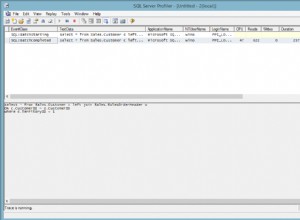
Una specie di. Dai un'occhiata a questa query:
SELECT total_worker_time/execution_count AS AvgCPU
, total_worker_time AS TotalCPU
, total_elapsed_time/execution_count AS AvgDuration
, total_elapsed_time AS TotalDuration
, (total_logical_reads+total_physical_reads)/execution_count AS AvgReads
, (total_logical_reads+total_physical_reads) AS TotalReads
, execution_count
, SUBSTRING(st.TEXT, (qs.statement_start_offset/2)+1
, ((CASE qs.statement_end_offset WHEN -1 THEN datalength(st.TEXT)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS txt
, query_plan
FROM sys.dm_exec_query_stats AS qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) AS st
cross apply sys.dm_exec_query_plan (qs.plan_handle) AS qp
ORDER BY 1 DESC
Questo ti porterà le query nella cache del piano in ordine di quanta CPU hanno consumato. Puoi eseguirlo periodicamente, come in un processo di SQL Agent, e inserire i risultati in una tabella per assicurarti che i dati persistano oltre i riavvii.
Quando leggerai i risultati, probabilmente ti renderai conto del motivo per cui non possiamo correlare quei dati direttamente a un singolo database. Innanzitutto, una singola query può anche nascondere il suo vero padre del database eseguendo trucchi come questo:
USE msdb
DECLARE @StringToExecute VARCHAR(1000)
SET @StringToExecute = 'SELECT * FROM AdventureWorks.dbo.ErrorLog'
EXEC @StringToExecute
La query verrebbe eseguita in MSDB, ma eseguirebbe il polling dei risultati di AdventureWorks. Dove dobbiamo assegnare il consumo di CPU?
Peggiora quando tu:
- Unisciti tra più database
- Esegui una transazione in più database e lo sforzo di blocco si estende su più database
- Esegui lavori di SQL Agent in MSDB che "funzionano" in MSDB, ma eseguono il backup di singoli database
Va avanti all'infinito. Ecco perché ha senso ottimizzare le prestazioni a livello di query anziché a livello di database.
In SQL Server 2008R2, Microsoft ha introdotto funzionalità di gestione delle prestazioni e di gestione delle app che ci consentiranno di impacchettare un singolo database in un pacchetto DAC distribuibile e distribuibile e promettono funzionalità per semplificare la gestione delle prestazioni dei singoli database e delle relative applicazioni. Tuttavia, non fa ancora quello che stai cercando.
Per ulteriori informazioni, consulta la Repository T-SQL nel wiki SQL Server di Toad World (precedentemente in SQLServerPedia) .
Aggiornato il 29/1 per includere i numeri totali anziché solo le medie.