Meteor è configurato per collegarsi a un database mongo esterno . Hai impacchettato mongo su un'app di sviluppo locale, ma questo è solo per comodità e facile integrazione.
In produzione dovrai sempre connettere Meteor alla tua istanza Mongo in esecuzione utilizzando il MONGO_URL variabile d'ambiente
.
Bonus:puoi impostare il MONGO_URL anche in modalità dev per connettersi a un db specifico in modalità dev. Tieni presente che puoi CRUD tutto su questo db, usa con cura.
Sotto il cofano Meteor usa il driver node mongo. In pratica puoi utilizzare tutte le API di questo driver (vedi questo post per i dettagli su come chiamare i metodi Mongo nativi)
Con il sistema di pubblicazione/abbonamento di Meteor fondamentalmente controlli quali dati vengono pubblicati sul client. Le pubblicazioni vengono eseguite ogni volta che i dati cambiano (simile al pattern osservatore).
Se tutti i tuoi clienti si iscrivono ai dati di una raccolta, riceveranno gli aggiornamenti, una volta che la raccolta si aggiorna. E ora arriviamo alla tua funzione più ricercata:funziona anche se questi dati vengono aggiornati da una fonte esterna.
Funziona anche con intervalli di aggiornamento molto rapidi. Ho lavorato a un progetto recente in cui enormi quantità di dati sono state aggiornate tramite Python su una raccolta Mongo-DB. L'app Meteor l'ha ascoltata e ha mostrato i dati ai clienti in "tempo reale" (o ciò che gli utenti percepiscono come tempo reale).
Tuttavia, ci sono alcune insidie ed è bene conoscerle in anticipo.
-
Meteor crea documenti con un
_iddi tipo stringa e nonMongo.ObjectID. Tuttavia è in grado di leggerlo e scriverlo se lo usi correttamente . -
Meteor avvolge le raccolte con una propria API che integra al meglio la collezione con le sue
fibersambiente basato. Se è necessario utilizzare funzionalità oltre, leggere qui e qui . -
Cursori restituiti si comportano in modo leggermente diverso ma come con le raccolte sono disponibili anche tutte le funzionalità native se si riceve il cursore da una
rawCollection -
Ricontrolla i tipi di dati che utilizzi nelle tue raccolte. Ad esempio, attenersi agli stessi tipi di data (come ISODate) in modo che non si verifichino errori non intenzionali dopo un aggiornamento. C'è anche una controparte Meteor di
mongoosedenominatosimpl-schema(pacchetto npm ) che è un buon modo per mantenere la struttura delle tue raccolte.
Riassumendo, se consideri la maggior parte della guida di Meteor e dei documenti API, dovresti essere sulla buona strada poiché l'integrazione delle raccolte aggiornate esternamente di solito funziona molto bene e si tratta principalmente di comprendere il sistema pub/sub per farlo funzionare.
Modifica:
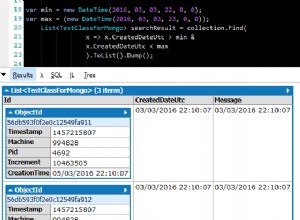
Sì, ma è necessario essere a conoscenza di una query diversa. Se il documento (creato esternamente) ha il seguente valore:
{ "_id" : ObjectId("4ecc05e55dd98a436ddcc47c") }
Quindi devi cambiare la tua query (Meteor) da
collection.findOne("4ecc05e55dd98a436ddcc47c") // returns undefined
a
collection.findOne({ "_id" : new Mongo.ObjectID("4ecc05e55dd98a436ddcc47c") }) // returns { _id: ObjectID { _str: '4ecc05e55dd98a436ddcc47c' } }
Lo stesso modello funziona per la creazione di documenti. Invece di
collection.insert({ foo:'bar' })
passi un ObjectID appena creato:
collection.insert({ foo:'bar', _id: new Mongo.ObjectID() })
Se crei documenti in Meteor con il metodo sopra, non dovresti preoccuparti di _id essere una stringa.
Inoltre i documenti sono come dovrebbero essere (vedi il data format bridge ). Tuttavia, se c'è un'eccezione che non è stata menzionata qui, sentiti libero di commentare poiché potrebbe essere importante anche per altri utenti.