L'efficienza di un database non si basa solo sulla messa a punto dei parametri più critici, ma va anche oltre l'appropriata presentazione dei dati nelle relative raccolte. Di recente, ho lavorato a un progetto che ha sviluppato un'applicazione di chat sociale e, dopo alcuni giorni di test, abbiamo notato un certo ritardo durante il recupero dei dati dal database. Non avevamo così tanti utenti, quindi abbiamo escluso l'ottimizzazione dei parametri del database e ci siamo concentrati sulle nostre query per arrivare alla causa principale.
Con nostra sorpresa, ci siamo resi conto che la nostra strutturazione dei dati non era del tutto appropriata in quanto avevamo più di 1 richiesta di lettura per recuperare alcune informazioni specifiche.
Il modello concettuale di come vengono messe in atto le sezioni dell'applicazione dipende in larga misura dalla struttura delle raccolte di database. Ad esempio, se accedi a un'app social, i dati vengono inseriti nelle diverse sezioni in base al design dell'applicazione come illustrato dalla presentazione del database.
In poche parole, per un database ben progettato, la struttura dello schema e le relazioni di raccolta sono elementi chiave per il suo miglioramento della velocità e dell'integrità, come vedremo nelle sezioni seguenti.
Discuteremo i fattori da considerare durante la modellazione dei dati.
Cos'è la modellazione dei dati
La modellazione dei dati è generalmente l'analisi degli elementi di dati in un database e della loro relazione con altri oggetti all'interno di quel database.
In MongoDB, ad esempio, possiamo avere una raccolta di utenti e una raccolta di profili. La raccolta utenti elenca i nomi degli utenti per una determinata applicazione, mentre la raccolta profili acquisisce le impostazioni del profilo per ciascun utente.
Nella modellazione dei dati, dobbiamo progettare una relazione per connettere ciascun utente al profilo corrispondente. In poche parole, la modellazione dei dati è il passaggio fondamentale nella progettazione di database oltre a costituire la base dell'architettura per la programmazione orientata agli oggetti. Dà anche un indizio su come apparirà l'applicazione fisica durante l'avanzamento dello sviluppo. Un'architettura di integrazione applicazione-database può essere illustrata come di seguito.
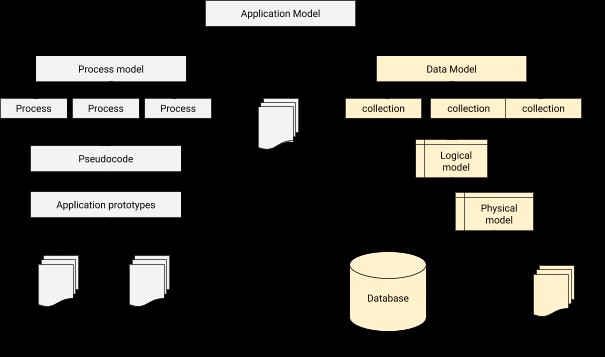
Il processo di modellazione dei dati in MongoDB
La modellazione dei dati viene fornita con prestazioni del database migliorate, ma a scapito di alcune considerazioni che includono:
- Modelli di recupero dati
- Esigenze di bilanciamento dell'applicazione quali:query, aggiornamenti ed elaborazione dati
- Caratteristiche prestazionali del motore di database scelto
- La struttura intrinseca dei dati stessi
Struttura del documento MongoDB
I documenti in MongoDB svolgono un ruolo importante nel processo decisionale su quale tecnica applicare per un determinato insieme di dati. Esistono generalmente due relazioni tra i dati, che sono:
- Dati incorporati
- Dati di riferimento
Dati incorporati
In questo caso, i dati correlati vengono archiviati all'interno di un singolo documento come valore di campo o come matrice all'interno del documento stesso. Il vantaggio principale di questo approccio è che i dati sono denormalizzati e quindi offre l'opportunità di manipolare i dati correlati in un'unica operazione di database. Di conseguenza, ciò migliora la velocità con cui vengono eseguite le operazioni CRUD, quindi sono necessarie meno query. Consideriamo un esempio di documento di seguito:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}In questo insieme di dati, abbiamo uno studente con il suo nome e alcune altre informazioni aggiuntive. Il campo Impostazioni è stato incorporato con un oggetto e inoltre anche il campo placeLocation è incorporato con un oggetto con le configurazioni di latitudine e longitudine. Tutti i dati per questo studente sono stati contenuti in un unico documento. Se dobbiamo recuperare tutte le informazioni per questo studente, eseguiamo semplicemente:
db.students.findOne({StudentName : "George Beckonn"})Punti di forza dell'incorporamento
- Maggiore velocità di accesso ai dati:per una migliore velocità di accesso ai dati, l'incorporamento è l'opzione migliore poiché una singola operazione di query può manipolare i dati all'interno del documento specificato con una sola ricerca nel database.
- Ridotta incoerenza dei dati:durante il funzionamento, se qualcosa va storto (ad esempio una disconnessione dalla rete o un'interruzione di corrente) solo un numero limitato di documenti potrebbe essere interessato poiché i criteri spesso selezionano un unico documento.
- Operazioni CRUD ridotte. Vale a dire, le operazioni di lettura supereranno effettivamente il numero delle scritture. Inoltre, è possibile aggiornare i dati correlati in un'unica operazione di scrittura atomica. Vale a dire per i dati di cui sopra, possiamo aggiornare il numero di telefono e anche aumentare la distanza con questa singola operazione:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Debolezze dell'incorporamento
- Formato del documento limitato. Tutti i documenti in MongoDB sono vincolati alla dimensione BSON di 16 megabyte. Pertanto, le dimensioni complessive del documento insieme ai dati incorporati non dovrebbero superare questo limite. In caso contrario, per alcuni motori di archiviazione come MMAPv1, i dati potrebbero diventare troppo grandi e causare la frammentazione dei dati a causa di prestazioni di scrittura ridotte.
- Duplicazione dei dati:più copie degli stessi dati rendono più difficile interrogare i dati replicati e potrebbe essere necessario più tempo per filtrare i documenti incorporati, superando quindi il vantaggio principale dell'incorporamento.
Notazione punto
La notazione del punto è la caratteristica di identificazione dei dati incorporati nella parte di programmazione. Viene utilizzato per accedere agli elementi di un campo incorporato o di un array. Nei dati di esempio sopra, possiamo restituire le informazioni dello studente la cui posizione è "Ambasciata" con questa query utilizzando la notazione del punto.
db.users.find({'Settings.location': 'Embassy'})Dati di riferimento
La relazione dei dati in questo caso è che i dati correlati sono archiviati all'interno di documenti diversi, ma viene emesso un collegamento di riferimento a questi documenti correlati. Per i dati di esempio sopra possiamo ricostruirli in modo tale che:
Documento utente
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Documento delle impostazioni
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Esistono 2 documenti diversi, ma sono collegati dallo stesso valore per i campi _id e id. Il modello dati è quindi normalizzato. Tuttavia, per poter accedere alle informazioni da un documento correlato, dobbiamo emettere ulteriori query e di conseguenza ciò si traduce in un aumento dei tempi di esecuzione. Ad esempio, se vogliamo aggiornare il ParentPhone e le relative impostazioni di distanza avremo almeno 3 domande cioè
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Punti di forza del referenziamento
- Coerenza dei dati. Per ogni documento viene mantenuta una forma canonica, quindi le possibilità di incoerenza dei dati sono piuttosto basse.
- Integrità dei dati migliorata. Grazie alla normalizzazione, è facile aggiornare i dati indipendentemente dalla durata della durata dell'operazione e quindi garantire dati corretti per ogni documento senza creare confusione.
- Utilizzo della cache migliorato. I documenti canonici a cui si accede di frequente vengono archiviati nella cache anziché per i documenti incorporati a cui si accede più volte.
- Utilizzo hardware efficiente. Contrariamente all'incorporamento, che può comportare un'eccessiva crescita del documento, il riferimento non promuove la crescita del documento, quindi riduce l'utilizzo del disco e della RAM.
- Maggiore flessibilità soprattutto con un ampio set di documenti secondari.
- Scrive più velocemente.
Debolezze della referenziazione
- Ricerche multiple:poiché dobbiamo cercare in un certo numero di documenti che corrispondono ai criteri, il tempo di lettura durante il recupero dal disco aumenta. Inoltre, ciò potrebbe causare errori nella cache.
- Molte query vengono inviate per eseguire alcune operazioni, quindi i modelli di dati normalizzati richiedono più round trip al server per completare un'operazione specifica.
Normalizzazione dei dati
La normalizzazione dei dati si riferisce alla ristrutturazione di un database secondo alcune forme normali al fine di migliorare l'integrità dei dati e ridurre gli eventi di ridondanza dei dati.
La modellazione dei dati ruota attorno a 2 principali tecniche di normalizzazione, ovvero:
-
Modelli di dati normalizzati
Come applicato nei dati di riferimento, la normalizzazione divide i dati in più raccolte con riferimenti tra le nuove raccolte. Un unico aggiornamento del documento sarà rilasciato all'altra collezione e applicato di conseguenza al documento di corrispondenza. Ciò fornisce una rappresentazione efficiente dell'aggiornamento dei dati ed è comunemente usato per i dati che cambiano abbastanza spesso.
-
Modelli di dati denormalizzati
I dati contengono documenti incorporati, rendendo così le operazioni di lettura abbastanza efficienti. Tuttavia, è associato a un maggiore utilizzo dello spazio su disco e anche a difficoltà nel mantenere la sincronizzazione. Il concetto di denormalizzazione può essere ben applicato ai documenti secondari i cui dati non cambiano abbastanza spesso.
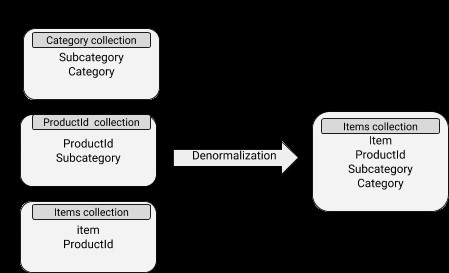
Schema MongoDB
Uno schema è fondamentalmente uno scheletro delineato di campi e tipo di dati che ogni campo dovrebbe contenere per un determinato insieme di dati. Considerando il punto di vista SQL, tutte le righe sono progettate per avere le stesse colonne e ogni colonna dovrebbe contenere il tipo di dati definito. Tuttavia, in MongoDB, abbiamo uno Schema flessibile per impostazione predefinita che non mantiene la stessa conformità per tutti i documenti.
Schema flessibile
Uno schema flessibile in MongoDB definisce che i documenti non devono necessariamente avere gli stessi campi o tipo di dati, poiché un campo può differire tra i documenti all'interno di una raccolta. Il vantaggio principale di questo concetto è che è possibile aggiungere nuovi campi, rimuovere quelli esistenti o modificare i valori dei campi in un nuovo tipo e quindi aggiornare il documento in una nuova struttura.
Ad esempio possiamo avere questi 2 documenti nella stessa collezione:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}Nel primo documento abbiamo un campo età mentre nel secondo documento non c'è campo età. Inoltre, il tipo di dati per il campo ParentPhone è un numero mentre nel secondo documento è stato impostato su false, che è un tipo booleano.
La flessibilità dello schema facilita la mappatura dei documenti su un oggetto e ogni documento può corrispondere ai campi di dati dell'entità rappresentata.
Schema rigido
Per quanto abbiamo detto che questi documenti possono differire l'uno dall'altro, a volte potresti decidere di creare uno schema rigido. Uno schema rigido definirà che tutti i documenti in una raccolta condivideranno la stessa struttura e questo ti darà una migliore possibilità di impostare alcune regole di convalida dei documenti come un modo per migliorare l'integrità dei dati durante le operazioni di inserimento e aggiornamento.
Tipi di dati dello schema
Quando si utilizzano alcuni driver del server per MongoDB come mongoose, sono disponibili alcuni tipi di dati forniti che consentono di eseguire la convalida dei dati. I tipi di dati di base sono:
- Stringa
- Numero
- Booleano
- Data
- Buffer
- ID oggetto
- Matrice
- Misto
- Decimale128
- Mappa
Dai un'occhiata allo schema di esempio qui sotto
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Esempio di caso d'uso
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Convalida dello schema
Per quanto sia possibile eseguire la convalida dei dati dal lato dell'applicazione, è sempre buona norma eseguire la convalida anche dal lato server. Otteniamo questo utilizzando le regole di convalida dello schema.
Queste regole vengono applicate durante le operazioni di inserimento e aggiornamento. Sono dichiarati normalmente su base raccolta durante il processo di creazione. Tuttavia, puoi anche aggiungere le regole di convalida del documento a una raccolta esistente utilizzando il comando collMod con le opzioni di convalida, ma queste regole non vengono applicate ai documenti esistenti fino a quando non viene applicato un aggiornamento.
Allo stesso modo, quando crei una nuova collezione usando il comando db.createCollection() puoi emettere l'opzione validator. Dai un'occhiata a questo esempio quando crei una raccolta per gli studenti. Dalla versione 3.6, MongoDB supporta la convalida dello schema JSON, quindi tutto ciò che serve è utilizzare l'operatore $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})In questa progettazione dello schema, se proviamo a inserire un nuovo documento come:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})La funzione di callback restituirà l'errore di seguito, a causa di alcune regole di convalida violate, ad esempio il valore dell'anno fornito non rientra nei limiti specificati.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Inoltre, puoi aggiungere espressioni di query alla tua opzione di convalida utilizzando gli operatori di query tranne $where, $text, near e $nearSphere, ovvero:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Livelli di convalida dello schema
Come accennato in precedenza, la convalida viene rilasciata normalmente alle operazioni di scrittura.
Tuttavia, la convalida può essere applicata anche a documenti già esistenti.
Esistono 3 livelli di convalida:
- Rigoroso:questo è il livello di convalida MongoDB predefinito e applica le regole di convalida a tutti gli inserimenti e gli aggiornamenti.
- Moderato:le regole di convalida vengono applicate durante inserimenti, aggiornamenti e documenti già esistenti che soddisfano solo i criteri di convalida.
- Off:questo livello imposta le regole di convalida per un determinato schema su null, quindi non verrà eseguita alcuna convalida sui documenti.
Esempio:
Inseriamo i dati di seguito in una raccolta client.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Se applichiamo il livello di convalida moderato utilizzando:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Le regole di convalida verranno applicate solo al documento con _id pari a 1 poiché corrisponderà a tutti i criteri.
Per il secondo documento, poiché le regole di convalida non sono soddisfatte con i criteri emessi, il documento non verrà convalidato.
Azioni di convalida dello schema
Dopo aver eseguito la convalida sui documenti, potrebbero essercene alcuni che potrebbero violare le regole di convalida. È sempre necessario fornire un'azione quando ciò accade.
MongoDB fornisce due azioni che possono essere emesse per i documenti che non rispettano le regole di convalida:
- Errore:questa è l'azione MongoDB predefinita, che rifiuta qualsiasi inserimento o aggiornamento nel caso in cui violi i criteri di convalida.
-
Avvertenza:questa azione registrerà la violazione nel registro di MongoDB, ma consente il completamento dell'operazione di inserimento o aggiornamento. Ad esempio:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Se proviamo a inserire un documento come questo:
db.students.insert( { name: "Amanda", status: "Updated" } );Il gpa manca indipendentemente dal fatto che sia un campo obbligatorio nella progettazione dello schema, ma poiché l'azione di convalida è stata impostata su avviso, il documento verrà salvato e verrà registrato un messaggio di errore nel log di MongoDB.



