguardava gli ordini di forniture. L'idea è quella di archiviare e aggregare tutti i dati degli ordini di fornitura per le seguenti quattro dimensioni:prodotto , tempo , fornitore e dipendente . Ancora una volta, daremo un'occhiata allo schema a stella pertinente:
Convertindolo nello schema del fiocco di neve, otteniamo il seguente modello:
Sul dim_product , dim_time e dim_supplier tabelle dimensionali.
Vantaggi e svantaggi dello schema del fiocco di neve
Ci sono due vantaggi principali allo schema del fiocco di neve:
- Migliore qualità dei dati (i dati sono più strutturati, quindi i problemi di integrità dei dati sono ridotti)
- In un modello denormalizzato viene utilizzato meno spazio su disco
Lo svantaggio più notevole per il modello del fiocco di neve è che richiede query più complesse. Queste query, con il loro numero maggiore di join, potrebbero ridurre significativamente le prestazioni.
Riscriveremo la stessa query utilizzata nell'articolo sullo schema a stella per il modello di vendita dello schema del fiocco di neve. Ecco la query necessaria per restituire la quantità di tutti i tipi di prodotti di tipo telefono venduti nei negozi di Berlino nel 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Lo schema di Starflake
Uno schema Starflake è una combinazione degli schemi Snowflake e Star. Possiamo vederlo come uno schema a fiocco di neve con alcune tabelle dimensionali denormalizzate. Se usato correttamente, lo schema Starflake può offrire un approccio migliore di entrambi i mondi. Ovviamente, la parte a fiocco di neve del modello dovrebbe risparmiare spazio su disco, mentre la parte a stella dovrebbe migliorare le prestazioni.
Il modello sopra è fondamentalmente un modello di fiocco di neve con un dim_time tavolo. Poiché questo schema riduce il numero di join di query necessari, potrebbe migliorare le prestazioni. D'altra parte, non perderemo una notevole quantità di spazio su disco, poiché la maggior parte degli attributi della tabella e degli attributi della chiave esterna condividono int digitare.
Lo schema della galassia
Nel data warehousing, uno schema galaxy è quando due o più tabelle dei fatti condividono una o più tabelle delle dimensioni. Uno dei motivi per utilizzare questo schema è risparmiare spazio su disco. Di seguito abbiamo creato uno schema di galassie di esempio:
Qui abbiamo due tabelle dei fatti, fact_sales e fact_supply_order , che condividono direttamente tre tabelle dimensionali:dim_product , dim_employee e dim_time . Nota che anche dim_store e dim_supplier condividi la stessa tabella di ricerca, dim_city .
In questo modo risparmieremo spazio, ma dobbiamo tenere a mente alcune cose prima di unire due data mart (in questo caso, ordini di vendita e di fornitura) in uno schema galaxy:
- C'è una logica dietro l'adesione a loro? Es. Entrambi i data mart verrebbero utilizzati dallo stesso dipartimento?
- Siamo sicuri di aver bisogno di esattamente la stessa dimensione e granulazione per entrambi i data mart?
Lo schema del fiocco di neve viene spesso utilizzato nella modellazione dei dati. Potrebbe essere la scelta giusta in situazioni in cui lo spazio su disco è più importante delle prestazioni. Se vogliamo un equilibrio tra risparmio di spazio e prestazioni, possiamo utilizzare lo schema Starflake. Tuttavia, la giusta misura per qualsiasi problema specifico dipende da molti parametri. Questa è una delle aree dell'IT in cui possiamo "giocare" con i fattori per trovare la soluzione migliore.