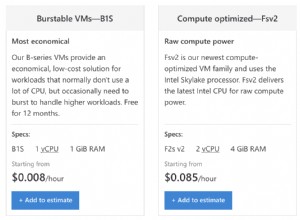
I tuoi requisiti non sono del tutto chiari ma sembra che tu stia cercando di creare una nuova colonna denominata c con poi un row_number() associato ad esso -- c1, c2 c3, etc .
Se dovessi utilizzare quanto segue nella tua sottoquery:
SELECT Val1, Val2,
'C'+ cast(row_number() over(partition by Val2
order by val1) as varchar(10)) col
FROM TEMP1
Vedi SQL Fiddle con demo
Otterresti il risultato:
| VAL1 | VAL2 | COL |
----------------------
| S01 | 00731 | C1 |
| S02 | 00731 | C2 |
| S03 | 00731 | C3 |
| S04 | 00731 | C4 |
| S05 | 00731 | C5 |
| S06 | 00731 | C6 |
| S07 | 00731 | C7 |
| S07 | 00731 | C8 |
| S08 | 00731 | C9 |
| S09 | 00731 | C10 |
| S04 | 00741 | C1 |
| S01 | 00746 | C1 |
| S01 | 00770 | C1 |
| S01 | 00771 | C1 |
| S02 | 00771 | C2 |
Che sembra essere il risultato che vuoi quindi PIVOT . Dovresti quindi applicare il PIVOT a questo usando:
SELECT Val2,
c1, c2, c3, c4, c5, c6, c7, c8, c9, c10
FROM
(
SELECT Val1, Val2,
'C'+ cast(row_number() over(partition by Val2
order by val1) as varchar(10)) col
FROM TEMP1
) src
PIVOT
(
MAX(Val1)
FOR col IN (C1, C2, C3, C4, C5, C6, C7, C8, C9, C10)
) piv;
Vedi SQL Fiddle con demo . Il tuo risultato finale è quindi:
| VAL2 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
------------------------------------------------------------------------------------------------
| 00731 | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S07 | S08 | S09 |
| 00741 | S04 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00746 | S01 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00770 | S01 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00771 | S01 | S02 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
Nota:i miei risultati sono leggermente diversi da quelli che stai richiedendo come risultato desiderato perché sto eseguendo un ORDER BY val1 che causa il S07 valori da raggruppare.
Non esiste un ordine di dati in un database a meno che tu non ne richieda uno, quindi non vi è alcuna garanzia che uno dei S07 i valori appariranno come C10 . Puoi utilizzare quanto segue per ottenere il risultato, ma nessuna garanzia che il risultato sarà sempre nell'ordine corretto:
SELECT Val2,
c1, c2, c3, c4, c5, c6, c7, c8, c9, c10
FROM
(
SELECT Val1, Val2,
'C'+ cast(row_number() over(partition by Val2
order by (select 1)) as varchar(10)) col
FROM TEMP1
) src
PIVOT
(
MAX(Val1)
FOR col IN (C1, C2, C3, C4, C5, C6, C7, C8, C9, C10)
) piv;
Vedi SQL Fiddle con demo
. Usando il order by (select 1) altera l'ordine dei dati ma non garantisce che saranno sempre in quell'ordine. Il risultato è:
| VAL2 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
------------------------------------------------------------------------------------------------
| 00731 | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | S07 |
| 00741 | S04 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00746 | S01 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00770 | S01 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |
| 00771 | S01 | S02 | (null) | (null) | (null) | (null) | (null) | (null) | (null) | (null) |