Sono d'accordo con @marc_s e @KM sul fatto che questo grande progetto sia condannato fin dall'inizio.
Milioni di ore di sviluppo di Microsoft sono state dedicate alla creazione e alla messa a punto di un motore di database robusto e potente, ma reinventerai tutto stipando tutto in un piccolo numero di tabelle generiche e implementando nuovamente tutto ciò che SQL Server è già progettato per fare per te.
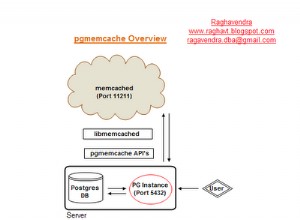
SQL Server dispone già di tabelle contenenti nomi di entità, nomi di colonne e così via. Il fatto che normalmente non si interagisca direttamente con queste tabelle di sistema è positivo:si chiama astrazione. Ed è improbabile che tu possa fare un lavoro migliore nell'implementazione di tale astrazione rispetto a SQL Server.
Alla fine della giornata, con il tuo approccio (a) anche le domande più semplici saranno mostruose; e (b) non ti avvicinerai mai a prestazioni ottimali, perché rinuncerai a tutta l'ottimizzazione delle query che altrimenti otterresti gratuitamente.
Senza sapere nulla di più sulla tua applicazione o sulle tue esigenze, è difficile dare qualsiasi tipo di consiglio specifico. Ma suggerirei che una buona vecchia normalizzazione farebbe molto. Qualsiasi database ben implementato e non banale ha molte tabelle; dieci tavoli più dieci tavoli xtab non dovrebbero spaventarti.
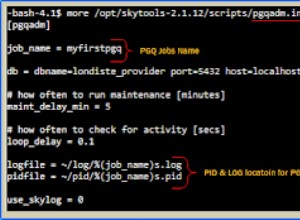
E non aver paura della generazione di codice SQL come metodo per implementare interfacce comuni su tabelle disparate. Un po' può fare molto.