In questo articolo creeremo un raschietto per un effettivo concerto freelance in cui il cliente desidera che un programma Python raccolga dati da Stack Overflow per acquisire nuove domande (titolo e URL della domanda). I dati raschiati dovrebbero quindi essere archiviati in MongoDB. Vale la pena notare che Stack Overflow ha un'API, che può essere utilizzata per accedere a esatto stessi dati. Tuttavia, il cliente voleva un raschietto, quindi un raschietto è quello che ha ottenuto.
Bonus gratuito: Fare clic qui per scaricare uno scheletro di progetto Python + MongoDB con codice sorgente completo che mostra come accedere a MongoDB da Python.
Aggiornamenti:
- 01/03/2014 - Rifattorizzato il ragno. Grazie, @kissgyorgy.
- 18/02/2015 - Aggiunta parte 2.
- 09/06/2015 - Aggiornato all'ultima versione di Scrapy e PyMongo - evviva!
Come sempre, assicurati di leggere i termini di utilizzo/servizio del sito e di rispettare il robots.txt file prima di iniziare qualsiasi lavoro di raschiatura. Assicurati di aderire alle pratiche di scraping etico non inondando il sito di numerose richieste in un breve lasso di tempo. Tratta qualsiasi sito che raschia come se fosse il tuo .
Installazione
Abbiamo bisogno della libreria Scrapy (v1.0.3) insieme a PyMongo (v3.0.3) per archiviare i dati in MongoDB. Devi installare anche MongoDB (non coperto).
Scrapy
Se stai utilizzando OSX o una versione di Linux, installa Scrapy con pip (con il tuo virtualenv attivato):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Se sei su una macchina Windows, dovrai installare manualmente una serie di dipendenze. Fare riferimento alla documentazione ufficiale per istruzioni dettagliate e a questo video di Youtube che ho creato.
Una volta che Scrapy è configurato, verifica la tua installazione eseguendo questo comando nella shell Python:
>>>>>> import scrapy
>>>
Se non ricevi un errore, allora sei a posto!
PyMongo
Quindi, installa PyMongo con pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Ora possiamo iniziare a costruire il crawler.
Progetto di rottamazione
Iniziamo un nuovo progetto Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Questo crea una serie di file e cartelle che include una base standard per iniziare rapidamente:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Specifica i dati
Il items.py viene utilizzato per definire i "contenitori" di archiviazione per i dati che intendiamo raccogliere.
Il StackItem() la classe eredita da Item (docs), che fondamentalmente ha un numero di oggetti predefiniti che Scrapy ha già creato per noi:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Aggiungiamo alcuni oggetti che vogliamo effettivamente collezionare. Per ogni domanda il cliente ha bisogno del titolo e dell'URL. Quindi, aggiorna items.py così:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Crea il ragno
Crea un file chiamato stack_spider.py nella directory "ragni". È qui che avviene la magia, ad esempio dove diremo a Scrapy come trovare l'esatto dati che stiamo cercando. Come puoi immaginare, questo è specifico a ogni singola pagina web che desideri raschiare.
Inizia definendo una classe che erediti da Spider di Scrapy e quindi aggiungendo gli attributi secondo necessità:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Le prime variabili sono autoesplicative (documenti):
namedefinisce il nome del Ragno.allowed_domainscontiene gli URL di base per i domini consentiti per la scansione dello spider.start_urlsè un elenco di URL da cui lo spider può iniziare la scansione. Tutti gli URL successivi inizieranno dai dati che lo spider scarica dagli URL instart_urls.
Selettori XPath
Successivamente, Scrapy utilizza i selettori XPath per estrarre i dati da un sito Web. In altre parole, possiamo selezionare alcune parti dei dati HTML in base a un determinato XPath. Come affermato nella documentazione di Scrapy, "XPath è un linguaggio per selezionare i nodi nei documenti XML, che può essere utilizzato anche con HTML".
Puoi facilmente trovare un Xpath specifico utilizzando gli strumenti per sviluppatori di Chrome. Ispeziona semplicemente un elemento HTML specifico, copia l'XPath e quindi modifica (se necessario):
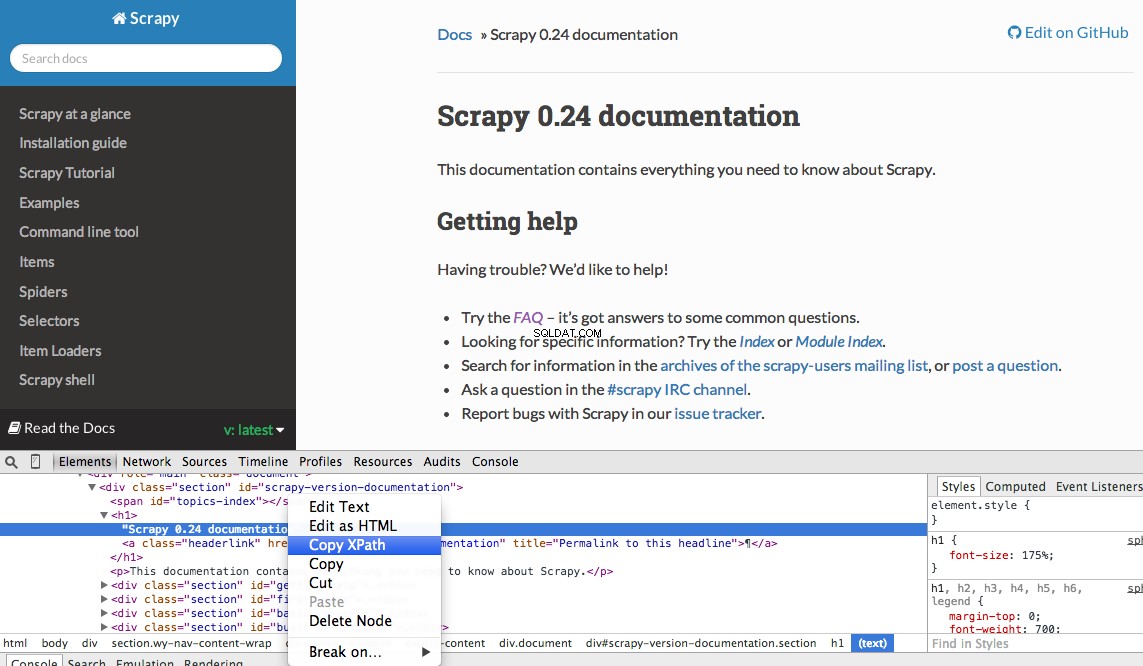
Strumenti per sviluppatori ti dà anche la possibilità di testare i selettori XPath nella console JavaScript utilizzando $x - cioè $x("//img") :
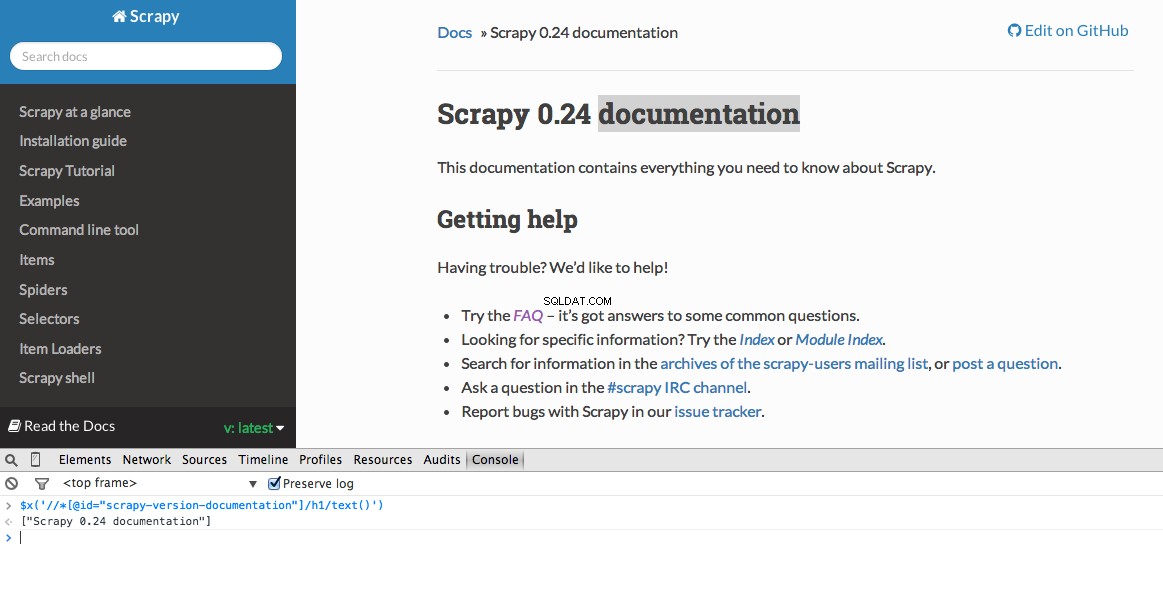
Di nuovo, fondamentalmente diciamo a Scrapy da dove iniziare a cercare informazioni sulla base di un XPath definito. Andiamo al sito Stack Overflow in Chrome e troviamo i selettori XPath.
Fare clic con il tasto destro sulla prima domanda e selezionare "Ispeziona elemento":
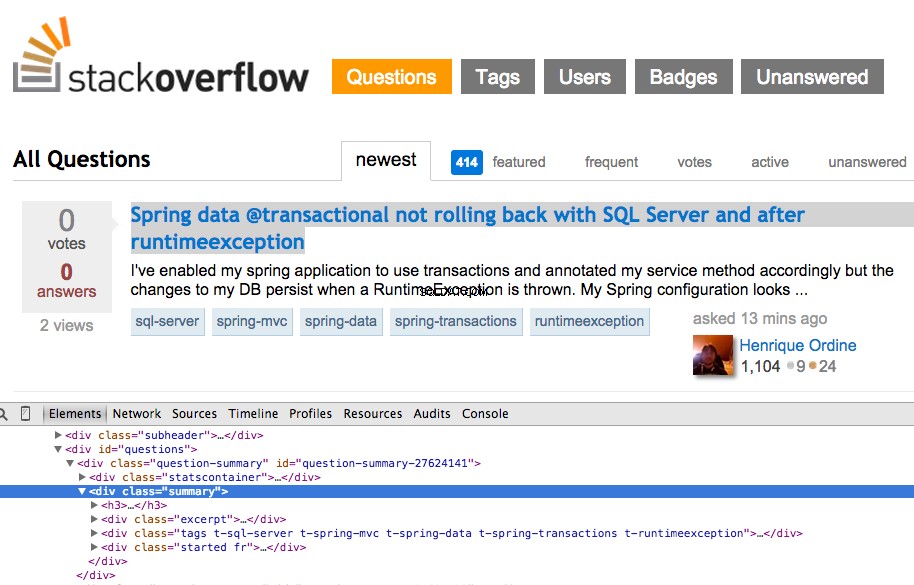
Ora prendi l'XPath per il <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , quindi provalo nella Console JavaScript:
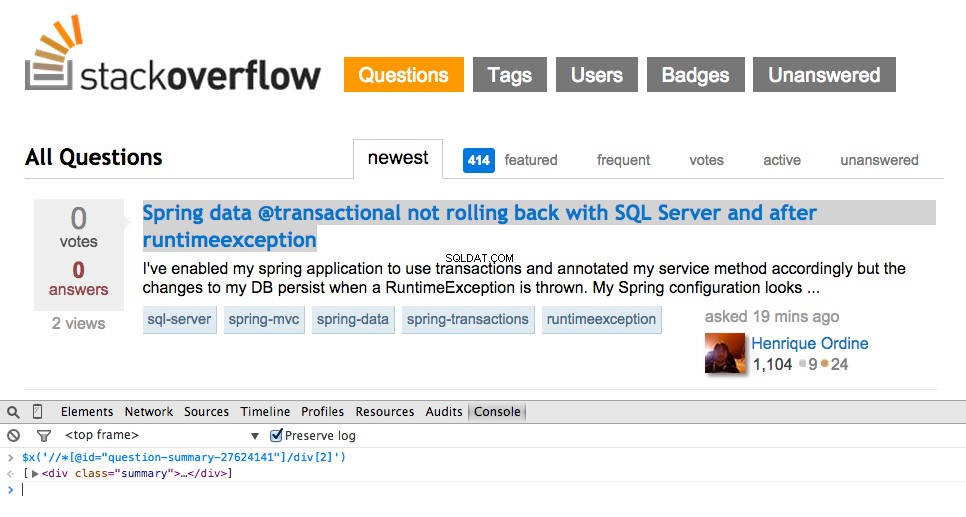
Come puoi vedere, seleziona semplicemente quello uno domanda. Quindi abbiamo bisogno di modificare l'XPath per prendere tutto domande. Qualche idea? È semplice://div[@class="summary"]/h3 . Cosa significa questo? In sostanza, questo XPath afferma:Grab all <h3> elementi che sono figli di un <div> che ha una classe di summary . Prova questo XPath nella console JavaScript.
Nota come non stiamo utilizzando l'output XPath effettivo da Chrome Developer Tools. Nella maggior parte dei casi, l'output è solo un utile a parte, che generalmente indica la giusta direzione per trovare l'XPath funzionante.
Ora aggiorniamo stack_spider.py sceneggiatura:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Estrai i Dati
Dobbiamo ancora analizzare e raschiare i dati che desideriamo, che rientrano in <div class="summary"><h3> . Ancora una volta, aggiorna stack_spider.py così:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Insieme alla traccia dello stack Scrapy, dovresti vedere 50 titoli di domande e URL emessi. Puoi eseguire il rendering dell'output in un file JSON con questo piccolo comando:
$ scrapy crawl stack -o items.json -t json
Ora abbiamo implementato il nostro Spider in base ai nostri dati che stiamo cercando. Ora dobbiamo archiviare i dati raschiati all'interno di MongoDB.
Memorizza i dati in MongoDB
Ogni volta che un articolo viene restituito, vogliamo convalidare i dati e quindi aggiungerlo a una collezione Mongo.
Il passaggio iniziale consiste nel creare il database che prevediamo di utilizzare per salvare tutti i nostri dati scansionati. Apri impostazioni.py e specifica la pipeline e aggiungi le impostazioni del database:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Gestione delle condutture
Abbiamo impostato il nostro spider per eseguire la scansione e l'analisi dell'HTML e abbiamo configurato le impostazioni del nostro database. Ora dobbiamo collegare i due insieme attraverso una pipeline in pipelines.py .
Connetti al database
Per prima cosa, definiamo un metodo per connetterci effettivamente al database:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Qui creiamo una classe, MongoDBPipeline() e abbiamo una funzione di costruzione per inizializzare la classe definendo le impostazioni di Mongo e quindi connettendoci al database.
Elabora i dati
Successivamente, dobbiamo definire un metodo per elaborare i dati analizzati:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Stabiliamo una connessione al database, decomprimiamo i dati e quindi li salviamo nel database. Ora possiamo provare di nuovo!
Test
Ancora una volta, esegui il seguente comando all'interno della directory "stack":
$ scrapy crawl stack
NOTA :Assicurati di avere il demone Mongo - mongod - in esecuzione in un'altra finestra del terminale.
Evviva! Abbiamo archiviato con successo i nostri dati scansionati nel database:
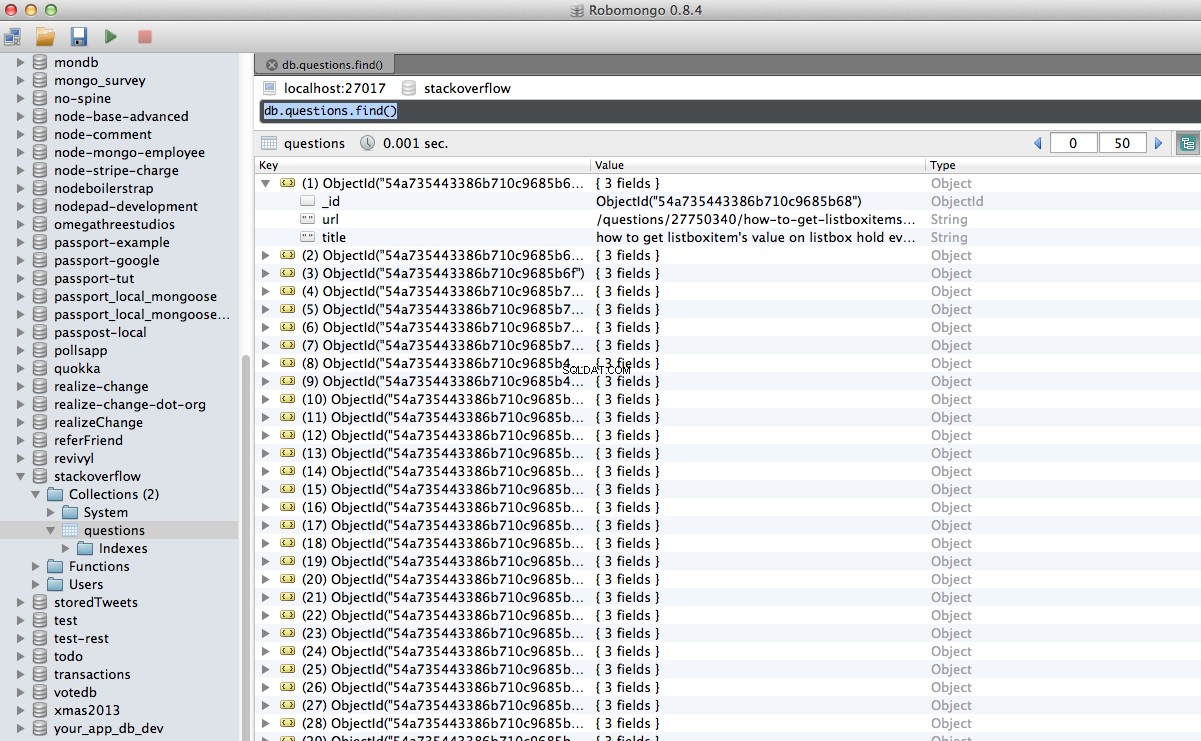
Conclusione
Questo è un esempio piuttosto semplice dell'utilizzo di Scrapy per eseguire la scansione e lo scraping di una pagina Web. Il progetto freelance vero e proprio richiedeva che lo script seguisse i collegamenti di impaginazione e raschiasse ogni pagina utilizzando il CrawlSpider (docs), che è semplicissimo da implementare. Prova a implementarlo da solo e lascia un commento qui sotto con il collegamento al repository Github per una rapida revisione del codice.
Ho bisogno di aiuto? Inizia con questo script, che è quasi completo. Quindi guarda la Parte 2 per la soluzione completa!
Bonus gratuito: Fare clic qui per scaricare uno scheletro di progetto Python + MongoDB con codice sorgente completo che mostra come accedere a MongoDB da Python.
Puoi scaricare l'intero codice sorgente dal repository Github. Commenta di seguito con domande. Grazie per aver letto!



