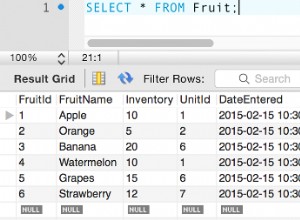
Nel mio post precedente, abbiamo visto alcune differenze fondamentali tra i database relazionali e non relazionali. In questo post, parliamo della scalabilità di questi due.
Scalabilità
È un'abilità di un sistema che può facilmente ospitare i dati in arrivo senza troppi problemi di prestazioni. Questo è il fattore principale per qualsiasi sistema per fornire una buona scalabilità. Esistono due tipi di metodi di ridimensionamento noti come ridimensionamento verticale e orizzontale.
Ridimensionamento verticale
Tutti gli strumenti del database relazionale supportano il ridimensionamento verticale. Questo è il metodo per aumentare la potenza del sistema aggiungendo ulteriore CPU, memoria e spazio su disco. Quindi, per consentire un rapido ingresso di dati, il singolo server di produzione è ottimizzato per la scalabilità verticale. In questa tecnica di ridimensionamento, c'è sempre un unico server di produzione che può essere connesso da tutte le applicazioni e gli utenti. È possibile creare un ambiente cluster con alcuni nodi e replicare i dati tra i nodi.
A causa delle proprietà ACID, tutti i nodi dovrebbero avere lo stesso set di dati e la sincronizzazione dei dati diventa complicata se sono presenti più nodi nel cluster. Questo è molto ottimizzato per il ridimensionamento in lettura. Il ridimensionamento verticale è anche noto come scale-up
Il vantaggio di questa metodologia di ridimensionamento è la stretta integrazione dei dati e la relativa coerenza tra i nodi di un cluster. Tutti i nodi avranno lo stesso set di dati e se si verifica un problema con il server di produzione, un altro nodo verrà automaticamente connesso dalle applicazioni. Quindi questo cluster è noto come cluster di failover.
Ridimensionamento orizzontale
Tutti gli strumenti di database non relazionali supportano il ridimensionamento orizzontale. Questo è il metodo per aggiungere più computer alla rete per consentire un rapido ingresso di dati. È facile aggiungere più nodi al cluster per consentire la crescita dei dati. I dati vengono suddivisi automaticamente ed elaborati tra i nodi di un cluster. Questo è un ambiente dati distribuito. Hadoop Distributed File System (HDFS) è un classico esempio di questo. Il ridimensionamento orizzontale è noto anche come ridimensionamento.
Il vantaggio di questa tecnica di ridimensionamento è che, poiché i dati vengono suddivisi e replicati tra i nodi se uno qualsiasi dei nodi va offline, l'applicazione può ancora avere i dati da altri nodi e questo garantisce la disponibilità dei dati in qualsiasi momento. Questo metodo è molto utile nei casi in cui non sono richiesti JOIN tra i dati dei nodi. Questo è utile anche per separare i dati e averli in diverse posizioni geografiche.
Sebbene entrambe queste tecniche di ridimensionamento presentino vantaggi e svantaggi, un buon ambiente può combinarle entrambe per ottenere un'eccezionale scalabilità verticale e orizzontale. Possiamo avere un database di lettura e scrittura con scalabilità verticale in un unico server che richiede proprietà ACID e avere dati storici distribuiti con scalabilità orizzontale su diversi nodi per scopi di data mining.