Daniel Keys Moran dice "Puoi avere dati senza informazioni, ma non puoi avere informazioni senza dati". I dati sono la risorsa chiave in ogni organizzazione, se perdi i dati, perdi informazioni. Questo, a sua volta, può portare a decisioni aziendali sbagliate o addirittura l'azienda non è in grado di operare. Avere un piano di ripristino di emergenza per i tuoi dati è un must e il cloud può essere particolarmente utile qui. Sfruttando l'archiviazione nel cloud, non è necessario preparare l'archiviazione per l'archiviazione dei dati di backup o spendere denaro in anticipo per costosi sistemi di archiviazione. Amazon S3 e Google Cloud Storage sono ottime opzioni in quanto sono affidabili, economici e durevoli.
In precedenza abbiamo scritto sull'archiviazione dei backup PostgreSQL su AWS e anche su GCP. Diamo quindi un'occhiata ad alcuni suggerimenti per archiviare i backup dei dati TimescaleDB su AWS S3 e Cloud Storage.
Preparazione del bucket AWS S3
AWS fornisce una semplice interfaccia Web per la gestione dei dati in AWS S3. Il termine bucket è simile a una "directory" nei termini tradizionali di archiviazione del filesystem, è un contenitore logico per oggetti.
Creare un nuovo bucket in S3 è facile, puoi andare direttamente al menu S3 e creare un nuovo bucket come mostrato di seguito:
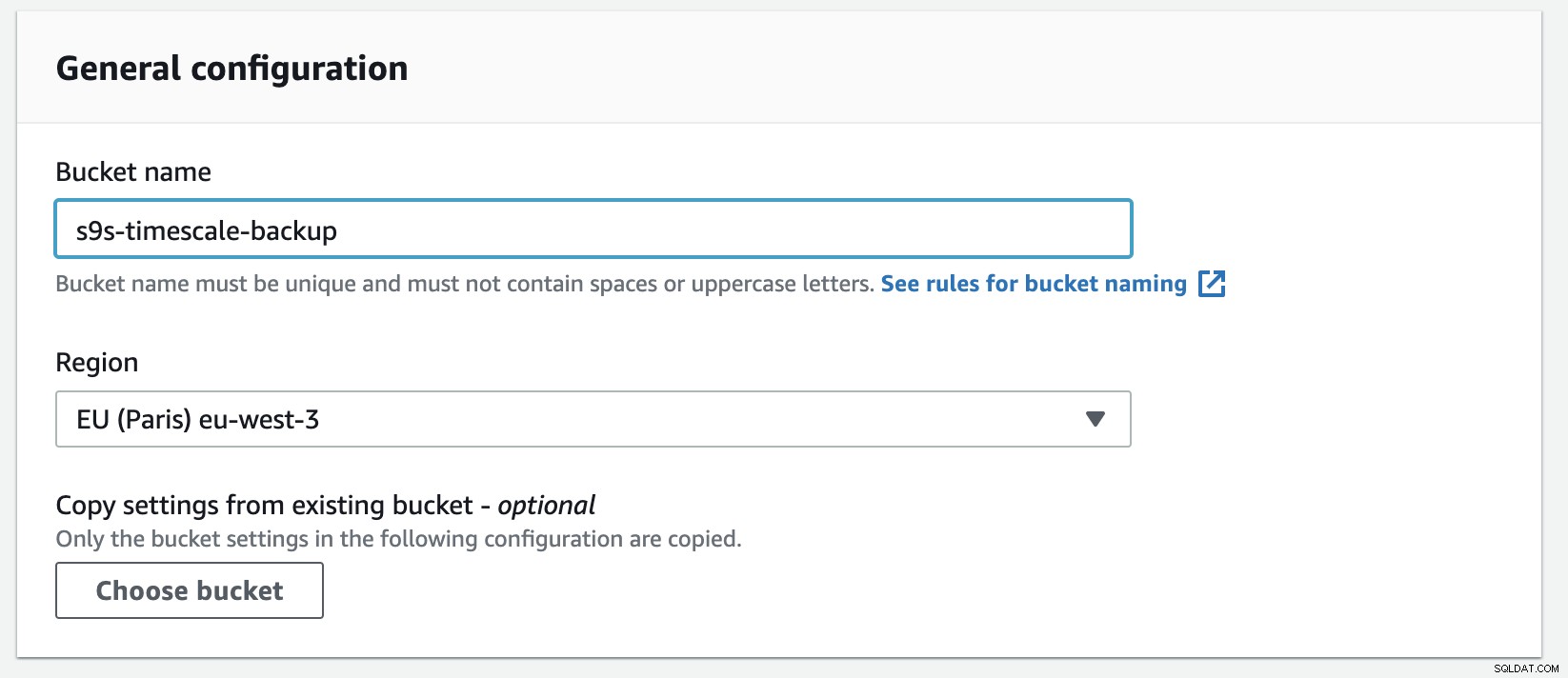
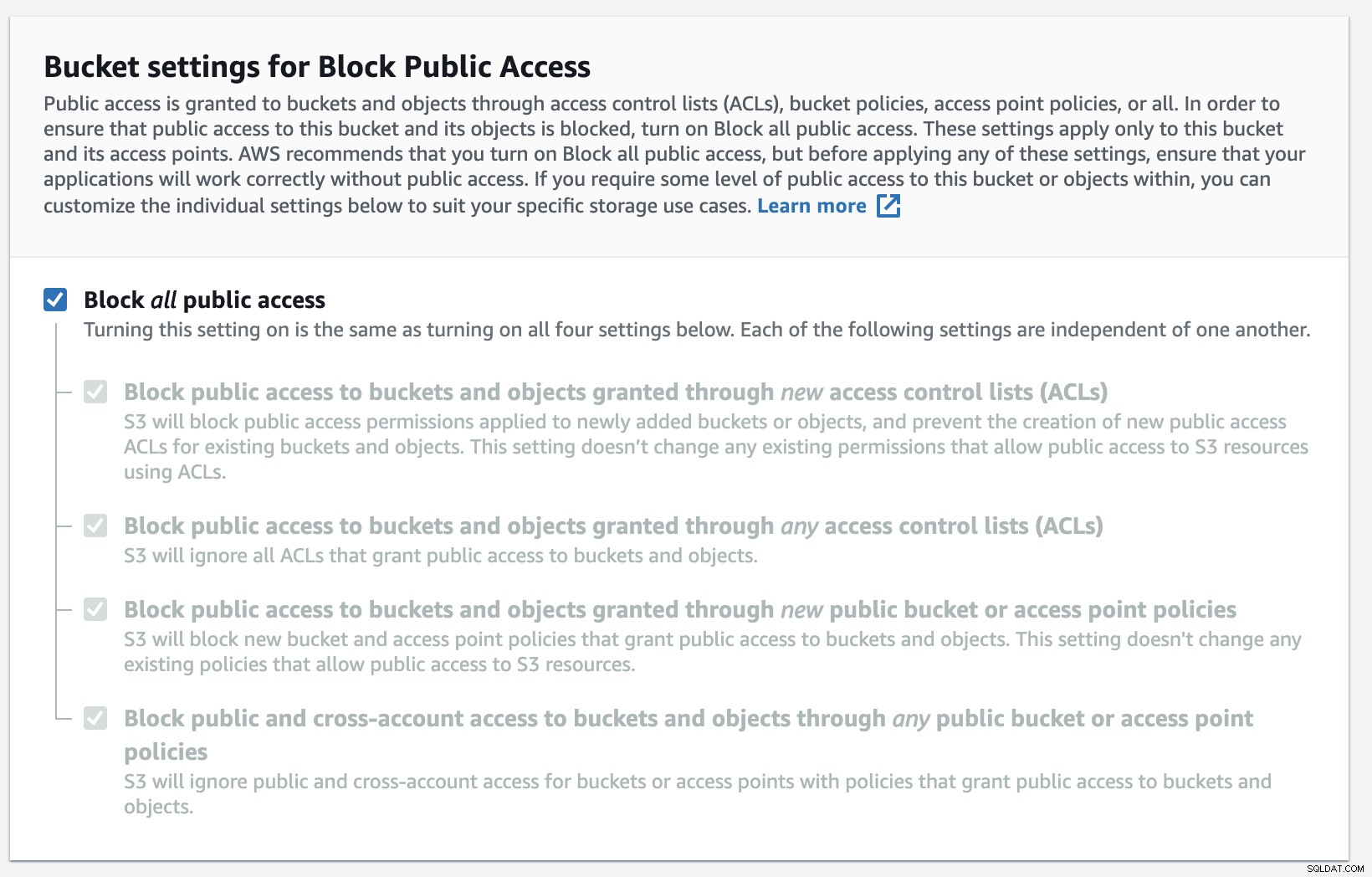
È necessario compilare il nome del bucket, il nome è univoco a livello globale su AWS come spazio dei nomi è condiviso tra tutti gli account AWS. Puoi limitare l'accesso al bucket da Internet oppure puoi pubblicarlo con restrizioni ACL. La crittografia è una pratica importante per proteggere i tuoi dati di backup.
Preparazione del bucket di archiviazione Google Cloud
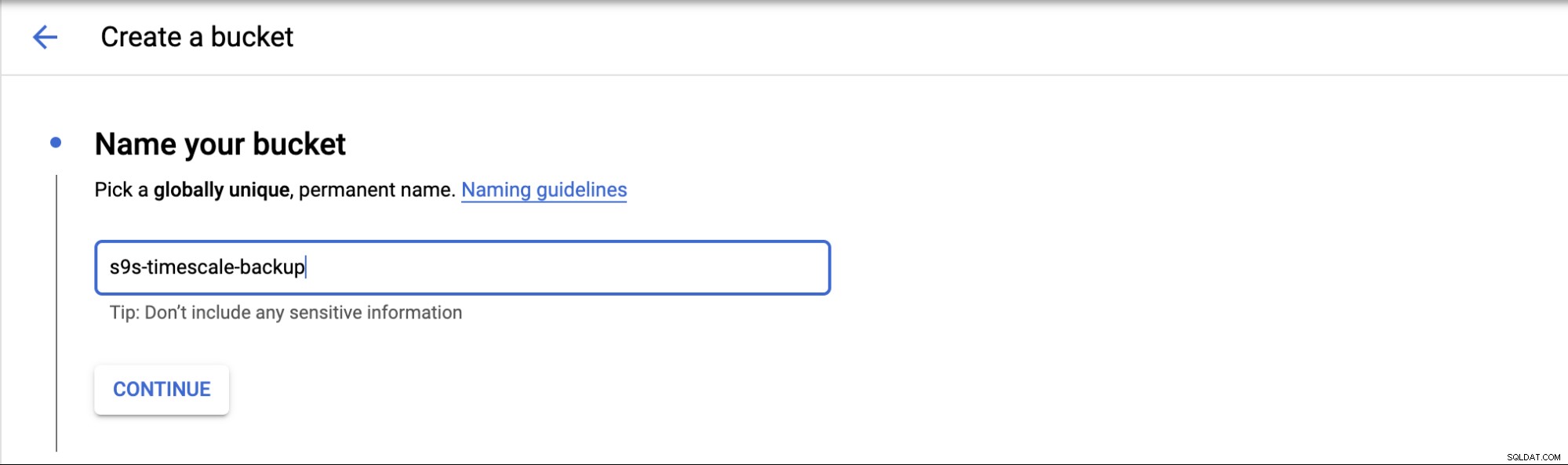
Per configurare l'archiviazione cloud in GCP, puoi andare alla categoria Archiviazione e scegliere Archiviazione -> Crea bucket. Inserisci il nome del bucket, in modo simile ad Amazon S3, e anche il nome del bucket è univoco a livello globale in GCP.
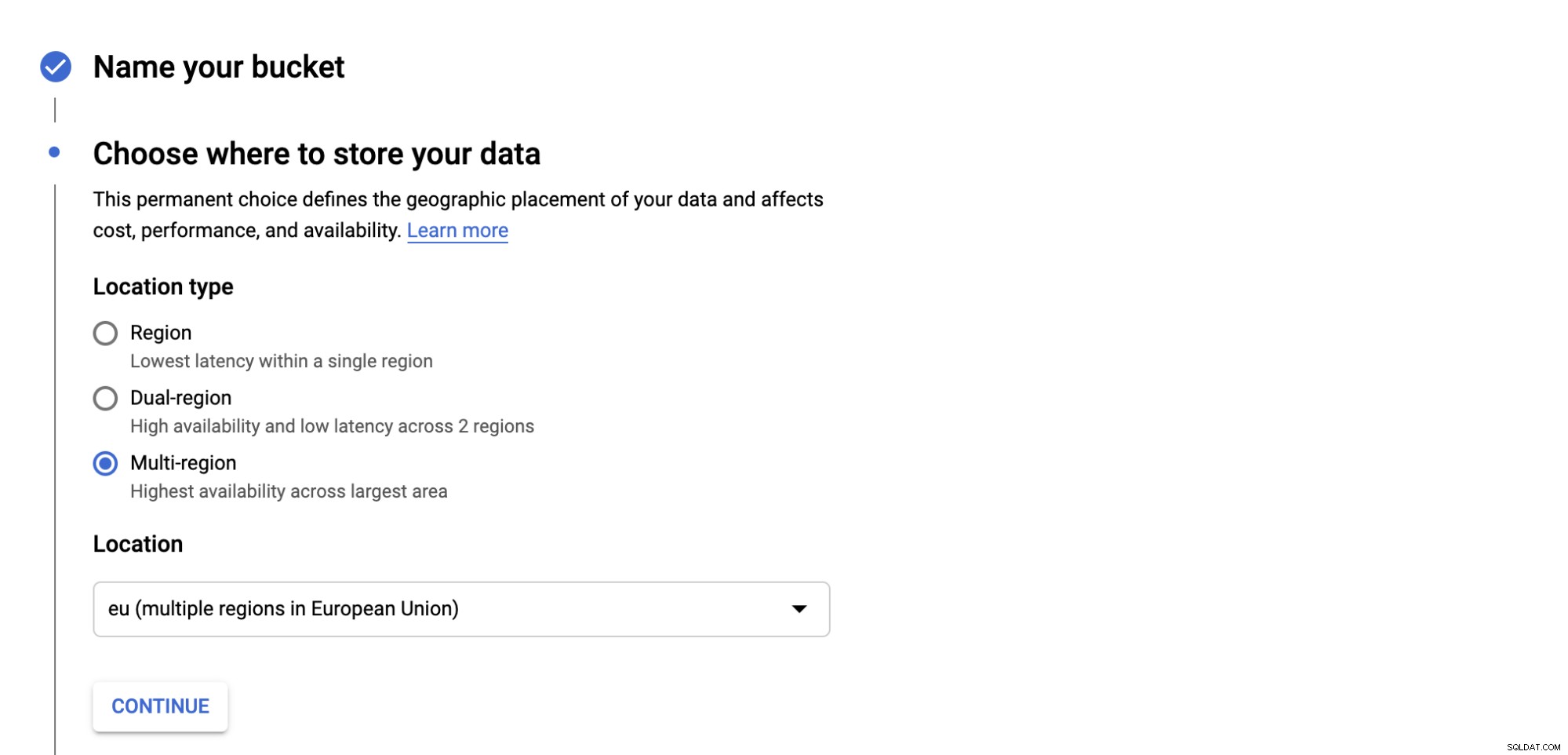
Scegli dove archiviare il backup, ci sono tre tipi di posizione; puoi archiviare in una singola regione, doppia regione o multiregione.
Scegli il tipo di classe di storage per il tuo bucket, ci sono quattro categorie che sono; Standard, Nearline, Coldline e Archivio. Ogni categoria ha criteri su come recuperare i dati e anche il costo.

Ci sono alcune impostazioni avanzate relative alla crittografia per i bucket, policy di conservazione e controllo accessi.
Configura l'utilità di archiviazione cloud
AWS CLI è un'interfaccia fornita da AWS per interagire con i servizi AWS come S3, EC2, gruppi di sicurezza, VPC, ecc. tramite la riga di comando. Puoi configurare l'AWS CLI sul nodo in cui risiedono i file di backup prima di trasferire i file a S3. Puoi seguire la procedura di installazione per AWS CLI qui.
Puoi controllare la tua versione dell'AWS CLI eseguendo il comando seguente:
example@sqldat.com:~# /usr/local/bin/aws --version
aws-cli/2.1.7 Python/3.7.3 Linux/4.15.0-91-generic exe/x86_64.ubuntu.18 prompt/offDopodiché, devi configurare la chiave di accesso e la chiave segreta dal server come segue:
example@sqldat.com:~# aws configure
AWS Access Key ID [None]: AKIAREF*******AMKYUY
AWS Secret Access Key [None]: 4C6Cjb1zAIMRfYy******1T16DNXE0QJ3gEb
Default region name [None]: ap-southeast-1
Default output format [None]:Allora sei pronto per eseguire e trasferire il backup nel tuo bucket.
$ aws s3 cp “/mnt/backups/BACKUP-1/full-backup-20201201.tar.gz” s3://s9s-timescale-backup/Puoi creare uno script di shell per il comando precedente e configurare uno scheduler per l'esecuzione quotidiana.
GCP fornisce GSUtil Tool, che ti consente di accedere a Cloud Storage tramite la riga di comando. La procedura di installazione di GSUtil può essere trovata qui. Dopo l'installazione, puoi eseguire gcloud init per configurare l'accesso a GCP.
example@sqldat.com:~# gcloud initTi verrà chiesto di accedere a Google Cloud accedendo all'URL e aggiungendo il codice di autenticazione.
Dopo aver configurato tutto, puoi eseguire il trasferimento di backup al Cloud Storage eseguendo quanto segue:
example@sqldat.com:~# gsutil cp /mnt/backups/BACKUP-1/full-backup-20201201.tar.gz gs://s9s-timescale-backup/Gestisci il tuo backup con ClusterControl
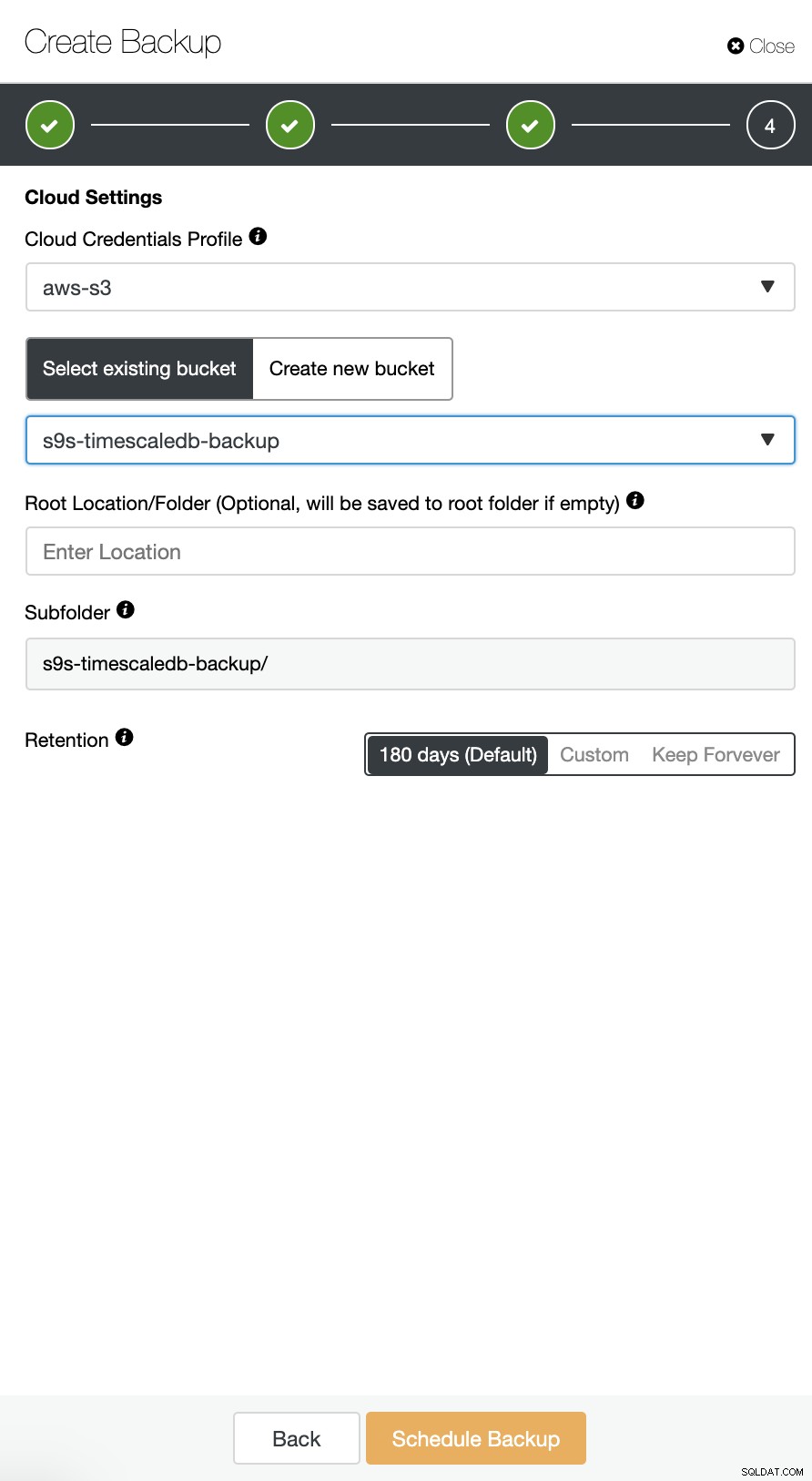
ClusterControl supporta il caricamento dei backup di TimeScaleDB sul cloud. Attualmente supportiamo Amazon AWS, Google Cloud Platform e Microsoft Azure. Per configurare il backup di TimescaleDB sul cloud è molto semplice, puoi accedere al backup nel tuo cluster TimescaleDB e Crea backup come mostrato di seguito:
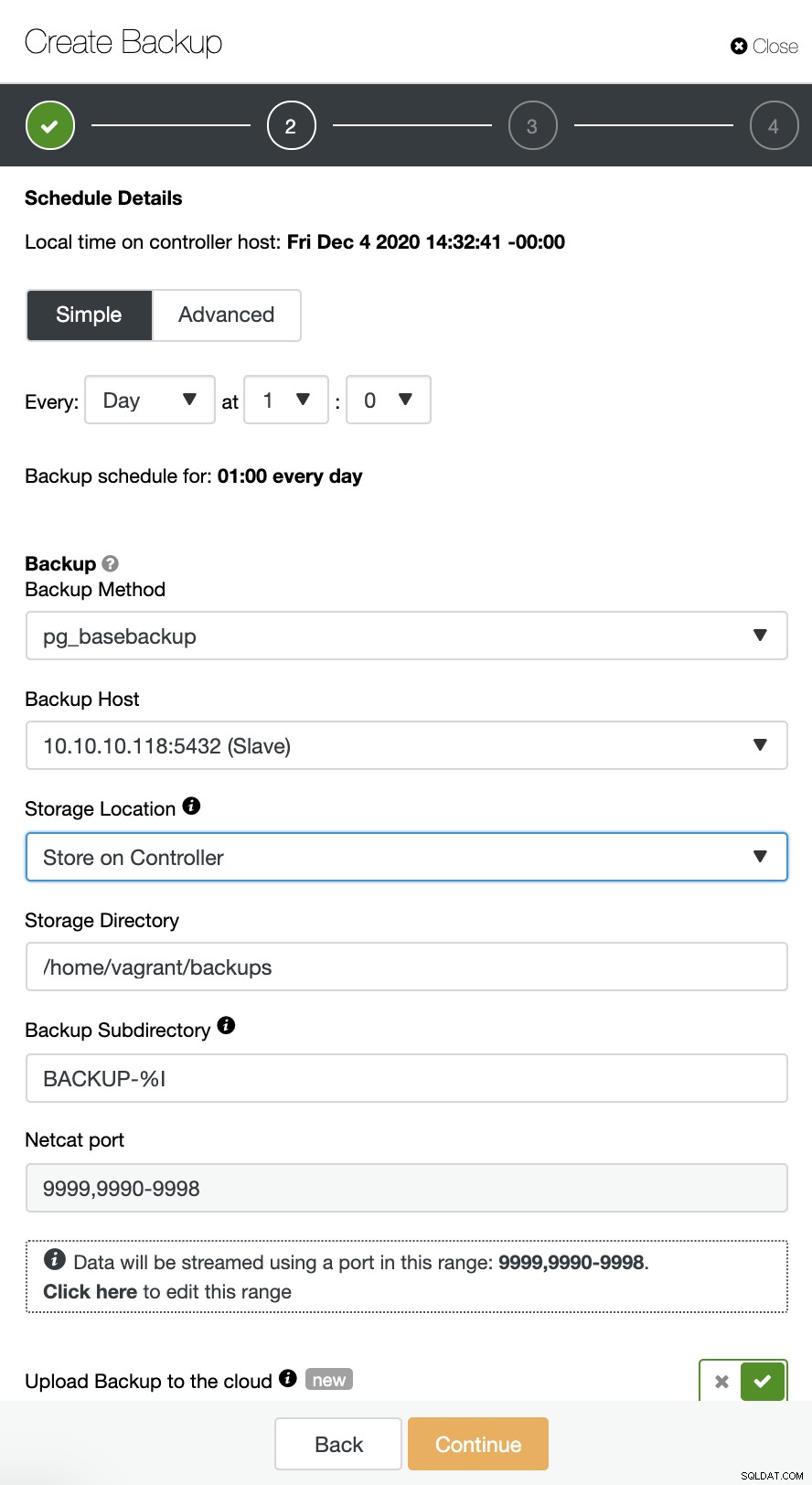
Abilita l'opzione "Carica backup nel cloud" e continua. Ti verrà chiesto di scegliere il provider cloud e di compilare le chiavi di accesso e segrete. In questo caso, utilizzo AWS S3 come provider di backup nel cloud.
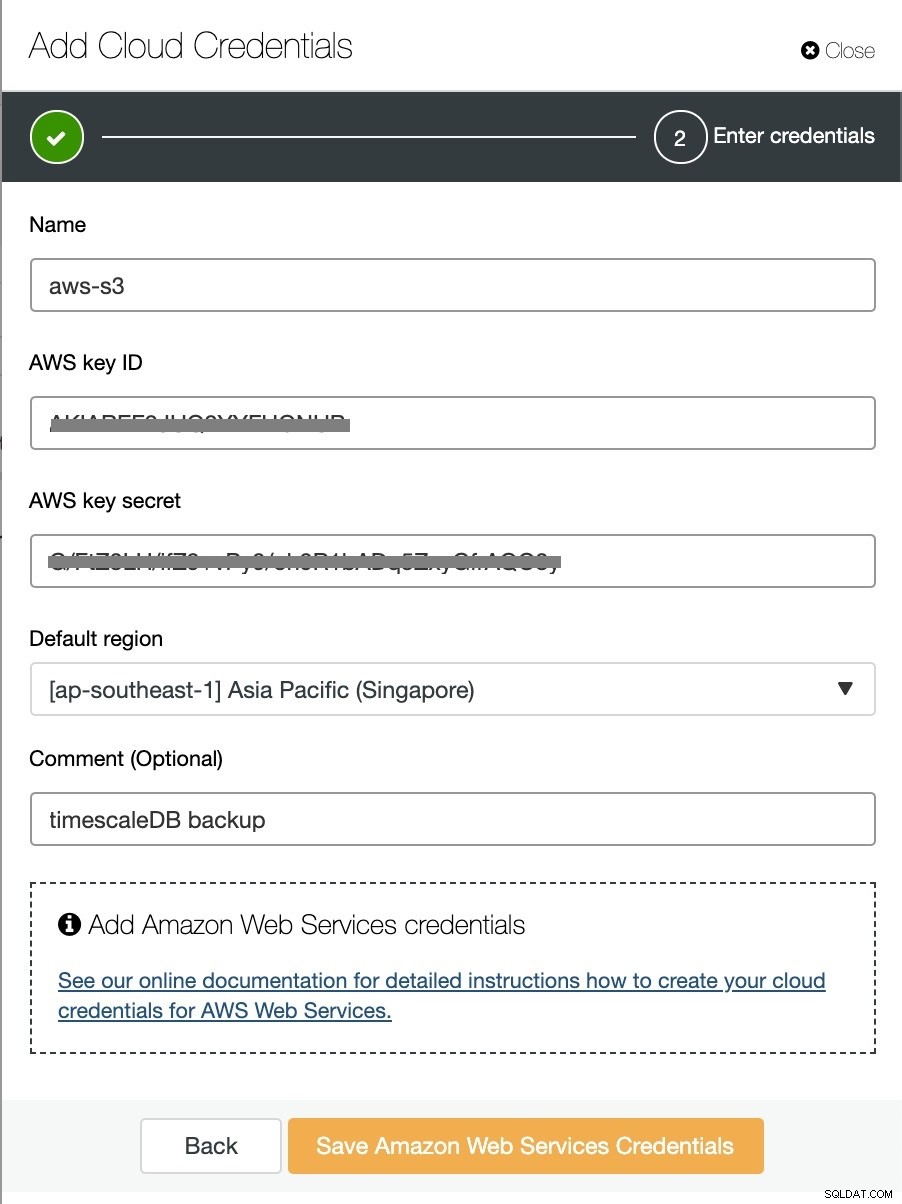
E infine, scegli il bucket che era stato creato in precedenza. È possibile configurare la conservazione del backup e Pianifica backup come di seguito: