Questo post sul blog è una continuazione della parte 1 precedente, in cui abbiamo trattato le basi dell'integrazione SNMP con ClusterControl.
In questo post del blog, ci concentreremo sulle trap SNMP e sugli avvisi. Le trap SNMP sono i messaggi di avviso più utilizzati inviati da un dispositivo abilitato SNMP remoto (un agente) a un raccoglitore centrale, il "gestore SNMP". Nel caso di ClusterControl, una trap potrebbe essere un avviso dopo che l'allarme critico per un cluster non è 0, indicando che sta accadendo qualcosa di brutto.
Come mostrato nel post precedente del blog, ai fini di questa prova di concetto, abbiamo due definizioni di notifiche trap SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Le notifiche (o trap) sono criticalAlarmNotification e criticalAlarmNotificationEnded. Entrambi gli eventi di notifica possono essere utilizzati per segnalare il nostro servizio Nagios, indipendentemente dal fatto che il cluster stia attivamente presentando allarmi critici o meno. In Nagios, il termine per questo è controllo passivo, per cui Nagios non tenta di determinare se o host/servizio è DOWN o UNREACHABLE. Configureremo anche i controlli attivi, dove i controlli vengono avviati dalla logica di controllo nel demone Nagios utilizzando la definizione del servizio per monitorare anche gli allarmi critici/avvisi segnalati dal nostro cluster.
Tieni presente che questo post del blog richiede l'agente SNMP e MIB di Multiplenines configurati correttamente come mostrato nella prima parte di questa serie di blog.
Installazione di Nagios Core
Nagios Core è la versione gratuita della suite di monitoraggio Nagios. Innanzitutto, dobbiamo installarlo e tutti i pacchetti necessari, seguiti dai plugin Nagios, snmptrapd e snmptt. Tieni presente che le istruzioni in questo post del blog presuppongono che tutti i nodi siano in esecuzione su CentOS 7.
Installa i pacchetti necessari per eseguire Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlCrea un utente nagios e un gruppo nagcmd per consentire l'esecuzione dei comandi esterni tramite l'interfaccia web, aggiungi l'utente nagios e apache per far parte del gruppo nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheScarica l'ultima versione di Nagios Core da qui, compilala e installala:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstalla la configurazione web di Nagios:
$ make install-webconfOpzionalmente, installa il tema esfoliante Nagios (oppure puoi attenerti al tema predefinito):
$ make install-exfoliationCrea un account utente (nagiosadmin) per accedere all'interfaccia web di Nagios. Ricorda la password che assegni a questo utente:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminRiavvia il server web Apache per rendere effettive le nuove impostazioni:
$ systemctl restart httpd
$ systemctl enable httpdScarica i plug-in Nagios da qui, compilalo e installalo:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installVerifica i file di configurazione Nagios predefiniti:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosApri il browser e vai su https://{IPaddress}/nagios e dovresti visualizzare un'autenticazione di base HTTP in cui devi specificare il nome utente come nagiosadmin con la password scelta creata in precedenza.
Aggiunta del server ClusterControl in Nagios
Crea un file di definizione host Nagios per ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgE aggiungi le seguenti righe:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Alcune spiegazioni:
-
Nella prima sezione definiamo il nostro host, con l'hostname e l'indirizzo del server ClusterControl.
-
Le sezioni di servizio in cui mettiamo le nostre definizioni di servizio per essere monitorate dai Nagios. I primi due in pratica dicono al servizio di controllare l'output SNMP per un particolare ID oggetto. Il primo servizio riguarda l'allarme critico, quindi aggiungiamo -c0 nel comando check_snmp per indicare che dovrebbe essere un avviso critico in Nagios se il valore va oltre 0. Mentre per gli allarmi di avviso, lo indicheremo con un avviso se il valore è 1 e superiore.
-
L'ultima definizione del servizio riguarda le trap SNMP che ci aspetteremmo provenienti dal server ClusterControl se l'allarme critico sollevato è maggiore di 0. Questa sezione utilizzerà la definizione snmp_trap_template, come mostrato nel passaggio successivo.
Configura snmp_trap_template aggiungendo le seguenti righe in /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Includi il file di configurazione di ClusterControl in Nagios, aggiungendo la seguente riga all'interno
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgEsegui un controllo della configurazione prima del volo:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgAssicurati di ottenere la seguente riga alla fine dell'output:
"Things look okay - No serious problems were detected during the pre-flight check"Riavvia Nagios per caricare la modifica:
$ systemctl restart nagiosOra, se guardiamo la pagina di Nagios nella sezione Servizio (menu a sinistra), vedremmo qualcosa del genere:
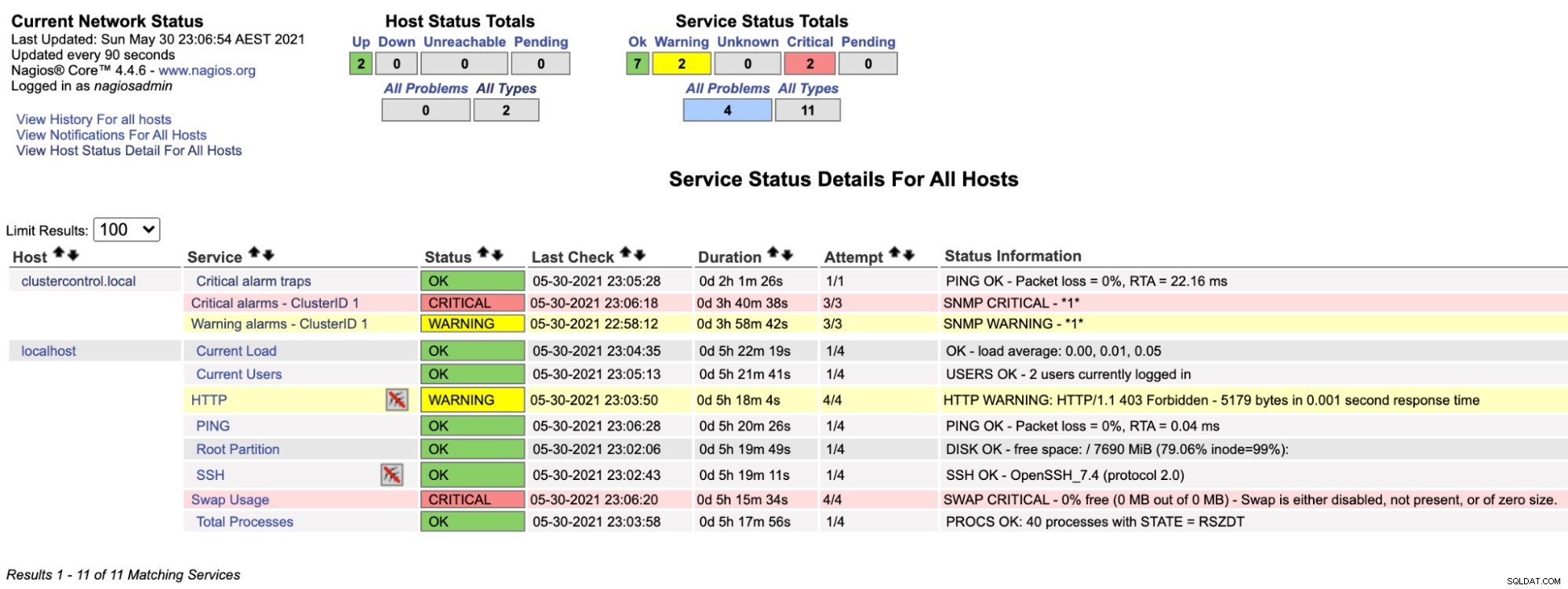
Si noti che la riga "Allarmi critici - ClusterID 1" diventa rossa se il valore di allarme critico riportato da ClusterControl è maggiore di 0, mentre "Allarmi di avviso - ClusterID 1" è giallo, a indicare che è stato generato un allarme di avviso. Nel caso in cui non accada nulla di interessante, vedresti che tutto è verde per clustercontrol.local.
Configurazione di Nagios per ricevere una trappola
Le trap vengono inviate da dispositivi remoti al server Nagios, questo è chiamato controllo passivo. Idealmente, non sappiamo quando verrà inviata una trap poiché dipende dal dispositivo di invio che decide che invierà una trap. Ad esempio con un UPS (batteria di backup), non appena il dispositivo perde alimentazione, invierà una trappola per dire "ehi, ho perso energia". In questo modo Nagios viene informato immediatamente.
Per ricevere trap SNMP, dobbiamo configurare il server Nagios con le seguenti cose:
-
snmptrapd (daemon SNMP trap receiver)
-
snmptt (SNMP Trap Translator, il demone trap handler)
Dopo che snmptrapd ha ricevuto un trap, lo passerà a snmptt dove lo configureremo per aggiornare il sistema Nagios e quindi Nagios invierà l'avviso in base alla configurazione del gruppo di contatti.
Installa il repository EPEL, seguito dai pacchetti necessari:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogConfigura il demone trap SNMP in /etc/snmp/snmptrapd.conf e imposta le seguenti righe:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerCiò sopra significa semplicemente che le trap ricevute dal demone snmptrapd verranno passate a /usr/sbin/snmptthandler.
Aggiungi SEVERALNINES-CLUSTERCONTROL-MIB.txt in /usr/share/snmp/mibs creando /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtCrea /etc/snmp/snmp.conf (avviso senza la "d") e aggiungi qui il nostro MIB personalizzato:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBAvvia il servizio snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdSuccessivamente, dobbiamo configurare le seguenti righe di configurazione all'interno di /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDNota che abbiamo abilitato il modulo net_snmp_perl e abbiamo aggiunto un altro percorso di configurazione, /etc/snmp/snmptt-cc.conf all'interno di snmptt.ini. È necessario definire gli eventi snmptt ClusterControl qui in modo che possano essere passati a Nagios. Crea un nuovo file in /etc/snmp/snmptt-cc.conf e aggiungi le seguenti righe:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCAlcune spiegazioni:
-
Abbiamo due trap definite:criticalAlarmNotification e criticalAlarmNotificationEnded.
-
criticalAlarmNotification genera semplicemente un avviso critico e lo passa al servizio "Trappole di allarme critico" definito in Nagios. $aA significa restituire l'indirizzo IP dell'agente trap. Il valore 2 è il valore del risultato del controllo che in questo caso è critico (0=OK, 1=AVVISO, 2=CRITICO, 3=SCONOSCIUTO).
-
Il criticalAlarmNotificationEnded genera semplicemente un avviso OK e lo passa al servizio "Trappole di allarme critiche", per annullare il trappola precedente dopo che tutto è tornato alla normalità. $aA significa restituire l'indirizzo IP dell'agente trap. Il valore 0 è il valore del risultato del controllo che in questo caso è OK. Per maggiori dettagli sulle sostituzioni di stringhe riconosciute da snmptt, consulta questo articolo nella sezione "FORMAT".
-
Puoi usare snmpttconvertmib per generare il file del gestore di eventi snmptt per un MIB particolare.
Si noti che per impostazione predefinita, il percorso dei gestori di eventi non è fornito da Nagios Core. Pertanto, dobbiamo copiare la directory dei gestori di eventi dall'origine di Nagios nella directory contrib, come mostrato di seguito:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersDobbiamo anche assegnare il gruppo snmptt come parte del gruppo nagcmd, in modo che possa eseguire nagios.cmd all'interno dello script submit_check_result:
$ usermod -a -G nagcmd snmpttAvvia il servizio snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttSNMP Manager (server Nagios) è ora pronto per accettare ed elaborare le nostre trap SNMP in entrata.
Invio di una trap dal server ClusterControl
Supponiamo di voler inviare una trap SNMP al gestore SNMP, 192.168.10.11 (server Nagios) poiché il numero totale di allarmi critici ha raggiunto 2 per l'ID cluster 1, si dovrebbe eseguire il comando seguente su il server ClusterControl (lato client), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Oppure, in formato OID (consigliato):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Dove, .1.3.6.1.4.1.57397.1.1.3.1 è uguale all'evento trap criticalAlarmNotification e gli OID successivi sono rappresentazioni rispettivamente del numero totale degli allarmi critici attuali e dell'ID del cluster .
Sul server Nagios, dovresti notare che il servizio trap è diventato rosso:
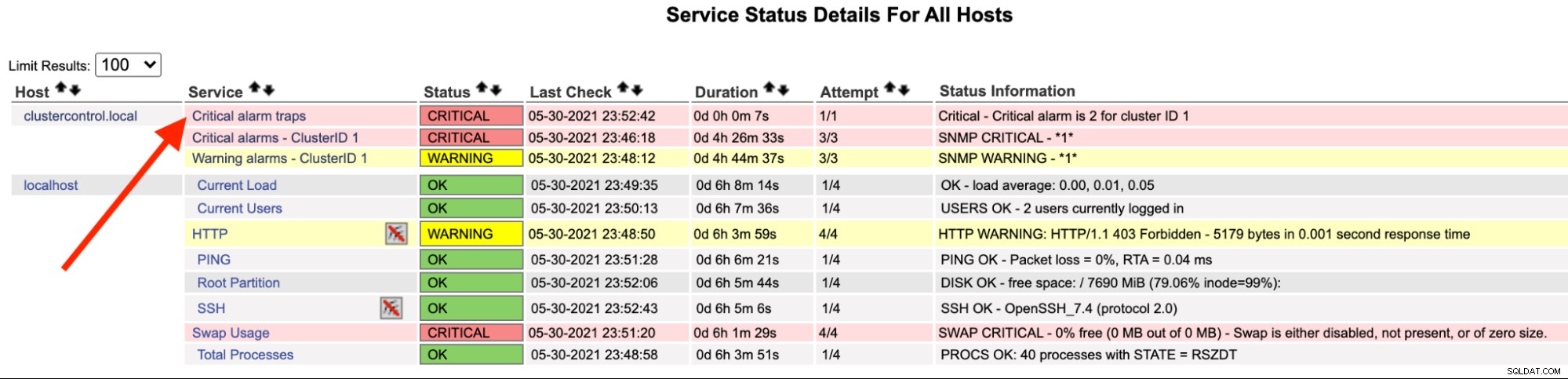
Puoi anche vederlo in /var/log/messages della seguente riga:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Una volta risolto l'allarme, per inviare una normale trappola, possiamo eseguire il seguente comando:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Dove, .1.3.6.1.4.1.57397.1.1.3.2 è uguale all'evento criticalAlarmNotificationEnded e gli OID successivi sono rappresentazioni del numero totale degli allarmi critici attuali (dovrebbe essere 0 per questo caso ) e l'ID del cluster, rispettivamente.
Sul server Nagios, dovresti notare che il servizio trap è tornato verde:
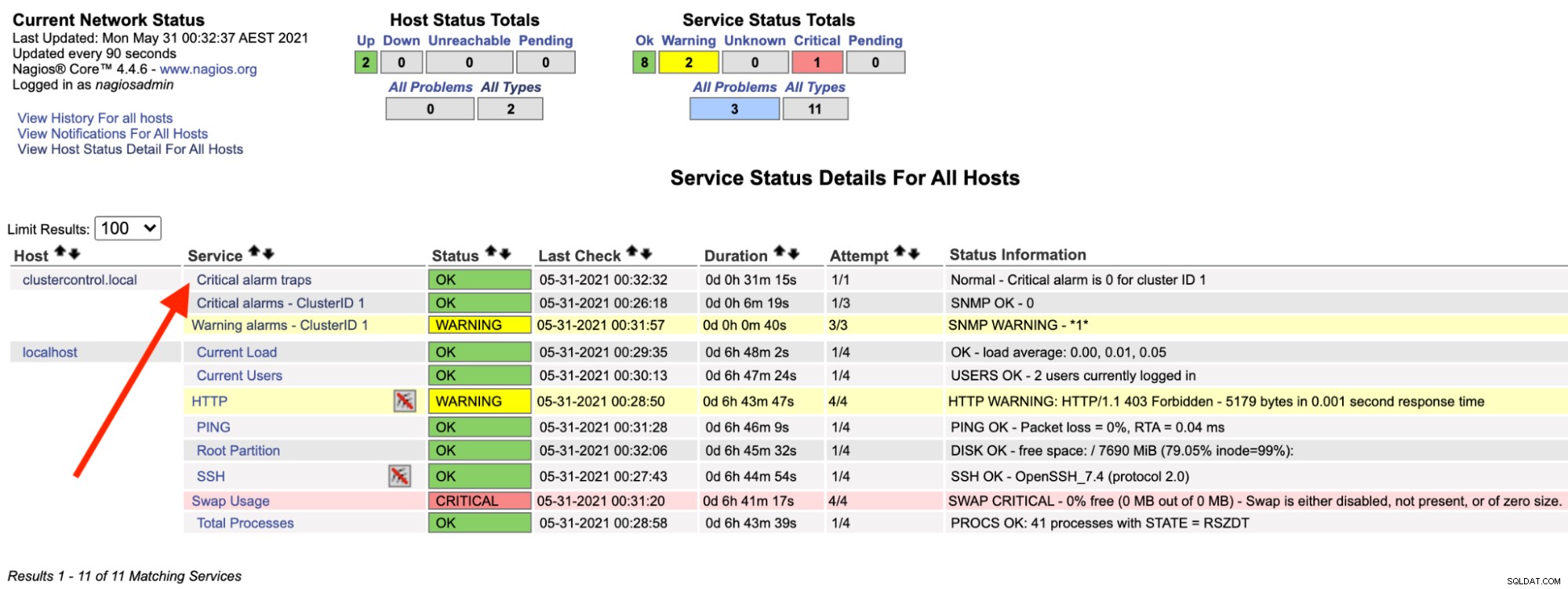
Quanto sopra può essere automatizzato con un semplice script bash:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
donePer eseguire lo script in background, fai semplicemente:
$ bash alarmtrapper.bash &A questo punto, dovremmo essere in grado di vedere il servizio "Trappole di allarme critiche" di Nagios in azione se si verifica automaticamente un errore nel nostro cluster.
Pensieri finali
In questa serie di blog, abbiamo mostrato un proof-of-concept su come ClusterControl può essere configurato per il monitoraggio, la generazione/elaborazione di trap e gli avvisi utilizzando il protocollo SNMP. Questo segna anche l'inizio del nostro viaggio per incorporare SNMP nelle nostre versioni future. Resta sintonizzato perché porteremo altri aggiornamenti su questa entusiasmante funzionalità.



