Cos'è ClickHouse?

ClickHouse è un DBMS (o sistema di gestione di database) orientato alle colonne open source utilizzato principalmente per OLAP (o l'elaborazione analitica online delle query). È in grado di generare rapidamente dati analitici in tempo reale e di creare report utilizzando query SQL. È tollerante ai guasti, scalabile, altamente affidabile e contiene un set di strumenti ricco di funzionalità.
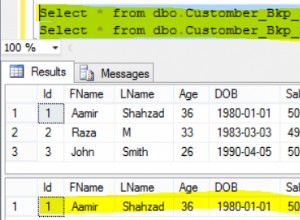
In un database normale, i dati vengono archiviati in tabelle, colonne e righe. In una tabella, i valori correlati vengono archiviati fisicamente fianco a fianco in una riga, il che è fondamentale per il suo funzionamento. Questo è il modo in cui funzionano la maggior parte dei database di tipo stringa.
Alcuni esempi di questa forma di database sono:
- MySQL
- Postgres
- SQLite
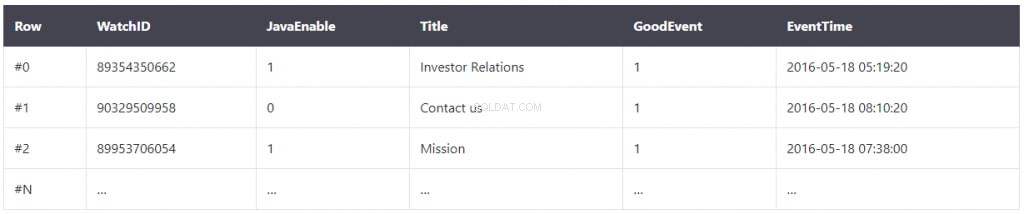
I dati vengono archiviati come mostrato di seguito in un database a colonne:
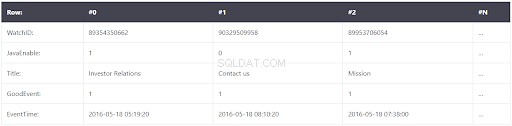
Sembra simile, ma le differenze sono le seguenti:i valori di colonne diverse vengono archiviati separatamente, mentre i dati di una colonna vengono archiviati insieme. Esempi di tabelle orientate a colonne:
- Vertica
- InfiniDB
- Google Dremel
Tali record di archiviazione di DBMS in blocchi, raggruppati per colonne anziché per righe. Non caricando i dati per le colonne, trascorrono meno tempo a leggere i dati durante l'esecuzione di query, consentendo ai DBMS di calcolare i dati e restituire risultati molto più velocemente rispetto ai database raggruppati in blocchi. In genere, i database orientati alle colonne vengono applicati al meglio negli scenari OLAP, dove di solito sono 100 volte più veloci nell'elaborazione della maggior parte delle query rispetto ai database di tipo stringa.
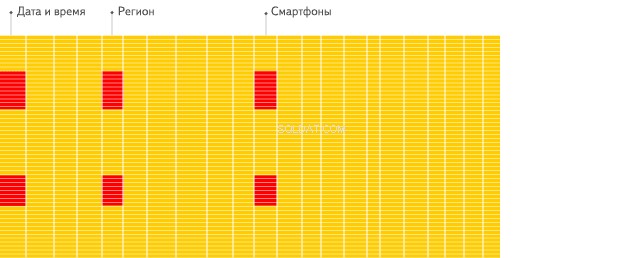
Come possiamo vedere dalle illustrazioni sopra, OLAP ci consente di organizzare grandi quantità di dati ed eseguire query complesse di più ordini di grandezza più velocemente di un tipico database. Pertanto, è estremamente utile per lavorare con grandi quantità di input durante l'analisi dei dati e/o è richiesta un'analisi aziendale.
Utilizzo SQL
ClickHouse utilizza un dialetto di SQL, che è simile al linguaggio di query strutturato standard, ma contiene estensioni aggiuntive:vari array, funzioni di ordine superiore, strutture nidificate, funzioni per lavorare con gli URL e la possibilità di lavorare con un dizionario esterno, ecc.
Mentre guadagniamo velocità e elaborazione dei big data, perdiamo anche altri aspetti, tra cui le seguenti opzioni:
- Mancanza di transazioni.
- Tipi di dati potenti con necessità di casting esplicito.
- Deve memorizzare i dati intermedi nella RAM per alcune operazioni.
- Mancanza di un Query Optimizer completo.
- Lettura puntuale dei dati in un database.
Nonostante ciò, ClickHouse dimostra prestazioni elevate e vince contro i suoi numerosi concorrenti. ClickHouse è stato sviluppato per risolvere i problemi di analisi web per Yandex.Metrica, il terzo sistema di analisi web più popolare al mondo. Viene anche utilizzato da Cloudflare per elaborare le statistiche del sito Web per i suoi utenti.
Prerequisiti
Per installare, abbiamo bisogno di:
- Un server a 2 core che utilizza almeno 2 GB di RAM
- Un sistema operativo Ubuntu 20.04 LTS
- Accesso all'account utente root (come tutte le azioni eseguite come root).
Installazione di ClickHouse su Ubuntu 20.04
Prima dell'installazione, aggiorneremo il sistema e i pacchetti sul server.
root@host:~# apt update && apt -y upgrade
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Hit:5 https://download.docker.com/linux/ubuntu focal InRelease
Hit:6 https://debian.neo4j.com stable InRelease
Fetched 109 kB in 0s (231 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
Reading package lists... Done
Building dependency tree
Reading state information... Done
Calculating upgrade... Done
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
root@host:~# Yandex mantiene un repository con l'ultima versione di ClickHouse, quindi dobbiamo aggiungerlo. Inoltre, aggiungi una chiave GPG per controllare il repository e installare in sicurezza ClickHouse e futuri aggiornamenti.
root@host:~# apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4
Executing: /tmp/apt-key-gpghome.5KK4WZQb0R/gpg.1.sh --keyserver keyserver.ubuntu.com --recv E0C56BD4
gpg: key C8F1E19FE0C56BD4: public key "ClickHouse Repository Key <milovidov@yandex-team.ru>" imported
gpg: Total number processed: 1
gpg: imported: 1
root@host:~# Aggiungi il repository all'elenco dei repository APK.
root@host:~# echo "deb https://repo.yandex.ru/clickhouse/deb/stable/ main/" | tee /etc/apt/sources.list.d/clickhouse.list
deb https://repo.yandex.ru/clickhouse/deb/stable/ main/
root@host:~# Successivamente, aggiorniamo i nostri pacchetti di server.
root@host:~# apt update
Hit:1 https://by.archive.ubuntu.com/ubuntu focal InRelease
Hit:2 https://by.archive.ubuntu.com/ubuntu focal-updates InRelease
Hit:3 https://by.archive.ubuntu.com/ubuntu focal-backports InRelease
Get:4 https://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Ign:5 https://repo.yandex.ru/clickhouse/deb/stable main/ InRelease
Get:6 https://repo.yandex.ru/clickhouse/deb/stable main/ Release [749 B]
Get:7 https://repo.yandex.ru/clickhouse/deb/stable main/ Release.gpg [836 B]
Hit:8 https://download.docker.com/linux/ubuntu focal InRelease
Get:9 https://repo.yandex.ru/clickhouse/deb/stable main/ Packages [152 kB]
Hit:10 https://debian.neo4j.com stable InRelease
Fetched 263 kB in 0s (536 kB/s)
Reading package lists... Done
Building dependency tree
Reading state information... Done
All packages are up to date.
root@host:~#Infine, possiamo installare ClickHouse. Quando richiesto, inserisci una password.
root@host:~# apt install -y clickhouse-server clickhouse-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
clickhouse-common-static
Suggested packages:
clickhouse-common-static-dbg
The following NEW packages will be installed:
clickhouse-client clickhouse-common-static clickhouse-server
0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded.
Need to get 119 MB of archives.
After this operation, 401 MB of additional disk space will be used.
...
Preconfiguring packages ...
Selecting previously unselected package clickhouse-common-static.
(Reading database ... 164995 files and directories currently installed.)
Preparing to unpack .../clickhouse-common-static_20.12.5.14_amd64.deb ...
Unpacking clickhouse-common-static (20.12.5.14) ...
Selecting previously unselected package clickhouse-client.
Preparing to unpack .../clickhouse-client_20.12.5.14_all.deb ...
Unpacking clickhouse-client (20.12.5.14) ...
Selecting previously unselected package clickhouse-server.
Preparing to unpack .../clickhouse-server_20.12.5.14_all.deb ...
Unpacking clickhouse-server (20.12.5.14) ...
Setting up clickhouse-common-static (20.12.5.14) ...
Setting up clickhouse-server (20.12.5.14) ...
ClickHouse init script has migrated to systemd. Please manually stop old server
and restart the service: killall clickhouse-server && sleep 5 && servi
ce clickhouse-server restart
Synchronizing state of clickhouse-server.service with SysV service script with /
lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable clickhouse-server
Created symlink /etc/systemd/system/multi-user.target.wants/clickhouse-server.se
rvice → /etc/systemd/system/clickhouse-server.service.
Copying ClickHouse binary to /usr/bin/clickhouse.new
/usr/bin/clickhouse already exists, will rename existing binary to /usr/bin/clic
khouse.old and put the new binary in place
Renaming /usr/bin/clickhouse.new to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-server already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-server to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-client already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-client to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-local already exists but it points to /clickhouse. W
ill replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-local to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-benchmark already exists but it points to /clickhous
e. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-benchmark to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-copier already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-copier to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-obfuscator already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-obfuscator to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-git-import to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-compressor already exists but it points to /clickhou
se. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-compressor to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-format already exists but it points to /clickhouse.
Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-format to /usr/bin/clickhouse.
Symlink /usr/bin/clickhouse-extract-from-config already exists but it points to
/clickhouse. Will replace the old symlink to /usr/bin/clickhouse.
Creating symlink /usr/bin/clickhouse-extract-from-config to /usr/bin/clickhouse.
Creating clickhouse group if it does not exist.
groupadd -r clickhouse
Creating clickhouse user if it does not exist.
useradd -r --shell /bin/false --home-dir /nonexistent -g clickhouse clickhouse
Will set ulimits for clickhouse user in /etc/security/limits.d/clickhouse.conf.
Creating config directory /etc/clickhouse-server/config.d that is used for tweak
s of main server configuration.
Creating config directory /etc/clickhouse-server/users.d that is used for tweaks
of users configuration.
Config file /etc/clickhouse-server/config.xml already exists, will keep it and e
xtract path info from it.
/etc/clickhouse-server/config.xml has /var/lib/clickhouse/ as data path.
/etc/clickhouse-server/config.xml has /var/log/clickhouse-server/ as log path.
Users config file /etc/clickhouse-server/users.xml already exists, will keep it
and extract users info from it.
chown --recursive clickhouse:clickhouse '/etc/clickhouse-server'
Creating log directory /var/log/clickhouse-server/.
Creating data directory /var/lib/clickhouse/.
Creating pid directory /var/run/clickhouse-server.
chown --recursive clickhouse:clickhouse '/var/log/clickhouse-server/'
chown --recursive clickhouse:clickhouse '/var/run/clickhouse-server'
chown clickhouse:clickhouse '/var/lib/clickhouse/'
Password for default user is already specified. To remind or reset, see /etc/cli
ckhouse-server/users.xml and /etc/clickhouse-server/users.d.
Setting capabilities for clickhouse binary. This is optional.
command -v setcap >/dev/null && echo > /tmp/test_setcap.sh && chmod a+x /tmp/te
st_setcap.sh && /tmp/test_setcap.sh && setcap 'cap_net_admin,cap_ipc_lock,cap_sy
s_nice+ep' /tmp/test_setcap.sh && /tmp/test_setcap.sh && rm /tmp/test_setcap.sh
&& setcap 'cap_net_admin,cap_ipc_lock,cap_sys_nice+ep' /usr/bin/clickhouse || ec
ho "Cannot set 'net_admin' or 'ipc_lock' or 'sys_nice' capability for clickhouse
binary. This is optional. Taskstats accounting will be disabled. To enable task
stats accounting you may add the required capability later manually."
ClickHouse has been successfully installed.
Start clickhouse-server with:
clickhouse start
Start clickhouse-client with:
clickhouse-client --password
Setting up clickhouse-client (20.12.5.14) ...
Processing triggers for systemd (245.4-4ubuntu3.3) ...
root@host:~# Avvia il servizio ClickHouse
Ora che abbiamo installato ClickHouse, eseguiamolo in background.
root@host:~# service clickhouse-server start
root@host:~# Verifica stato
In questo passaggio, controlliamo semplicemente che tutto funzioni come previsto.
root@host:~# service clickhouse-server status
● clickhouse-server.service - ClickHouse Server (analytic DBMS for big data)
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s ago
Main PID: 5553 (clickhouse-serv)
Tasks: 48 (limit: 9489)
Memory: 45.8M
CGroup: /system.slice/clickhouse-server.service
└─5553 /usr/bin/clickhouse-server --config=/etc/clickhouse-server/>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:26 host clickhouse-server[5553]: Logging trace to /var/log/clickho>
сне 30 22:08:26 host clickhouse-server[5553]: Logging errors to /var/log/clickh>
сне 30 22:08:26 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:26 host clickhouse-server[5553]: Include not found: networks
сне 30 22:08:26 host clickhouse-server[5553]: Saved preprocessed configuration >
сне 30 22:08:28 host clickhouse-server[5553]: Processing configuration file '/e>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_rem>
сне 30 22:08:28 host clickhouse-server[5553]: Include not found: clickhouse_com>
сне 30 22:08:28 host clickhouse-server[5553]: Saved preprocessed configuration >
lines 1-19/19 (END)Le righe seguenti sono quelle a cui dobbiamo prestare molta attenzione.
Loaded: loaded (/etc/systemd/system/clickhouse-server.service; enabled; ve>
Active: active (running) since Wed 2020-12-30 22:08:26 +03; 25s agoConfigura il firewall
Se non stai utilizzando un firewall, salta questo passaggio. Se prevedi di connetterti in remoto e hai un firewall abilitato, questo passaggio è necessario. Apri e modifica il file di configurazione e decommenta la riga sottostante.
<!-- <listen_host>0.0.0.0</listen_host> →Una volta completata la modifica, salva il file utilizzando Ctrl+S e CTRL+X chiavi, quindi riavvia il servizio ClickHouse.
root@host:~# service clickhouse-server restart
root@host:~# Porte aperte
Quindi, apri la porta 8123 nel firewall per consentire l'accesso al tuo indirizzo IP.
ufw allow from YOUR_IP_SERVER/32 to any port 8123Quindi, apri la porta 9000 per i client-clickhouse Indirizzo IP.
root@host:~# ufw allow from 192.168.13.1/32 to any port 8123
Rules updated
root@host:~#
root@host:~# ufw allow from 192.168.13.1/32 to any port 9000
Rules updated
root@host:~# Verifica connessione
Per verificare che tutto funzioni quando ci si connette da remoto, utilizzare la seguente query.
clickhouse-client --host 192.168.13.1 --passwordroot@host:~# clickhouse-client --host 192.168.13.1 --password
Password for user (default):
Connecting to 192.168.13.1:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :)Apprendimento dei comandi e delle interazioni di base
In ClickHouse, possiamo creare e rilasciare database utilizzando la sintassi SQL modificata. Diamo un'occhiata agli esempi seguenti. Per prima cosa, connettiamoci a ClickHouse.
root@host:~# clickhouse-client
ClickHouse client version 20.12.5.14 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Crea database
Una volta che siamo nella riga di comando di ClickHouse, creiamo un database chiamato liquidweb usando la seguente sintassi.
host :) CREATE DATABASE liquidweb;
CREATE DATABASE liquidweb
Query id: 9169dbaa-402e-4d37-828f-5fde43d4a91d
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) In ClickHouse, la tabella è quasi la stessa di altri database con un insieme di dati correlati in un formato strutturato. Possiamo specificare le colonne e i loro tipi, aggiungere righe ed eseguire vari tipi di query sul DB.
Crea tabella
Prima di creare una tabella, è importante conoscere e comprendere i tipi di colonne disponibili per l'uso. Sono possibili i seguenti tipi di colonna:
- UInt64 — Questa tabella viene utilizzata per memorizzare numeri interi compresi tra 0 e 18446744073709551615.
- Float64 — Ogni tabella che utilizza Float64 può memorizzare numeri in virgola mobile come 10.5, 18754.067, ecc.
- Stringa — Qui, la tabella delle stringhe sostituisce VARCHAR, BLOB, CLOB e altri tipi di DBMS diversi
- Data — Questa tabella viene utilizzata per memorizzare le date nel formato AAAA-MM-GG.
- DataOra — Qui, la tabella DateTime viene utilizzata per memorizzare date e ore nel formato più preciso AAAA-MM-GG HH:MM:SS
Strutture di dati
ClickHouse definisce la struttura dei dati sottostanti descrivendo i dati esatti, la possibilità di interrogare la tabella, le sue modalità di accesso simultaneo alla tabella e il supporto per gli indici. ClickHouse ha diverse capacità adatte a diverse condizioni d'uso.
UnisciAlbero
Il meccanismo più utilizzato è l'operazione del motore di tabella denominata MergeTree . Questa funzione è progettata per inserire grandi quantità di dati in una tabella. È altamente raccomandato per l'uso del database di produzione grazie al suo supporto ottimizzato per l'inserimento di grandi quantità di risorse in tempo reale, nonché alla sua affidabilità e supporto per le query.
Seleziona Database
Procediamo con ulteriore pratica. Per prima cosa, selezioniamo un database in cui creeremo una tabella.
host :) USE liquidweb;
USE liquidweb
Query id: aba15bcb-224b-426d-9f74-350a88346115
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Crea tabella
Successivamente, creiamo una tabella chiamata colleghi .
host :) CREATE TABLE colleagues ( id UInt64, name String, url String, created DateTime ) ENGINE = MergeTree() PRIMARY KEY id ORDER BY id;
CREATE TABLE colleagues
(
`id` UInt64,
`name` String,
`url` String,
`created` DateTime
)
ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY id
Query id: 08223a2f-d365-43cb-8627-d22674d1c47c
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :) Esaminiamo quali valori abbiamo aggiunto.
- id - Questa è la colonna della chiave primaria. Ogni riga deve avere un identificatore univoco.
- nome - Una colonna con un valore stringa.
- URL - Una colonna con un valore stringa che contiene un collegamento al profilo.
- creato - La data in cui il dipendente è apparso nel sistema.
Dopo aver definito le colonne nella tabella, specifichiamo il MergeTree meccanismo per riporre la tavola. Successivamente, designiamo le colonne, quindi definiamo le colonne a livello di tabella.
- CHIAVE PRIMARIA - Specifica la colonna della chiave primaria.
- ORDINA PER - I valori della tabella memorizzati sono ordinati per colonna id.
Aggiungi dati
Ora possiamo lavorare con il tavolo. Aggiungiamo alcuni dati ai colleghi tabella.
host :) INSERT INTO colleagues VALUES (1, 'margaret', 'https://1.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 42dbde52-6d7e-4849-ac5e-280590f3232d
Ok.
1 rows in set. Elapsed: 0.002 sec.
host :) Aggiungiamo più dati.
host :) INSERT INTO colleagues VALUES (2, 'john', 'https://2.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: a9b34f78-2caa-4b41-bd4e-91bf8049a04b
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :)host :) INSERT INTO colleagues VALUES (3, 'kingsman', 'https://3.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: df5133c1-b404-4569-8123-f0728c172c87
Ok.
1 rows in set. Elapsed: 0.003 sec.
host :) host :) INSERT INTO colleagues VALUES (4, 'tor', 'https://4.com', '2021-01-01 00:01:01');
INSERT INTO colleagues VALUES
Query id: 14f56b86-fae7-4af2-b506-18c351b92853
Ok.
1 rows in set. Elapsed: 0.001 sec.
host :) Aggiungi colonna
Mentre abbiamo aggiunto alcuni valori, ci siamo resi conto che ci siamo dimenticati di aggiungere un'altra colonna, quindi dobbiamo aggiungerla di seguito.
host :) ALTER TABLE colleagues ADD COLUMN location String;
ALTER TABLE colleagues
ADD COLUMN `location` String
Query id: 002900f4-9fd9-4302-a10f-6aa5b818f9ae
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :)Modifica dati
Ora dobbiamo cambiare i vecchi dati in qualche modo. Nella versione 19.13, ClickHouse non supporta l'aggiornamento e l'eliminazione di singole righe a causa della sua implementazione. Tuttavia, ClickHouse supporta aggiornamenti ed eliminazioni in blocco e ha anche una propria sintassi per queste operazioni.
Ora aggiorniamo le nostre linee.
host :) ALTER TABLE colleagues UPDATE url ='https://1.com' WHERE id < 15;
ALTER TABLE colleagues
UPDATE url = 'https://1.com' WHERE id < 15
Query id: 6fc6620e-fd90-43aa-8d7f-8a34cfb73650
Ok.
0 rows in set. Elapsed: 0.004 sec.
host :)Dopo DOVE , impostiamo i parametri del filtro e possiamo anche eliminare i parametri non necessari.
host :) ALTER TABLE colleagues DELETE WHERE id < 2;
ALTER TABLE colleagues
DELETE WHERE id < 2
Query id: 354e27fc-70c9-480b-bb1d-067591924c6e
Ok.
0 rows in set. Elapsed: 0.005 sec.
host :) Rimuovi colonna
Per rimuovere colonne da una tabella, procedi come segue.
host :) ALTER TABLE colleagues DROP COLUMN location;
ALTER TABLE colleagues
DROP COLUMN location
Query id: da361478-0619-4c31-8422-f59ee14a57d7
Ok.
0 rows in set. Elapsed: 0.008 sec.
host :) Recupero dei dati tramite query
Successivamente, passiamo a dimostrare il recupero dei dati utilizzando le query. ClickHouse utilizza la sintassi SQL qui con le sue aggiunte. Proviamo a raccogliere alcune informazioni di base.
host :) SELECT url, name FROM colleagues WHERE url = 'https://1.com' LIMIT 1;
SELECT
url,
name
FROM colleagues WHERE url = 'https://1.com'
LIMIT 1
Query id: 8a5cbf9a-f187-440c-9a60-2d23029b4bd1
┌─url──────────┬─name─┐
│ https://1.com │ john │
└──────────────┴──────┘
1 rows in set. Elapsed: 0.003 sec.
host :) - SELEZIONARE - Seleziona diversi parametri.
- DA - Determina quale tabella riceveremo valori.
- DOVE - Impostare i parametri ei filtri riguardo a quale valore e quanto.
Possiamo anche utilizzare parametri di ricerca aggiuntivi, come:
- conta - Restituisce il numero di righe che soddisfano le condizioni.
- somma - Restituisce la somma dei valori selezionati.
- media - Restituisce la media degli articoli selezionati.
- uniq - Restituisce il numero approssimativo di singole righe abbinate.
- topK - Restituisce una matrice dei valori più frequenti di una colonna specifica utilizzando un algoritmo.
Tabelle a goccia e database
Successivamente, passiamo all'eliminazione di tabelle e database. Per prima cosa, eliminiamo una tabella.
host :) DROP TABLE colleagues;
DROP TABLE colleagues
Query id: 21048fe4-d379-48ac-b9a7-71f0b3fe93e1
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Ora, elimina il database.
host :) DROP DATABASE liquidweb;
DROP DATABASE liquidweb
Query id: 4ad9a51a-f89d-4be5-be9c-92b8cb38614b
Ok.
0 rows in set. Elapsed: 0.001 sec.
host :) Per uscire dal database, inserisci il valore standard 'exit'.
host :) exit
Bye.
root@host:~# Crea un utente
Ora che abbiamo coperto tutte le funzionalità di base, creeremo diversi utenti di database. Il file di configurazione di ClickHouse può trovarsi nel seguente percorso /etc/clickhouse-client/config.xml. Vai a questo file, aprilo con vim o nano e specifica i valori nel seguente ordine.
<config> <user>username</user> <password>password</password> <secure>False</secure></config>Useremo l'editor nano per modificare il file.
root@host:~# nano /etc/clickhouse-client/config.xml
root@host:~# Inserisci le informazioni richieste e quindi salva le modifiche utilizzando Ctrl+S e CTRL+X chiavi
Connetti a ClickHouse
Infine, per connetterti a ClickHouse, inserisci il seguente comando nel terminale.
root@host:~# clickhouse-client -u margaret --password
ClickHouse client version 20.12.5.14 (official build).
Password for user (margaret):
Connecting to localhost:9440 as user margaret.
Connected to ClickHouse server version 20.12.5 revision 54442.
host :) Conclusione
In questo tutorial abbiamo scoperto molti aspetti di ClickHouse. Abbiamo scoperto come funziona, quando può essere applicato e in quali circostanze è utile. Abbiamo identificato come aggiungere una chiave, il repository e quindi installare il software ClickHouse. Allo stesso modo, abbiamo quindi impostato e configurato il firewall per consentire l'accesso. Inoltre, abbiamo creato database e tabelle, aggiunto colonne e dati, quindi aggiornati ed eliminati. Infine, abbiamo dimostrato come creare utenti nel file di configurazione.
Siamo orgogliosi di essere gli esseri umani più utili nell'hosting™! I nostri team di supporto sono pieni di tecnici Linux esperti e amministratori di sistema di talento che hanno una profonda conoscenza di più tecnologie di hosting web, comprese quelle discusse in questo articolo.
Se hai domande in merito a questo articolo, siamo sempre disponibili disponibile a fornire informazioni per qualsiasi domanda relativa a questo articolo, 24 ore al giorno, 7 giorni alla settimana 365 giorni all'anno.
Se sei un server VPS completamente gestito, dedicato al cloud, cloud privato VMWare, server padre privato, server cloud gestiti o proprietario di un server dedicato e ti senti a disagio nell'esecuzione di uno qualsiasi dei passaggi descritti, siamo raggiungibili telefonicamente al numero @800.580.4985, una chat o un ticket di supporto per assisterti in questo processo.