Una delle maggiori preoccupazioni nella gestione e nella gestione dei database è la complessità dei dati e delle dimensioni. Spesso le organizzazioni si preoccupano di come affrontare la crescita e gestire l'impatto sulla crescita perché la gestione del database fallisce. La complessità deriva da preoccupazioni che non sono state affrontate inizialmente e non sono state viste, o potrebbero essere trascurate perché la tecnologia attualmente utilizzata sarà in grado di gestire da sola. La gestione di un database complesso e di grandi dimensioni deve essere pianificata di conseguenza, soprattutto quando si prevede che il tipo di dati che stai gestendo o gestendo cresca in modo massiccio sia in anticipo che in modo imprevedibile. L'obiettivo principale della pianificazione è evitare disastri indesiderati, o dovremmo dire evitare di andare in fumo! In questo blog tratteremo come gestire in modo efficiente database di grandi dimensioni.
Le dimensioni dei dati contano
La dimensione del database è importante in quanto ha un impatto sulle prestazioni e sulla sua metodologia di gestione. Il modo in cui i dati vengono elaborati e archiviati contribuirà alla gestione del database, che si applica sia ai dati in transito che a quelli inattivi. Per molte grandi organizzazioni, i dati sono preziosi e la crescita dei dati potrebbe avere un cambiamento drastico nel processo. Pertanto, è fondamentale disporre di piani preliminari per gestire la crescita dei dati in un database.
Nella mia esperienza di lavoro con i database, ho visto clienti che hanno problemi nell'affrontare le penalità delle prestazioni e nella gestione della crescita estrema dei dati. Sorgono domande se normalizzare le tabelle o denormalizzare le tabelle.
Normalizzazione delle tabelle
La normalizzazione delle tabelle mantiene l'integrità dei dati, riduce la ridondanza e semplifica l'organizzazione dei dati in modo più efficiente per la gestione, l'analisi e l'estrazione. L'utilizzo di tabelle normalizzate produce efficienza, soprattutto quando si analizza il flusso di dati e si recuperano dati tramite istruzioni SQL o si lavora con linguaggi di programmazione come C/C++, Java, Go, Ruby, PHP o interfacce Python con i connettori MySQL.
Anche se i problemi con le tabelle normalizzate comportano una riduzione delle prestazioni e possono rallentare le query a causa di serie di join durante il recupero dei dati. Mentre le tabelle denormalizzate, tutto ciò che devi considerare per l'ottimizzazione si basa sull'indice o sulla chiave primaria per archiviare i dati nel buffer per un recupero più rapido rispetto all'esecuzione di ricerche su più dischi. Le tabelle denormalizzate non richiedono join, ma sacrificano l'integrità dei dati e le dimensioni del database tendono a diventare sempre più grandi.
Quando il tuo database è grande, considera di avere un DDL (Data Definition Language) per la tua tabella del database in MySQL/MariaDB. L'aggiunta di una chiave primaria o univoca per la tabella richiede una ricostruzione della tabella. La modifica di un tipo di dati di una colonna richiede anche una ricostruzione della tabella poiché l'algoritmo applicabile da applicare è solo ALGORITHM=COPY.
Se lo stai facendo nel tuo ambiente di produzione, può essere difficile. Raddoppia la sfida se il tuo tavolo è enorme. Immagina un milione o un miliardo di righe. Non puoi applicare un'istruzione ALTER TABLE direttamente alla tua tabella. Ciò può bloccare tutto il traffico in entrata che dovrà accedere alla tabella attualmente in cui stai applicando il DDL. Tuttavia, questo può essere mitigato utilizzando pt-online-schema-change o il grande gh-ost. Tuttavia, richiede monitoraggio e manutenzione durante il processo di DDL.
Sharding e partizionamento
Con lo sharding e il partizionamento, aiuta a separare o segmentare i dati in base alla loro identità logica. Ad esempio, separando in base a data, ordine alfabetico, paese, stato o chiave primaria in base all'intervallo specificato. Questo aiuta la dimensione del database a essere gestibile. Mantieni le dimensioni del tuo database fino al limite che è gestibile per la tua organizzazione e il tuo team. Facile da scalare se necessario o facile da gestire, soprattutto quando si verifica un disastro.
Quando diciamo gestibile, considera anche le risorse di capacità del tuo server e anche il tuo team di ingegneri. Non puoi lavorare con dati grandi e grandi con pochi ingegneri. Lavorare con big data come 1000 database con un gran numero di set di dati richiede un'enorme richiesta di tempo. Abilità saggia e competenza è un must. Se il costo è un problema, è il momento in cui puoi sfruttare servizi di terze parti che offrono servizi gestiti o consulenza o supporto a pagamento per qualsiasi lavoro di ingegneria da soddisfare.
Set di caratteri e confronto
I set di caratteri e le regole di confronto influiscono sull'archiviazione e sulle prestazioni dei dati, in particolare sul set di caratteri specificato e sulle regole di confronto selezionate. Ogni set di caratteri e regole di confronto ha il suo scopo e richiede principalmente lunghezze diverse. Se hai tabelle che richiedono altri set di caratteri e regole di confronto a causa della codifica dei caratteri, i dati da archiviare ed elaborare per il tuo database e tabelle o anche con colonne.
Ciò influisce su come gestire il database in modo efficace. Influisce sull'archiviazione dei dati e sulle prestazioni, come indicato in precedenza. Se hai compreso i tipi di caratteri che devono essere elaborati dalla tua applicazione, prendi nota del set di caratteri e delle regole di confronto da utilizzare. I tipi di set di caratteri LATINO sono sufficienti principalmente per il tipo di caratteri alfanumerici da memorizzare ed elaborare.
Se è inevitabile, lo sharding e il partizionamento aiutano almeno a mitigare e limitare i dati per evitare di gonfiare troppi dati nel server del database. La gestione di dati di grandi dimensioni su un singolo server di database può influire sull'efficienza, in particolare per scopi di backup, disastro e ripristino o anche per il ripristino dei dati in caso di danneggiamento o perdita di dati.
La complessità del database influisce sulle prestazioni
Un database grande e complesso tende ad avere un fattore quando si tratta di penalizzazione delle prestazioni. Complesso, in questo caso, significa che il contenuto del database è costituito da equazioni matematiche, coordinate o record numerici e finanziari. Ora ho mescolato questi record con query che utilizzano in modo aggressivo le funzioni matematiche native del suo database. Dai un'occhiata alla query SQL di esempio (compatibile con MySQL/MariaDB) di seguito,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Considera che questa query sia applicata su una tabella che varia da un milione di righe. Esiste un'enorme possibilità che ciò possa arrestare il server e potrebbe richiedere un uso intensivo delle risorse causando un pericolo per la stabilità del cluster di database di produzione. Le colonne coinvolte tendono ad essere indicizzate per ottimizzare e rendere efficiente questa query. Tuttavia, l'aggiunta di indici alle colonne di riferimento per prestazioni ottimali non garantisce l'efficienza della gestione di database di grandi dimensioni.
Quando si gestisce la complessità, il modo più efficiente è evitare l'uso rigoroso di equazioni matematiche complesse e l'uso aggressivo di questa complessa capacità computazionale incorporata. Questo può essere gestito e trasportato attraverso calcoli complessi utilizzando linguaggi di programmazione back-end invece di utilizzare il database. Se disponi di calcoli complessi, perché non archiviare queste equazioni nel database, recuperare le query, organizzarle in un modo più facile da analizzare o eseguire il debug quando necessario.
Stai utilizzando il motore di database giusto?
Una struttura dati influisce sulle prestazioni del server di database in base alla combinazione della query fornita e dei record letti o recuperati dalla tabella. I motori di database all'interno di MySQL/MariaDB supportano InnoDB e MyISAM che utilizzano B-Trees, mentre i motori di database NDB o Memory utilizzano la mappatura hash. Queste strutture dati hanno la sua notazione asintotica che esprime le prestazioni degli algoritmi utilizzati da queste strutture dati. In Informatica li chiamiamo notazione Big O che descrive le prestazioni o la complessità di un algoritmo. Dato che InnoDB e MyISAM utilizzano B-Trees, utilizza O(log n) per la ricerca. Considerando che le tabelle hash o le mappe hash usano O(n). Entrambi condividono il caso medio e peggiore per le sue prestazioni con la sua notazione.
Ora tornando sul motore specifico, data la struttura dei dati del motore, la query da applicare in base ai dati di destinazione da recuperare influisce ovviamente sulle prestazioni del server del database. Le tabelle hash non possono eseguire il recupero dell'intervallo, mentre B-Trees è molto efficiente per eseguire questi tipi di ricerche e può anche gestire grandi quantità di dati.
Utilizzando il motore giusto per i dati che memorizzi, devi identificare il tipo di query che applichi per questi dati specifici che memorizzi. Che tipo di logica dovranno formulare questi dati quando si trasformeranno in una logica di business.
Trattare con migliaia o migliaia di database, utilizzando il motore giusto in combinazione con le tue query e i dati che desideri recuperare e archiviare fornirà buone prestazioni. Dato che hai predeterminato e analizzato i tuoi requisiti per il suo scopo per il giusto ambiente di database.
Strumenti giusti per gestire database di grandi dimensioni
È molto difficile e difficile gestire un database molto grande senza una piattaforma solida su cui fare affidamento. Anche con ingegneri di database bravi e qualificati, tecnicamente il server di database che stai utilizzando è soggetto a errori umani. Un errore di qualsiasi modifica ai parametri e alle variabili di configurazione potrebbe comportare una modifica drastica che potrebbe peggiorare le prestazioni del server.
L'esecuzione del backup sul database su un database molto grande a volte potrebbe essere difficile. Ci sono casi in cui il backup potrebbe non riuscire per strani motivi. In genere, le query che potrebbero arrestare il server su cui è in esecuzione il backup causano un errore. Altrimenti, devi indagare sulla causa.
L'utilizzo dell'automazione come Chef, Puppet, Ansible, Terraform o SaltStack può essere utilizzato come IaC per fornire attività più rapide da eseguire. Durante l'utilizzo anche di altri strumenti di terze parti per aiutarti a monitorare e fornire immagini di grafici di alta qualità. I sistemi di allerta e notifica di allarme sono anche molto importanti per avvisarti di problemi che possono verificarsi dall'avviso al livello di stato critico. È qui che ClusterControl è molto utile in questo tipo di situazione.
ClusterControl consente di gestire facilmente un gran numero di database o anche con tipi di ambienti partizionati. È stato testato e installato migliaia di volte ed è stato messo in produzione fornendo allarmi e notifiche ai DBA, agli ingegneri o ai DevOps che gestiscono l'ambiente del database. Da staging o sviluppo, QA, all'ambiente di produzione.
ClusterControl può anche eseguire un backup e un ripristino. Anche con database di grandi dimensioni, può essere efficiente e facile da gestire poiché l'interfaccia utente fornisce la pianificazione e ha anche opzioni per caricarlo nel cloud (AWS, Google Cloud e Azure).
C'è anche una verifica di backup e molte opzioni come crittografia e compressione. Vedi ad esempio lo screenshot qui sotto (creazione di un backup per MySQL usando Xtrabackup):
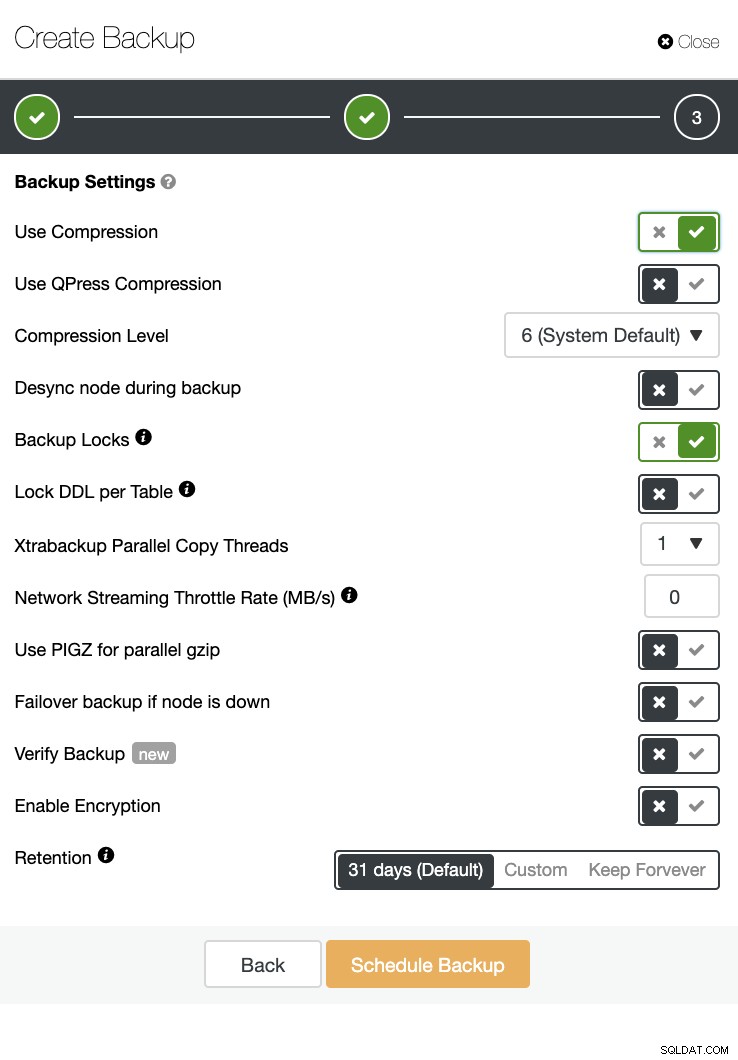
Conclusione
La gestione di database di grandi dimensioni come un migliaio o più può essere eseguita in modo efficiente, ma deve essere determinata e preparata in anticipo. L'utilizzo degli strumenti giusti come l'automazione o persino l'abbonamento a servizi gestiti aiuta notevolmente. Sebbene comporti dei costi, l'inversione del servizio e il budget da versare per acquisire ingegneri qualificati possono essere ridotti purché siano disponibili gli strumenti giusti.



