I sistemi di database sono componenti cruciali nel ciclo di qualsiasi applicazione in esecuzione di successo. Ogni organizzazione che li coinvolge ha quindi il mandato di garantire prestazioni fluide di questi DBM attraverso il monitoraggio coerente e la gestione di piccoli inconvenienti prima che si trasformino in enormi complicazioni che possono comportare tempi di inattività dell'applicazione o prestazioni lente.
Potresti chiedere come puoi sapere se il database avrà davvero un problema mentre funziona normalmente? Bene, questo è ciò di cui discuteremo in questo articolo e lo chiamiamo benchmarking. Il benchmarking consiste fondamentalmente nell'esecuzione di una serie di query con alcuni dati di test insieme a una fornitura di risorse per determinare se questi parametri soddisfano il livello di prestazioni previsto.
MongoDB non ha una metodologia di benchmarking standard, quindi è necessario risolvere le query di test sul proprio hardware. Per quanto tu possa anche ottenere cifre impressionanti dal processo di benchmark, devi essere cauto poiché questo potrebbe essere un caso diverso quando esegui il tuo database con query reali.
L'idea alla base del benchmarking è di avere un'idea generale su come le diverse opzioni di configurazione influiscono sulle prestazioni, su come modificare alcune di queste configurazioni per ottenere le massime prestazioni e stimare il costo del miglioramento di questa implementazione. Inoltre, le applicazioni crescono con il tempo in termini di utenti e probabilmente la quantità di dati che deve essere servita, quindi, necessita di un po' di pianificazione della capacità prima di questo momento. Dopo aver realizzato una tendenza all'aumento dei dati, è necessario eseguire alcuni benchmarking su come soddisfare i requisiti di questa vasta crescita di dati.
Considerazioni sull'analisi comparativa di MongoDB
- Seleziona carichi di lavoro che rappresentano una tipica rappresentazione delle applicazioni moderne di oggi. Le moderne applicazioni stanno diventando ogni giorno più complesse e questo viene trasmesso alle strutture dati. Vale a dire, anche la presentazione dei dati è cambiata nel tempo, ad esempio la memorizzazione di campi semplici in oggetti e array. Non è del tutto facile lavorare con questi dati con configurazioni di database predefinite o piuttosto scadenti in quanto potrebbe degenerare in problemi come scarsa latenza e scarse operazioni di throughput che coinvolgono dati complessi. Quando esegui un benchmark dovresti quindi utilizzare dati che rappresentano una chiara presentazione della tua applicazione.
- Ricontrolla le scritture. Assicurati sempre che tutte le scritture dei dati siano state eseguite in un modo che non consentisse la perdita di dati. Questo serve a migliorare l'integrità dei dati assicurando che i dati siano coerenti e che siano più applicabili soprattutto nell'ambiente di produzione.
- Utilizzare volumi di dati che sono una rappresentazione di set di dati "big data" che sicuramente supereranno la capacità della RAM per un singolo nodo. Quando il carico di lavoro di test è grande, ti aiuterà a prevedere le aspettative future sulle prestazioni del tuo database, quindi inizia abbastanza presto una pianificazione della capacità.
Metodologia
Il nostro test di benchmark riguarderà alcuni dati di posizione di grandi dimensioni che possono essere scaricati da qui e utilizzeremo il software Robo3t per manipolare i nostri dati e raccogliere le informazioni di cui abbiamo bisogno. Il file ha più di 500 documenti che sono abbastanza per il nostro test. Stiamo utilizzando MongoDB versione 4.0 su un server dedicato Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore a 3,4 GHz con 32 GB di RAM, disco rotante Western Digital WD Caviar RE4 da 1 TB e SSD Smart XceedIOPS da 256 GB. Abbiamo inserito i primi 500 documenti.
Abbiamo eseguito i comandi di inserimento di seguito
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Scrivi preoccupazione
Il problema di scrittura descrive il livello di riconoscimento richiesto da MongoDB per le operazioni di scrittura in questo caso su un MongoDB autonomo. Per un'operazione di throughput elevato, se questo valore è impostato su basso, le chiamate di scrittura saranno così veloci da ridurre la latenza della richiesta. D'altra parte, se il valore è impostato su alto, le chiamate di scrittura sono lente e di conseguenza aumentano la latenza della query. Una semplice spiegazione per questo è che quando il valore è basso, non sei preoccupato della possibilità di perdere alcune scritture in caso di crash di mongod, errore di rete o guasto anonimo del sistema. Una limitazione in questo caso sarà che non sarai sicuro che queste scritture abbiano avuto successo. D'altra parte, se il problema di scrittura è elevato, viene visualizzata una richiesta di gestione degli errori e quindi le scritture verranno confermate. Una conferma è semplicemente una ricevuta che il server ha accettato la scrittura per elaborare.
 Quando il problema di scrittura è alto
Quando il problema di scrittura è alto  Quando il problema di scrittura è basso
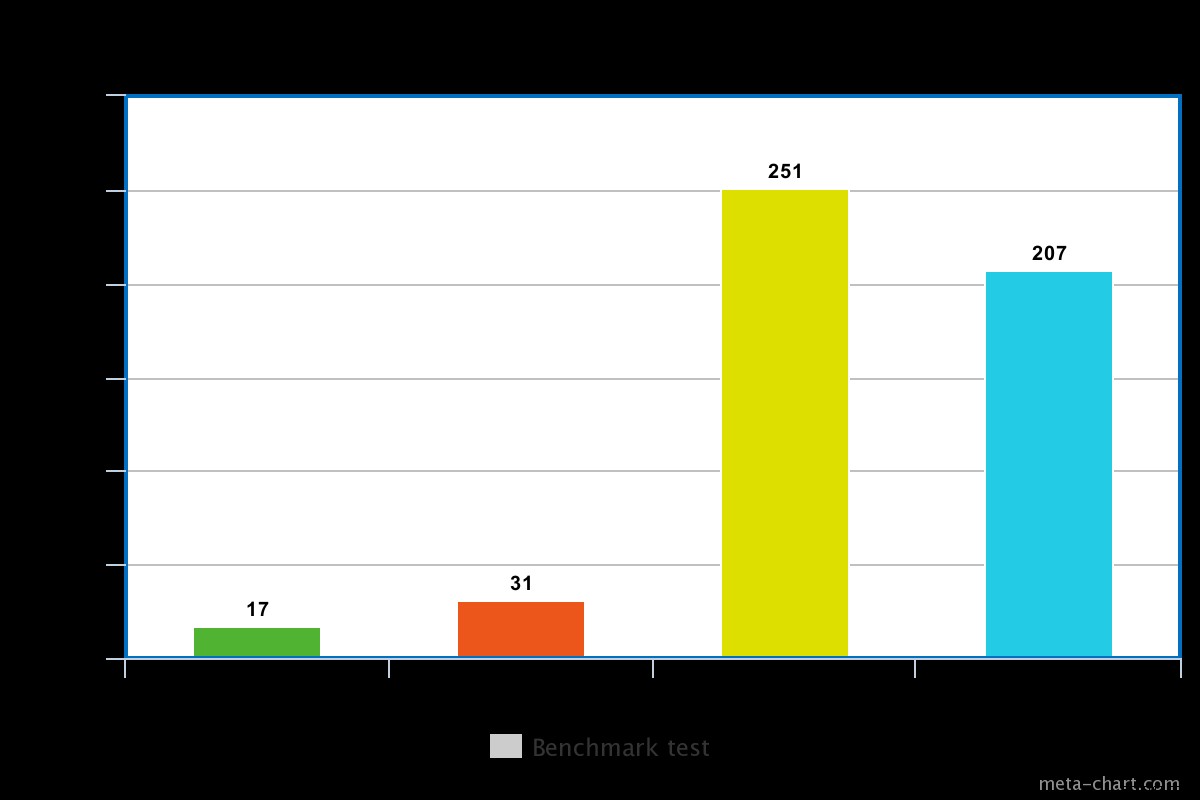
Quando il problema di scrittura è basso Nel nostro test, il problema di scrittura impostato su basso ha comportato l'esecuzione della query in un minimo di 0,013 ms e un massimo di 0,017 ms. In questo caso, il riconoscimento di base della scrittura è disabilitato ma è comunque possibile ottenere informazioni sulle eccezioni socket e su qualsiasi errore di rete che potrebbe essere stato attivato.
Quando il problema di scrittura è alto, ci vuole quasi il doppio del tempo per tornare con il tempo di esecuzione di 0,027 ms min e 0,031 ms max. Il riconoscimento in questo caso è garantito ma non al 100% ha raggiunto il diario del disco. In questo caso, le possibilità di una perdita di scrittura sono quindi del 50% a causa della finestra di 100 ms in cui il journal potrebbe non essere scaricato su disco.
Diario
Questa è una tecnica per garantire l'assenza di perdita di dati fornendo durabilità in caso di guasto. Ciò si ottiene tramite una registrazione write-ahead sui file journal su disco. È più efficiente quando il problema di scrittura è alto.
Per un disco rotante, il tempo di esecuzione con il journaling abilitato è un po' alto, ad esempio nel nostro test era di circa 0,251 ms per la stessa operazione sopra.

Il tempo di esecuzione per un SSD, tuttavia, è leggermente inferiore per lo stesso comando. Nel nostro test, era di circa 0,207 ms, ma a seconda della natura dei dati a volte questo potrebbe essere 3 volte più veloce di un disco rotante.

Quando l'inserimento nel journal è abilitato, conferma che le scritture sono state eseguite nel journal e quindi garantisce la durabilità dei dati. Di conseguenza, l'operazione di scrittura sopravviverà a un arresto mongod e garantisce che l'operazione di scrittura sia duratura.
Per un'operazione di throughput elevato, è possibile dimezzare i tempi di query impostando w=0. Altrimenti, se hai bisogno di essere sicuro che i dati siano stati registrati o piuttosto lo saranno in caso di ripristino della vita dopo un guasto, devi impostare w=1.
 Severalnines Diventa un DBA MongoDB - Portare MongoDB in produzioneScopri cosa devi sapere per distribuire, monitorare, gestire e scala MongoDBScarica gratuitamente
Severalnines Diventa un DBA MongoDB - Portare MongoDB in produzioneScopri cosa devi sapere per distribuire, monitorare, gestire e scala MongoDBScarica gratuitamente Replica
Il riconoscimento di un problema di scrittura può essere abilitato per più di un nodo che è il primario e alcuni secondari all'interno di un set di repliche. Questo sarà caratterizzato da quale intero viene valutato nel parametro di scrittura. Ad esempio, se w =3, Mongod deve assicurarsi che la query riceva un riconoscimento dal nodo principale e 2 slave. Se provi a impostare un valore maggiore di uno e il nodo non è ancora replicato, verrà generato un errore che indica che l'host deve essere replicato.
La replica viene fornita con una battuta d'arresto della latenza tale da aumentare il tempo di esecuzione. Per la query semplice sopra se w=3, il tempo di esecuzione medio aumenta a 270 ms. Un fattore trainante per questo è l'intervallo nel tempo di risposta tra i nodi interessati dalla latenza della rete, il sovraccarico di comunicazione tra i 3 nodi e la congestione. Inoltre, tutti e tre i nodi aspettano l'un l'altro per finire prima di restituire il risultato. In una distribuzione di produzione, quindi, non sarà necessario coinvolgere così tanti nodi se si desidera migliorare le prestazioni. MongoDB è responsabile della selezione dei nodi da riconoscere a meno che non sia presente una specifica nel file di configurazione che utilizza i tag.
Disco rotante e disco a stato solido
Come accennato in precedenza, il disco SSD è abbastanza veloce rispetto alla rotazione del disco a seconda dei dati coinvolti. A volte potrebbe essere 3 volte più veloce, quindi vale la pena pagare se necessario. Tuttavia, sarà più costoso utilizzare un SSD soprattutto quando si ha a che fare con dati di grandi dimensioni. MongoDB ha il merito di supportare l'archiviazione di database in directory che possono essere montate, quindi la possibilità di utilizzare un SSD. L'utilizzo di un SSD e l'abilitazione del journaling è un'ottima ottimizzazione.
Conclusione
L'esperimento era certo che il problema di scrittura disabilitato comporta una riduzione del tempo di esecuzione di una query a scapito delle possibilità di perdita di dati. D'altra parte, quando il problema di scrittura è abilitato, il tempo di esecuzione è quasi 2 volte quando è disabilitato, ma c'è la certezza che i dati non andranno persi. Inoltre, siamo in grado di giustificare che l'SSD è più veloce di un disco rotante. Tuttavia, per garantire la durabilità dei dati in caso di guasto del sistema, è consigliabile abilitare il problema di scrittura. Quando si abilita il problema di scrittura per un set di repliche, non impostare il numero troppo grande in modo che possa comportare un peggioramento delle prestazioni dall'estremità dell'applicazione.



