Scopri l'architettura di acquisizione dati quasi in tempo reale per trasformare e arricchire i flussi di dati utilizzando Apache Flume, Apache Kafka e RocksDB a Santander UK.
Cloudera Professional Services ha collaborato con Santander UK per creare un sistema di analisi transazionale quasi in tempo reale (NRT) su Apache Hadoop. L'obiettivo è acquisire, trasformare, arricchire, contare e archiviare una transazione entro pochi secondi dall'acquisto di una carta. Il sistema riceve le transazioni delle carte dei clienti al dettaglio della banca e calcola le informazioni sull'andamento associate aggregate per titolare del conto e su una serie di dimensioni e tassonomie. Queste informazioni vengono quindi fornite in modo sicuro all'app "Spendlytics" di Santander (vedi sotto) per consentire ai clienti di analizzare i loro ultimi modelli di spesa.
Apache HBase è stato scelto come soluzione di archiviazione sottostante per la sua capacità di supportare scritture casuali ad alto throughput e letture casuali a bassa latenza. Tuttavia, il requisito NRT escludeva l'esecuzione di trasformazioni e arricchimento delle transazioni in batch, quindi queste devono essere eseguite mentre le transazioni vengono trasmesse in streaming in HBase. Ciò include la trasformazione dei messaggi da XML ad Avro e l'arricchimento con informazioni di tendenza, come le informazioni sul marchio e sul commerciante.
Questo post descrive come Santander utilizza Apache Flume, Apache Kafka e RocksDB per trasformare, arricchire e trasmettere le transazioni in HBase. Questa è un'implementazione dell'Elaborazione di eventi NRT con contesto esterno pattern di streaming descritto da Ted Malaska in questo post.
Flasca
La prima decisione che Santander ha dovuto prendere è stata il modo migliore per trasmettere i dati in HBase. Flume è quasi sempre la scelta migliore per l'importazione di streaming in Hadoop data la sua semplicità, affidabilità, ricca gamma di sorgenti e sink e scalabilità intrinseca.
Di recente, è stata aggiunta un'eccellente integrazione a Kafka che porta all'inevitabile Flafka. Flume può fornire in modo nativo la consegna degli eventi garantita attraverso il suo canale di file, ma la capacità di riprodurre gli eventi e la maggiore flessibilità e la funzionalità a prova di futuro offerti da Kafka sono stati fattori chiave per l'integrazione.
In questa architettura, Santander utilizza i canali Kafka per fornire un buffer di importazione affidabile, autobilanciato e scalabile in cui tutte le trasformazioni e le elaborazioni sono rappresentate in argomenti Kafka concatenati. In particolare, facciamo ampio uso della sorgente e del pozzo di Flafka e della capacità di Flume di eseguire l'elaborazione in volo utilizzando gli Interceptor. Ciò ci ha impedito di dover codificare il nostro produttore e consumatore Kafka e ha consentito a Santander di sfruttare appieno Cloudera Manager per configurare, distribuire e monitorare agenti e broker.
Trasformazione
Le transazioni acquisite dai sistemi bancari principali vengono consegnate a Flume come messaggi XML, dopo essere state lette dal database di origine tramite la replica dei log. (L'inserimento di un registro del database negli argomenti di Kafka in questo modo è un modello sempre più comune e, combinato con la compattazione dei registri, può fornire una "vista più recente" del database per modificare i casi d'uso dell'acquisizione dei dati.)
Flume memorizza questi messaggi XML in un argomento Kafka "grezzo". Da qui, e come precursore di tutte le altre elaborazioni, si è deciso di trasformare l'XML semistrutturato in record binari strutturati per facilitare l'elaborazione a valle standardizzata. Questa elaborazione viene eseguita da un Flume Interceptor personalizzato che trasforma i messaggi XML in una rappresentazione Avro generica, applicando tipi specifici ove appropriato e ricorrendo a una rappresentazione di stringa laddove non lo sia. Tutte le successive elaborazioni NRT archiviano quindi i risultati derivati in Avro in argomenti Kafka dedicati, semplificando l'accesso allo stream e ottenendo un feed di eventi in qualsiasi punto della catena di elaborazione.
Se fosse necessaria un'elaborazione di eventi più complessa, ad esempio aggregazioni con Spark Streaming, sarebbe banale consumare uno o più di questi argomenti e pubblicare in nuovi argomenti derivati. (Apache Avro è una scelta naturale per questo formato:è un protocollo binario compatto che supporta l'evoluzione dello schema, ha una definizione dello schema flessibile ed è supportato in tutto lo stack Hadoop. Avro sta rapidamente diventando uno standard de facto per l'archiviazione di dati provvisori e generali in un hub dati aziendale ed è perfettamente posizionato per la trasformazione in Apache Parquet per carichi di lavoro di analisi.)
Arricchimento
L'ispirazione per la progettazione della soluzione di arricchimento in streaming è venuta da un post su O'Reilly Radar scritto da Jay Kreps. Nel suo post, Jay descrive i vantaggi dell'utilizzo di un archivio locale per consentire a un processore di flusso di interrogare o modificare uno stato locale in risposta al suo input, invece di effettuare chiamate remote a un database distribuito.
In Santander, abbiamo adattato questo modello per fornire negozi di riferimento locali che vengono utilizzati per interrogare e arricchire le transazioni mentre scorrono attraverso Flume. Perché non utilizzare semplicemente HBase come negozio di riferimento? Bene, un modello tipico per questo tipo di problema è semplicemente memorizzare lo stato in HBase e fare in modo che il meccanismo di arricchimento lo interroghi direttamente. Abbiamo deciso contro questo approccio per un paio di motivi. In primo luogo, i dati di riferimento sono relativamente piccoli e si adatterebbero a una singola regione HBase, causando probabilmente un hotspot di regione. In secondo luogo, HBase serve l'app Spendlytics rivolta al cliente e Santander non voleva che il carico aggiuntivo influisse sulla latenza dell'app o viceversa. Questo è anche il motivo per cui abbiamo deciso di non utilizzare HBase nemmeno per eseguire il bootstrap degli store locali all'avvio.
Pertanto, fornendo a ciascun agente Flume un negozio locale veloce per arricchire gli eventi in volo, Santander è in grado di fornire migliori garanzie di prestazioni sia per l'arricchimento in volo che per l'app Spendlytics. Abbiamo deciso di utilizzare RocksDB per implementare gli store locali perché è in grado di fornire un accesso rapido a grandi quantità di dati off-heap (eliminando il carico su GC) e per il fatto che ha un'API Java per semplificarne l'utilizzo da un intercettore di flusso personalizzato. Questo approccio ci ha evitato di dover codificare il nostro negozio off-heap. RocksDB può essere facilmente sostituito con un'altra implementazione del negozio locale, ma in questo caso si adattava perfettamente al caso d'uso di Santander.
L'implementazione personalizzata di Flume Arricchimento Interceptor elabora gli eventi dall'argomento "trasformato" a monte, interroga il suo negozio locale per arricchirli e scrive i risultati negli argomenti Kafka a valle a seconda del risultato. Questo processo è illustrato più dettagliatamente di seguito.
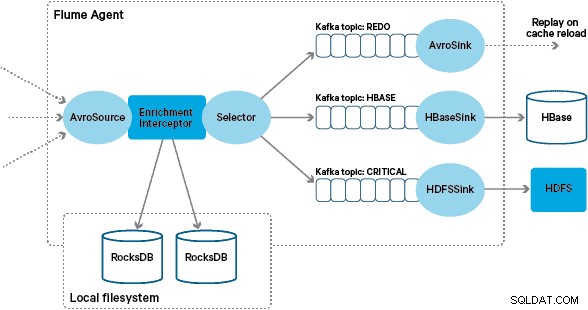
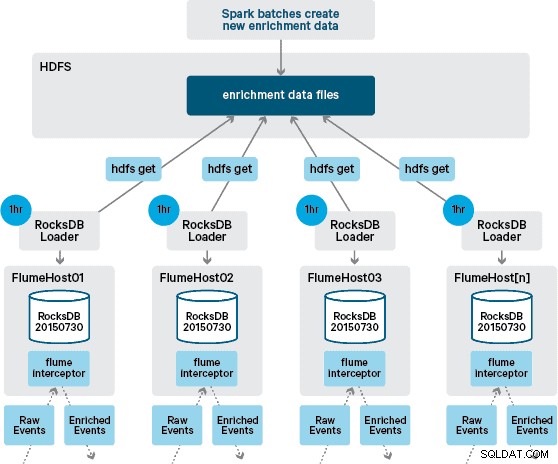
A questo punto ti starai chiedendo:senza la persistenza fornita da HBase, come vengono generati gli archivi locali? I dati di riferimento comprendono una serie di set di dati diversi che devono essere uniti. Questi set di dati vengono aggiornati quotidianamente in HDFS e costituiscono l'input per un'applicazione Apache Spark pianificata, che genera gli archivi RocksDB. Gli store RocksDB di nuova generazione vengono organizzati in HDFS fino a quando non vengono scaricati dagli agenti Flume per garantire che il flusso dell'evento venga arricchito con le informazioni più recenti.
Idealmente, non dovremmo aspettare che questi set di dati siano tutti disponibili in HDFS prima che possano essere elaborati. In tal caso, gli aggiornamenti dei dati di riferimento potrebbero essere trasmessi in streaming attraverso il gasdotto Flafka per mantenere continuamente lo stato dei dati di riferimento locali.
Nella nostra progettazione iniziale avevamo pianificato di scrivere e programmare tramite cron uno script per eseguire il polling di HDFS per verificare la presenza di nuove versioni degli store RocksDB, scaricandole da HDFS quando disponibili. Anche se a causa dei controlli interni e della governance degli ambienti di produzione di Santander, questo meccanismo doveva essere incorporato nello stesso Flume Interceptor utilizzato per eseguire l'arricchimento (verifica gli aggiornamenti una volta all'ora, quindi non è un'operazione costosa). Quando è disponibile una nuova versione del negozio, un'attività viene inviata a un thread di lavoro per scaricare il nuovo negozio da HDFS e caricarlo in RocksDB. Questo processo avviene in background mentre l'arricchimento Interceptor continua a elaborare il flusso. Una volta che la nuova versione del negozio è stata caricata in RocksDB, Interceptor passa all'ultima versione e il negozio scaduto viene eliminato. Lo stesso meccanismo viene utilizzato per avviare gli archivi RocksDB da un avvio a freddo prima che Interceptor inizi a tentare di arricchire gli eventi.
I messaggi arricchiti correttamente vengono scritti in un argomento Kafka per essere scritti in modo idempotente in HBase utilizzando HBaseEventSerializer.
Sebbene il flusso di eventi venga elaborato su base continua, le nuove versioni dell'archivio locale possono essere generate solo giornalmente. Immediatamente dopo che una nuova versione del negozio locale è stata caricata da Flume, è considerata fresca", sebbene diventi sempre più obsoleta prima della disponibilità di una nuova versione. Di conseguenza, il numero di "cache mancate" aumenta fino a quando non sarà disponibile una versione più recente del negozio locale. Ad esempio, ai dati di riferimento possono essere aggiunte informazioni nuove e aggiornate su marchi e commercianti, ma fino a quando non saranno rese disponibili all'arricchimento di Flume le transazioni di Interceptor possono non essere arricchite, oppure essere arricchite con informazioni scadute che in seguito devono essere riconciliato dopo che è stato mantenuto in HBase.
Per gestire questo caso, i cache miss (eventi che non possono essere arricchiti) vengono scritti in un argomento Kafka "rifai" utilizzando un Flume Selector. L'argomento di ripristino viene quindi riprodotto nell'argomento di origine di Interceptor di arricchimento quando è disponibile un nuovo negozio locale.
Per evitare "messaggi velenosi" (eventi che non riescono continuamente ad arricchirsi), abbiamo deciso di aggiungere un contatore all'intestazione di un evento prima di aggiungerlo all'argomento di ripristino. Gli eventi che compaiono ripetutamente su quell'argomento vengono infine reindirizzati a un argomento "critico", che viene scritto in HDFS per un'ispezione e una correzione successive. Questo approccio è illustrato nel primo diagramma.
Conclusione
Per riassumere i principali punti da asporto di questo post:
- L'utilizzo di una catena di argomenti Kafka per archiviare dati condivisi intermedi come parte della pipeline di acquisizione è un modello efficace.
- Sono disponibili più opzioni per la persistenza e l'esecuzione di query sui dati di stato o di riferimento nella pipeline di acquisizione NRT. Preferisci HBase per questo scopo come modello comune quando i dati supplementari sono di grandi dimensioni, ma considera l'uso di archivi locali incorporati (come RocksDB) o memoria JVM per quando si utilizza HBase non è pratico.
- La gestione degli errori è importante. (Vedi n. 1 per assistenza su questo.)
In un post di follow-up, descriveremo come utilizziamo i coprocessori HBase per fornire aggregazioni per cliente delle tendenze di acquisto storiche e come le transazioni offline vengono elaborate in batch utilizzando (progetto Cloudera Labs) SparkOnHBase (che è stato recentemente impegnato nel Tronco HBase). Descriveremo anche come è stata progettata la soluzione per soddisfare i requisiti di alta disponibilità e cross-datacenter del cliente.
James Kinley, Ian Buss e Rob Siwicki sono Solution Architect di Cloudera.



