Introduzione:questo esempio mostra un metodo precedente dell'utilizzo di IRI RowGen per generare e popolare prototipi di raccolte grandi o complessi per il test o la capacità del sistema utilizzando file flat. Come leggerai, RowGen creerebbe i dati di test necessari e creerebbe un file CSV che verrebbe caricato in MongoDB utilizzando Mongo Import Utility.
Aggiornamento 2019:ora anche IRI offre JSON e supporto diretto del driver per spostare i dati tra raccolte MongoDB e prodotti software IRI compatibili con SortCL come RowGen o FieldShield. Ciò significa che puoi utilizzare RowGen per generare file JSON di test da importare in MongoDB (non diversamente dal metodo mostrato di seguito in questo articolo), oppure utilizzare FieldShield per mascherare i dati nelle tabelle Mongo in target di test.
Tieni presente che sia FieldShield che RowGen sono inclusi nella piattaforma di gestione dei dati di IRI Voracity, che offre quattro modi per creare dati di test.
Sebbene MongoDB sia un ottimo database NoSQL multipiattaforma e orientato ai documenti, non ha un modo conveniente per generare e popolare prototipi di raccolta di grandi dimensioni o complessi che possono essere utilizzati per testare query o pianificare la capacità. Questo articolo spiega come creare dati di test che MongoDB può utilizzare tramite IRI RowGen, specificando i parametri per un file CSV sintetico ma realistico che MongoDB può importare per test funzionali e delle prestazioni.
Devi prima considerare la struttura e il contenuto dei dati di test per le tue esigenze di raccolta (tabella MongoDB). Consulta questo articolo per le tipiche considerazioni sulla pianificazione.
Nell'esempio, sappiamo che la nostra raccolta sarà composta da clienti che hanno tutti Nomi utente , Nomi e Cognomi , Indirizzi email e Numeri di carta di credito .
Per creare i nostri dati di test, dobbiamo prima generare alcuni file di set. Un file set è un elenco di uno o più valori delimitati da tabulazioni che potrebbero già esistere o che devono essere generati manualmente o automaticamente dalle colonne del database tramite la procedura guidata "Genera nuovo file set" in IRI RowGen.
Generazione di nomi
1) Creare uno script di lavoro con valore di dati composto (nome e cognome combinati) denominato "CreateNamesSet.rcl" che RowGen può eseguire per produrre un file di set; chiama l'output "User.set" perché questi nomi verranno utilizzati anche come base per i nostri nomi utente.
2) Crea tre campi da generare in Names.set:cognome, separatore di tabulazione e nome. Assegna un nome al primo campo "Cognome" e scegli il metodo che seleziona i valori da un file di set fornito da IRI chiamato "names_last.set". Aggiungi il valore letterale "\t" per aggiungere un separatore di tabulazione, quindi ripeti il processo utilizzato per i valori Cognome e Nome utilizzando names_first.set.
3) Eseguire CreateNamesSet.rcl con RowGen, dalla riga di comando o dalla GUI di IRI Workbench, per produrre il file User.set delimitato da tabulazioni di nome e cognome, che verrà utilizzato in sia nella generazione dei nomi utente che nella build del file di test finale che popola la nostra raccolta di prototipi.

Generazione di nomi utente
Per i nomi utente, creeremo un file di set che utilizza il file Users.set generato sopra. I nomi utente per questo esempio combineranno cognome, iniziale e un numero generato casualmente compreso tra 100 e 999.
1) Crea un nuovo script di lavoro RowGen con il Compound Data Wizard, chiamalo "CreateUsernamesSet.rcl" e denomina il file del set di output "Usernames.set".
2) Crea valori di nome utente composti con tre componenti denominati Parte 1, Parte 2 e Parte 3.
3) Per la parte 1, scegli il metodo che selezionerà i valori da (sfoglia in) il file User.set generato in precedenza e specifica "TUTTO" per il tipo di selezione per mantenere l'associazione tra gli utenti, nomi utente e indirizzi e-mail. Imposta la dimensione su 5.
4) Per la parte 2, ripetere la procedura utilizzata per la parte 1, ad eccezione del tipo di selezione, selezionare "Riga" e impostare l'indice della colonna su 2. impostare la dimensione su 1. Ciò garantisce che tutti i cognomi verranno utilizzati nella generazione e che la prima lettera del nome nella stessa riga sia aggiunta al nome utente.
5) Per la parte 3, specifica la generazione di un valore numerico compreso tra 100 e 999 per suffisso un numero intero casuale con ciascun nome utente.
All'esecuzione di CreateUsernamesSet.rcl, vediamo che ogni nome utente contiene le prime cinque lettere del cognome, poi la prima iniziale, quindi un numero casuale di 3 cifre:
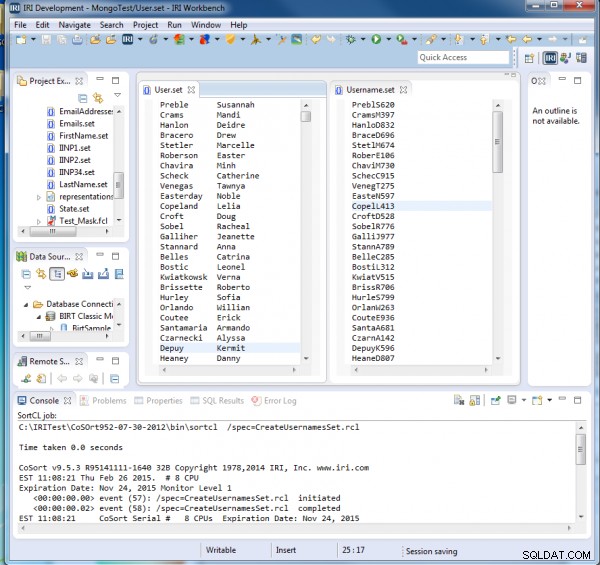
Generazione di email
Successivamente creeremo un file di set di posta elettronica che aggiunge i valori del nome utente con nomi di dominio selezionati a caso. Poiché alcuni servizi di posta elettronica sono più popolari di altri, creeremo anche un sistema di ponderazione per riflettere una maggiore frequenza dei domini yahoo e gmail.
1) Esegui la procedura guidata "Nuovi dati di test personalizzati" di RowGen per creare un lavoro chiamato "CreateEmailsSet" che produca un file di set chiamato "Emails.set".
2) Produci la parte del nome utente dell'e-mail. Nella finestra di dialogo Test definizione dati, fare clic su Nuovo campo e rinominare il primo campo Nomi utente. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come nomi utente.set. Imposta la dimensione su 9 e fai clic su OK.
3) Produci la parte del dominio dell'email (che include il simbolo @). Nella finestra di dialogo Campi layout, fare clic su Nuovo campo e rinominarlo in "indirizzo" e fare doppio clic su di esso. Nella finestra di dialogo Campo di generazione, specificare un " ", con una posizione di 10 e una dimensione di 20. Nella sezione Generazione dati/Distribuzione dati di seguito, fare clic su "Definisci..." per denominare una nuova distribuzione di dati di elementi "Email ponderate".
4) Nella nuova procedura guidata di distribuzione, scegli "Distribuzione ponderata degli articoli" e inserisci questi elementi rispettivamente nelle caselle di testo del rapporto e letterale, quindi aggiungi ciascuno all'elenco.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
Dopo aver inserito questi valori, fai clic su Avanti nella procedura guidata originale per passare alla finestra di dialogo Destinazioni dati. Utilizzare "Aggiungi destinazione dati ..." per specificare il file di output "Email.set". Questo verrà utilizzato anche al momento della creazione della raccolta.
Le email per le quali abbiamo impostato il peso più alto (gmail e yahoo) vengono visualizzate più frequentemente, mentre altre vengono visualizzate periodicamente.

Generazione di numeri di carta di credito
Infine, creeremo numeri di carta validi dal punto di vista computazionale nel formato XXXX-XXXX-XXXX-XXXX. Le prime quattro cifre riflettono i numeri di identificazione del problema (IIN) effettivi di varie società di carte di credito e l'ultima cifra verifica l'autenticità delle carte.
Per fare ciò, crea ed esegui un nuovo lavoro (vuoto). Chiamalo "CreateCCNSet.rcl" (o .scl) e compilalo con lo script seguente per creare "CCN.set". Il valore /INCOLLECT negli script RowGen determina il numero di righe generate.

La funzione di generazione CCN specifica di RowGen, ccn_gen("ANY, "-") viene chiamata per popolare questo campo. Nota che esistono funzioni simili per i numeri di previdenza sociale statunitensi e coreani e gli ID nazionali di Italia e Paesi Bassi.
Creazione del file di test finale
Con tutti i file impostati creati, è ora di utilizzarli nel file CSV di prova che creeremo ed esporteremo in una raccolta MongoDB.
1) Esegui la procedura guidata "Nuovi dati di test personalizzati" di RowGen per creare un lavoro chiamato "CreateMongoUserData.rcl" che genererà il file Customers.csv, il file che poi esporteremo in MongoDB.
2) Fai clic su "Campi layout ..." per accedere alla finestra di dialogo Campi layout. Fare clic su Nuovo campo e rinominare il primo campo in Nomi utente. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come Usernames.set; quindi seleziona TUTTO per il tipo di selezione.
3) Fai clic su Nuovo campo e rinomina il secondo campo in Cognomi. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come Users.set; quindi seleziona TUTTO per il tipo di selezione.
4) Fai clic su Nuovo campo e rinomina il terzo campo in FirstNames. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come Users.set; quindi seleziona RIGHE per il tipo di selezione e imposta l'indice della colonna su 2.
5) Fai clic su Nuovo campo e rinomina il quarto campo in Email. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come Emails.set; quindi seleziona TUTTO per il tipo di selezione.
6) Fai clic su Nuovo campo e rinomina il quinto campo in CreditCardNumbers. Fare doppio clic su di esso per avviare la finestra di dialogo Campo di generazione e "Definisci..." il suo file Imposta come CCN.set; quindi seleziona TUTTO per il tipo di selezione.
7) Dopo aver inserito questi valori, fai clic su Avanti nella procedura guidata originale per passare alla finestra di dialogo Destinazioni dati. Utilizzare "Aggiungi destinazione dati ..." per specificare il file di output Customers.csv; quindi esegui lo script in Workbench o sulla riga di comando per generare quel file:
rowgen /spec=CreateMongoUserData.rcl

Si noti che RowGen, oltre a produrre questo file CSV in fase di esecuzione, avrebbe potuto anche produrre più, altri file, database, report formattati, named pipe, procedure e persino visualizzazione BIRT in tempo reale , con i campi dei dati di test generati, tutti contemporaneamente.
Importazione in MongoDB
Per importare il file CSV nel database Mongo, chiama l'utilità mongoimport ed esegui il comando seguente:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Ecco i record nella raccolta di test (mostrata con MongoVUE), che MongoDB indicizzerà automaticamente con i valori ID generati per ogni voce:
MongoDB assegna un valore ID univoco a ciascuna voce della raccolta.
Puoi anche caricare i dati di prova direttamente nel database Mongo utilizzando il driver ODBC DataDirect di Progress Software per MongoDB. Prima di eseguire il lavoro RowGen in Workbench, avevo una raccolta vuota chiamata CUSTOMERS_CNN in MYDB per ricevere i dati.
Ho eseguito prima il lavoro utilizzando stdout, per visualizzare in anteprima i dati di test nella finestra della console:

Dopo aver eseguito lo script in Workbench, ora posso vedere i miei dati utilizzando Data Source Explorer e il driver DataDirect JDBC.

Per ulteriori informazioni sulle opzioni di generazione disponibili, consulta Target file di prova sezione su: https://www.iri.com/products/rowgen/technical-details.



