Riepilogo:
Ho eseguito ciascuna query 10 volte ciascuna utilizzando il set di dati di test di seguito.
- Un set di risultati di sottoquery molto grande (100000 righe)
- Righe duplicate
- Righe nulle
Per tutti gli scenari precedenti, entrambi IN e EXISTS eseguita in modo identico.
Alcune informazioni sul database Performance V3 utilizzato per il test.20000 clienti con 1000000 ordini, quindi ogni cliente viene duplicato casualmente (in un intervallo da 10 a 100) nella tabella degli ordini.
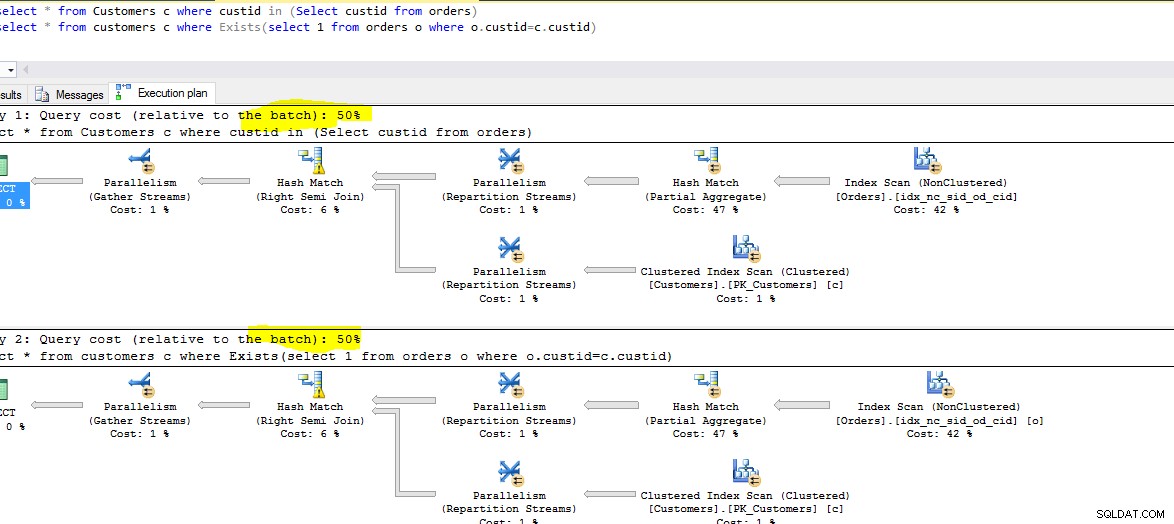
Costo di esecuzione,Tempo:
Di seguito è riportato uno screenshot di entrambe le query in esecuzione. Osserva il costo relativo di ogni query.
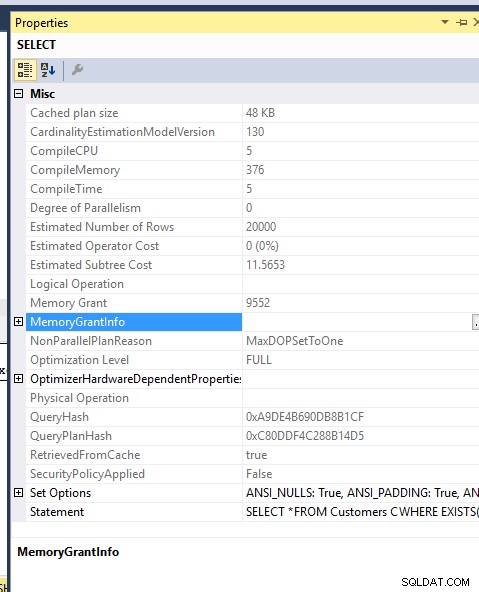
Costo della memoria:
Anche la concessione di memoria per le due query è la stessa..Ho forzato MDOP 1 per non riversarli su TEMPDB..
Tempo CPU ,Legge:
Per Esiste:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Per IN:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
In ogni caso, l'ottimizzatore è abbastanza intelligente da riorganizzare le query.
Tendo a usare EXISTS solo però (opinione mia). Un caso d'uso per usare EXISTS è quando non vuoi restituire un secondo set di risultati di tabella.
Aggiornamento in base alle domande di Martin Smith:
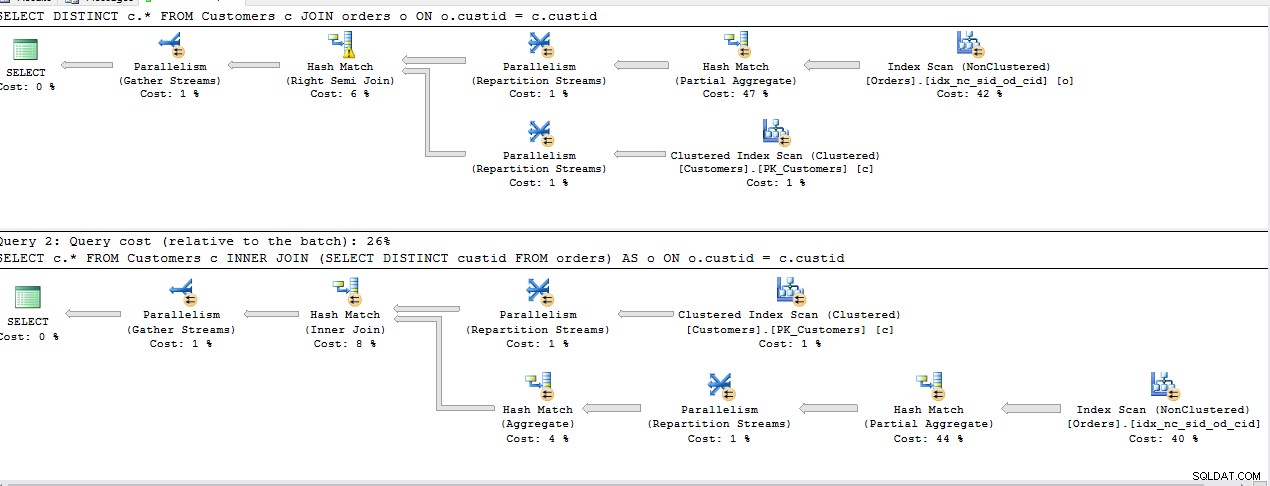
Ho eseguito le query seguenti per trovare il modo più efficace per ottenere righe dalla prima tabella per cui esiste un riferimento nella seconda tabella.
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
Tutte le query di cui sopra condividono lo stesso costo ad eccezione del 2° INNER JOIN , Pianifica che sia lo stesso per il resto.
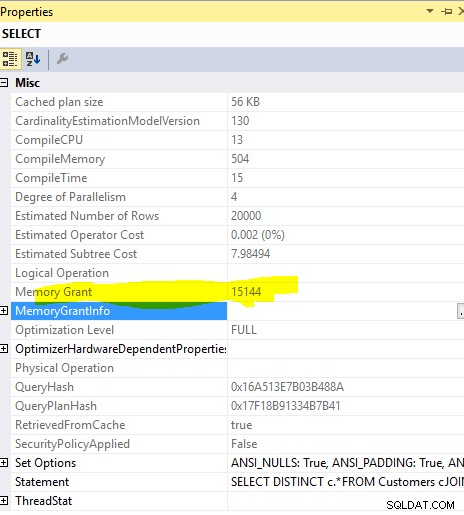
Concessione memoria:
Questa domanda
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
concessione di memoria richiesta di
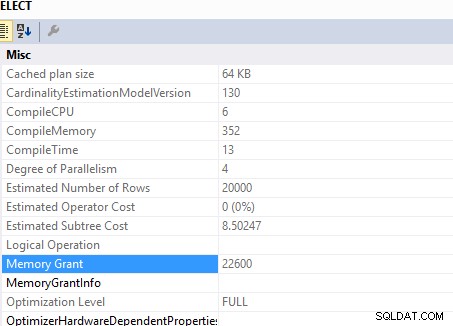
Questa domanda
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
concessione di memoria richiesta di ..
Tempo CPU,Lettura:
Per la query :
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
Per la domanda:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.