La disponibilità, l'accessibilità e le prestazioni dei dati sono vitali per il successo aziendale. L'ottimizzazione delle prestazioni e l'ottimizzazione delle query SQL sono pratiche complicate ma necessarie per i professionisti dei database. Richiedono l'esame di varie raccolte di dati utilizzando eventi estesi, perfmon, piani di esecuzione, statistiche e indici per citarne alcuni. A volte, i proprietari delle applicazioni chiedono di aumentare le risorse di sistema (CPU e memoria) per migliorare le prestazioni del sistema. Tuttavia, potresti non richiedere queste risorse aggiuntive e possono avere un costo ad esse associato. A volte, tutto ciò che serve è apportare piccoli miglioramenti per modificare il comportamento della query.
In questo articolo, discuteremo alcune best practice per l'ottimizzazione delle query SQL da applicare durante la scrittura di query SQL.
SELECT * vs SELECT elenco colonne
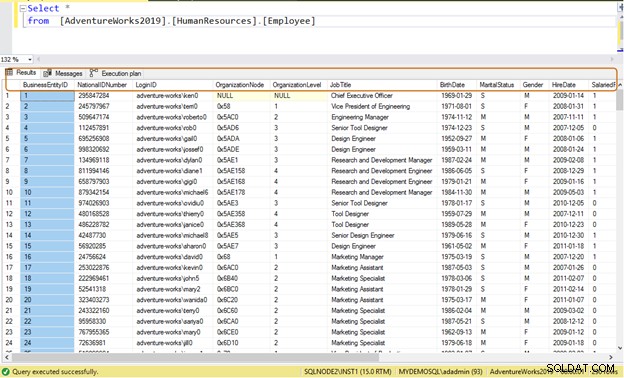
Di solito, gli sviluppatori utilizzano l'istruzione SELECT * per leggere i dati da una tabella. Legge tutti i dati disponibili della colonna nella tabella. Supponiamo una tabella [AdventureWorks2019].[HumanResources].[Employee] memorizza i dati per 290 dipendenti e tu hai l'obbligo di recuperare le seguenti informazioni:
- Numero di identificazione nazionale del dipendente
- Data di nascita
- Sesso
- Data di assunzione
Query inefficiente: Se utilizzi l'istruzione SELECT *, restituisce tutti i dati della colonna per tutti i 290 dipendenti.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
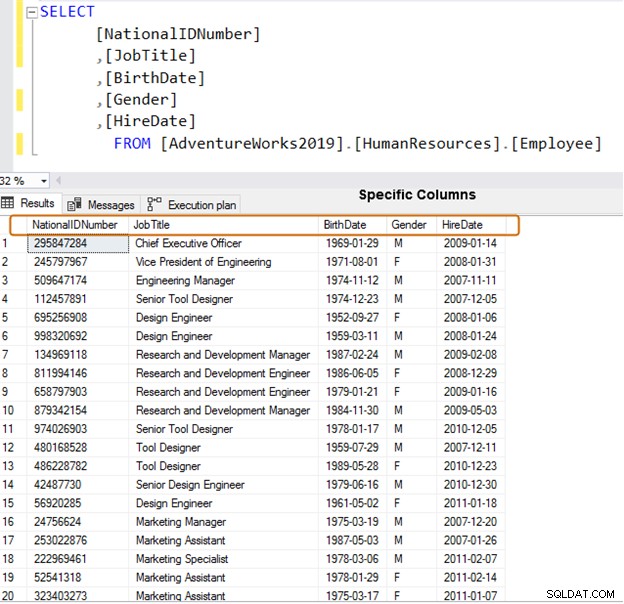
Utilizzare invece nomi di colonna specifici per il recupero dei dati.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
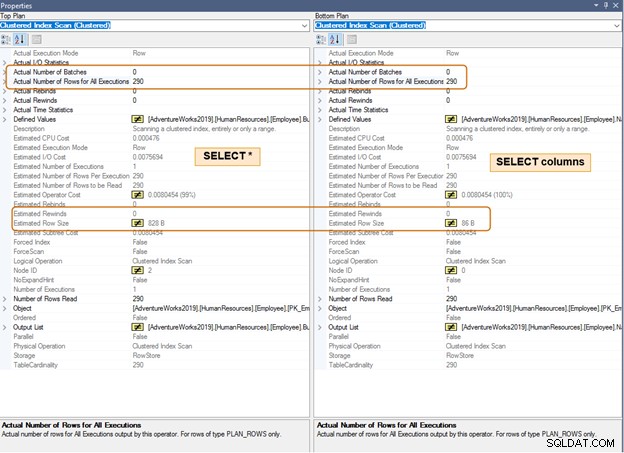
Nel piano di esecuzione seguente, notare la differenza nella dimensione stimata delle righe per lo stesso numero di righe. Noterai una differenza di CPU e IO anche per un gran numero di righe.
Utilizzo di COUNT() rispetto a EXISTS
Si supponga di voler controllare se esiste un record specifico nella tabella SQL. Di solito, utilizziamo COUNT (*) per controllare il record e restituisce il numero di record nell'output.
Tuttavia, possiamo usare la funzione IF EXISTS() per questo scopo. Per il confronto, ho abilitato le statistiche prima di eseguire le query.
La query per COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
La query per IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Ho usato statisticsparser per analizzare i risultati delle statistiche di entrambe le query. Guarda i risultati qui sotto. La query con COUNT(*) ha 276 letture logiche mentre IF EXISTS() ha 83 letture logiche. Puoi anche ottenere una riduzione più significativa delle letture logiche con IF EXISTS(). Pertanto, dovresti usarlo per ottimizzare le query SQL per prestazioni migliori.

Evita di usare SQL DISTINCT
Ogni volta che desideriamo record univoci dalla query, utilizziamo abitualmente la clausola SQL DISTINCT. Supponiamo di aver unito due tabelle insieme e nell'output restituisca le righe duplicate. Una soluzione rapida consiste nello specificare l'operatore DISTINCT che elimina la riga duplicata.
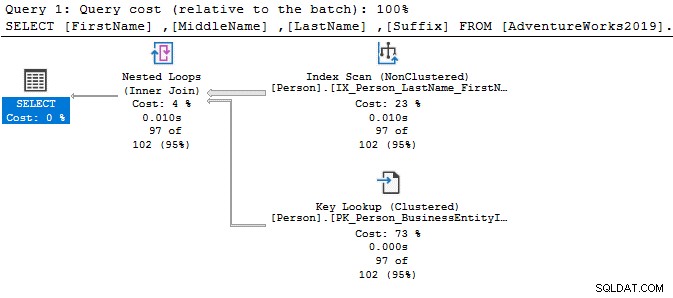
Diamo un'occhiata alle semplici istruzioni SELECT e confrontiamo i piani di esecuzione. L'unica differenza tra le due query è un operatore DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Con l'operatore DISTINCT, il costo della query è del 77%, mentre la query precedente (senza DISTINCT) ha solo il costo batch del 23%.
È possibile utilizzare GROUP BY, CTE o una sottoquery per scrivere codice SQL efficiente invece di utilizzare DISTINCT per ottenere valori distinti dal set di risultati. Inoltre, puoi recuperare colonne aggiuntive per un set di risultati distinto.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Utilizzo dei caratteri jolly nella query SQL
Si supponga di voler cercare i record specifici contenenti nomi che iniziano con la stringa specificata. Gli sviluppatori utilizzano un carattere jolly per cercare i record corrispondenti.
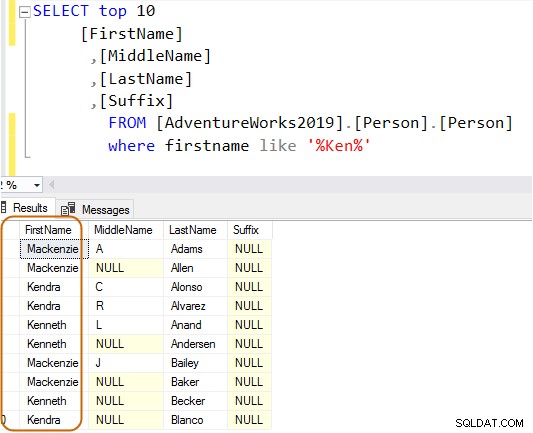
Nella query seguente, cerca la stringa Ken nella colonna del nome. Questa query recupera i risultati previsti di Ken dra e Ken neth. Ma fornisce anche risultati inaspettati, ad esempio Macken zie e Nken ge.
Nel piano di esecuzione, vedi la scansione dell'indice e la ricerca della chiave per la query precedente.
Puoi evitare il risultato imprevisto utilizzando il carattere jolly alla fine della stringa.
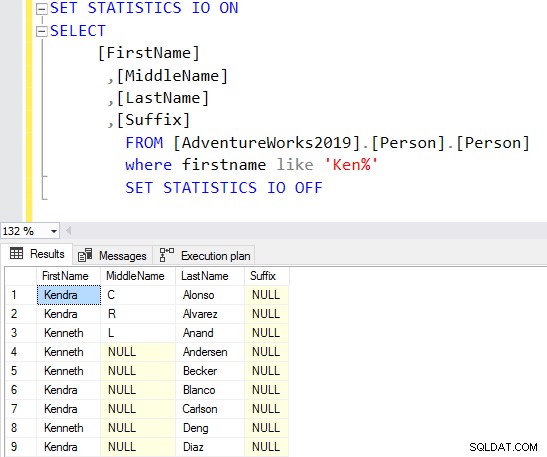
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Ora ottieni il risultato filtrato in base alle tue esigenze.
Utilizzando il carattere jolly all'inizio, Query Optimizer potrebbe non essere in grado di utilizzare l'indice appropriato. Come mostrato nella schermata seguente, con un carattere jolly finale, Query Optimizer suggerisce anche un indice mancante.
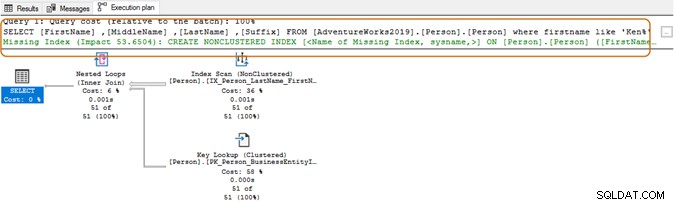
Qui, ti consigliamo di valutare i requisiti della tua applicazione. Dovresti cercare di evitare l'uso di un carattere jolly nelle stringhe di ricerca, poiché potrebbe costringere Query Optimizer a utilizzare una scansione della tabella. Se la tabella è enorme, richiederebbe risorse di sistema maggiori per IO, CPU e memoria e potrebbe causare problemi di prestazioni per la tua query SQL.
Utilizzo delle clausole WHERE e HAVING
Le clausole WHERE e HAVING vengono utilizzate come filtri di riga di dati. La clausola WHERE filtra i dati prima di applicare la logica di raggruppamento, mentre la clausola HAVING filtra le righe dopo i calcoli aggregati.
Ad esempio, nella query seguente, utilizziamo un filtro dati nella clausola HAVING senza una clausola WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
La query seguente filtra i dati prima nella clausola WHERE, quindi utilizza la clausola HAVING per il filtro dei dati aggregati.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Consiglio di utilizzare la clausola WHERE per il filtraggio dei dati e la clausola HAVING per il filtro dei dati aggregati come best practice.
Utilizzo delle clausole IN ed EXISTS
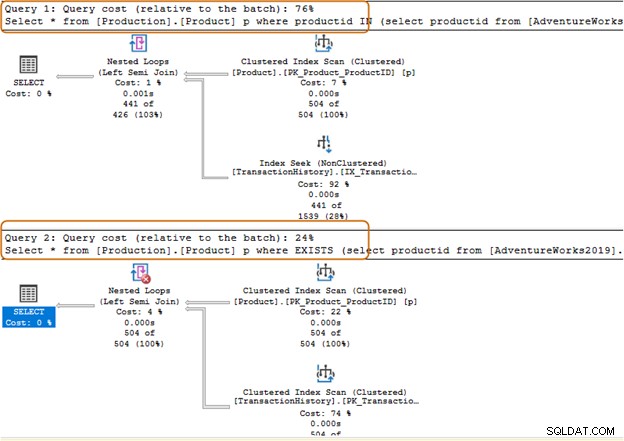
Dovresti evitare di usare la clausola IN-operatore per le tue query SQL. Ad esempio, nella query seguente, per prima cosa abbiamo trovato l'ID prodotto dalla tabella [Produzione].[Cronologia transazioni]) e quindi abbiamo cercato i record corrispondenti nella tabella [Produzione].[Prodotto].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
Nella query seguente, abbiamo sostituito la clausola IN con una clausola EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
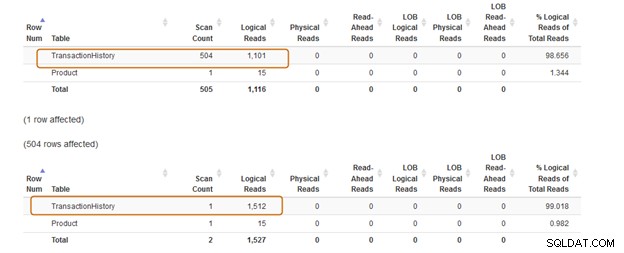
Ora confrontiamo le statistiche dopo aver eseguito entrambe le query.
La clausola IN utilizza 504 scansioni, mentre la clausola EXISTS utilizza 1 scansione per la tabella [Produzione].[TransactionHistory])].
Il batch di query della clausola IN costa il 74%, mentre il costo della clausola EXISTS è del 24%. Pertanto, dovresti evitare la clausola IN soprattutto se la sottoquery restituisce un set di dati di grandi dimensioni.
Indici mancanti
A volte, quando eseguiamo una query SQL e cerchiamo il piano di esecuzione effettivo in SSMS, ricevi un suggerimento su un indice che potrebbe migliorare la tua query SQL.
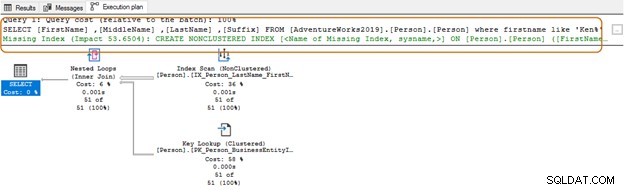
In alternativa, puoi utilizzare le viste a gestione dinamica per controllare i dettagli degli indici mancanti nel tuo ambiente.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Di solito, i DBA seguono i consigli di SSMS e creano gli indici. Potrebbe migliorare le prestazioni delle query per il momento. Tuttavia, non dovresti creare l'indice direttamente sulla base di tali consigli. Potrebbe influire sulle prestazioni di altre query e rallentare le istruzioni INSERT e UPDATE.
- In primo luogo, esamina gli indici esistenti per la tua tabella SQL.
- Nota, la sovraindicizzazione e la sottoindicizzazione sono entrambe negative per le prestazioni delle query.
- Applica i consigli sugli indici mancanti con il massimo impatto dopo aver esaminato gli indici esistenti e implementali nel tuo ambiente inferiore. Se il tuo carico di lavoro funziona bene dopo aver implementato il nuovo indice mancante, vale la pena aggiungere it.
Ti suggerisco di fare riferimento a questo articolo per le best practice dettagliate per l'indicizzazione: 11 Procedure consigliate per l'indice di SQL Server per una migliore ottimizzazione delle prestazioni.
Suggerimenti per le query
Gli sviluppatori specificano i suggerimenti per la query in modo esplicito nelle loro istruzioni t-SQL. Questi suggerimenti per la query sovrascrivono il comportamento di Query Optimizer e lo obbligano a preparare un piano di esecuzione in base al tuo suggerimento per la query. I suggerimenti per le query più utilizzati sono NOLOCK, Optimize For e Recompile Merge/Hash/Loop. Sono soluzioni a breve termine per le tue domande. Tuttavia, dovresti lavorare sull'analisi della tua query, degli indici, delle statistiche e del piano di esecuzione per una soluzione permanente.
Secondo le migliori pratiche, dovresti ridurre al minimo l'utilizzo di qualsiasi suggerimento per la query. Si desidera utilizzare i suggerimenti per la query nella query SQL dopo averne compreso le implicazioni e non utilizzarli inutilmente.
Promemoria per l'ottimizzazione delle query SQL
Come abbiamo discusso, l'ottimizzazione delle query SQL è una strada aperta. Puoi applicare best practice e piccole correzioni che possono migliorare notevolmente le prestazioni. Considera i seguenti suggerimenti per un migliore sviluppo delle query:
- Guarda sempre le allocazioni delle risorse di sistema (dischi, CPU, memoria)
- Esamina i flag di traccia di avvio, gli indici e le attività di manutenzione del database
- Analizza il tuo carico di lavoro utilizzando eventi estesi, profiler o strumenti di monitoraggio del database di terze parti
- Implementa sempre qualsiasi soluzione (anche se sei sicuro al 100%) prima nell'ambiente di test e analizzane l'impatto; una volta che sei soddisfatto, pianifica le implementazioni di produzione