Bene, per rispondere alla tua domanda sul perché SQL Server sta facendo questo, la risposta è che la query non è compilata in un ordine logico, ogni affermazione viene compilata in base al proprio merito, quindi quando viene generato il piano di query per la tua istruzione select, l'ottimizzatore non sa che @val1 e @Val2 diventeranno rispettivamente "val1" e "val2".
Quando SQL Server non conosce il valore, deve fare un'ipotesi migliore su quante volte la variabile apparirà nella tabella, il che a volte può portare a piani non ottimali. Il mio punto principale è che la stessa query con valori diversi può generare piani diversi. Immagina questo semplice esempio:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Tutto quello che ho fatto qui è creare una tabella semplice e aggiungere 1000 righe con valori da 1 a 10 per la colonna val , tuttavia 1 appare 991 volte e gli altri 9 compaiono solo una volta. La premessa è questa query:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Sarebbe più efficiente eseguire la scansione dell'intera tabella, piuttosto che utilizzare l'indice per una ricerca, quindi eseguire 991 ricerche di segnalibri per ottenere il valore per Filler , tuttavia con solo 1 riga la seguente query:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
sarà più efficiente eseguire una ricerca nell'indice e una singola ricerca del segnalibro per ottenere il valore per Filler (e l'esecuzione di queste due query confermerà questo)
Sono abbastanza certo che il taglio per una ricerca e una ricerca di segnalibri in realtà varia a seconda della situazione, ma è piuttosto basso. Usando la tabella di esempio, con un po' di tentativi ed errori, ho scoperto che avevo bisogno del Val colonna per avere 38 righe con il valore 2 prima che lo strumento di ottimizzazione eseguisse una scansione completa della tabella su una ricerca di indice e di segnalibro:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Quindi per questo esempio il limite è del 3,7% di righe corrispondenti.
Poiché la query non sa quante righe corrisponderanno quando si utilizza una variabile, deve indovinare e il modo più semplice è scoprire il numero totale di righe e dividerlo per il numero totale di valori distinti nella colonna, quindi in questo esempio il numero stimato di righe per WHERE val = @Val è 1000 / 10 =100, L'algoritmo effettivo è più complesso di questo, ma per esempio questo andrà bene. Quindi, quando esaminiamo il piano di esecuzione per:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
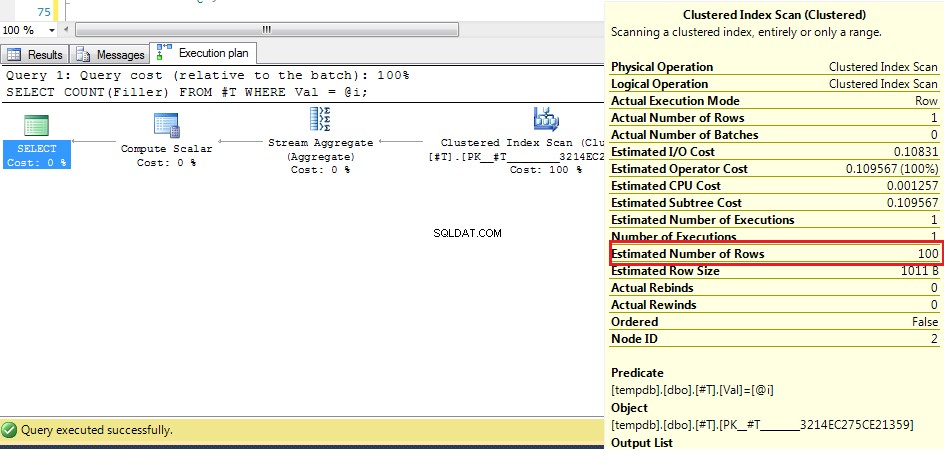
Possiamo vedere qui (con i dati originali) che il numero stimato di righe è 100, ma le righe effettive sono 1. Dai passaggi precedenti sappiamo che con più di 38 righe l'ottimizzatore opterà per una scansione dell'indice cluster su un indice cercare, quindi poiché l'ipotesi migliore per il numero di righe è maggiore di questo, il piano per una variabile sconosciuta è una scansione dell'indice cluster.
Giusto per dimostrare ulteriormente la teoria, se creiamo la tabella con 1000 righe di numeri 1-27 distribuite uniformemente (quindi il conteggio delle righe stimato sarà di circa 1000 / 27 =37.037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Quindi esegui di nuovo la query, otteniamo un piano con un indice di ricerca:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
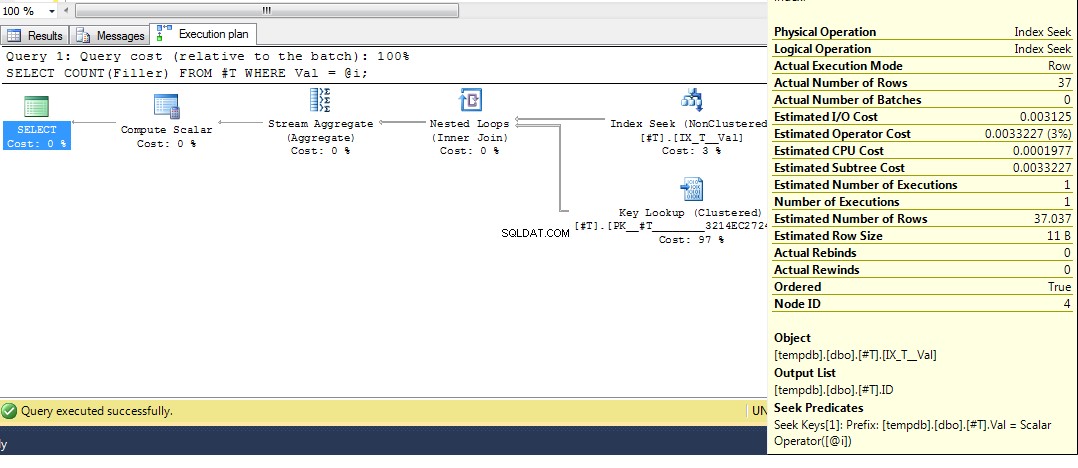
Quindi si spera che copra in modo abbastanza completo il motivo per cui ottieni quel piano. Ora suppongo che la prossima domanda sia come si forza un piano diverso e la risposta è usare il suggerimento per la query OPTION (RECOMPILE) , per forzare la compilazione della query in fase di esecuzione quando il valore del parametro è noto. Tornando ai dati originali, dove il miglior piano per Val = 2 è una ricerca, ma utilizzando una variabile si ottiene un piano con una scansione dell'indice, possiamo eseguire:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
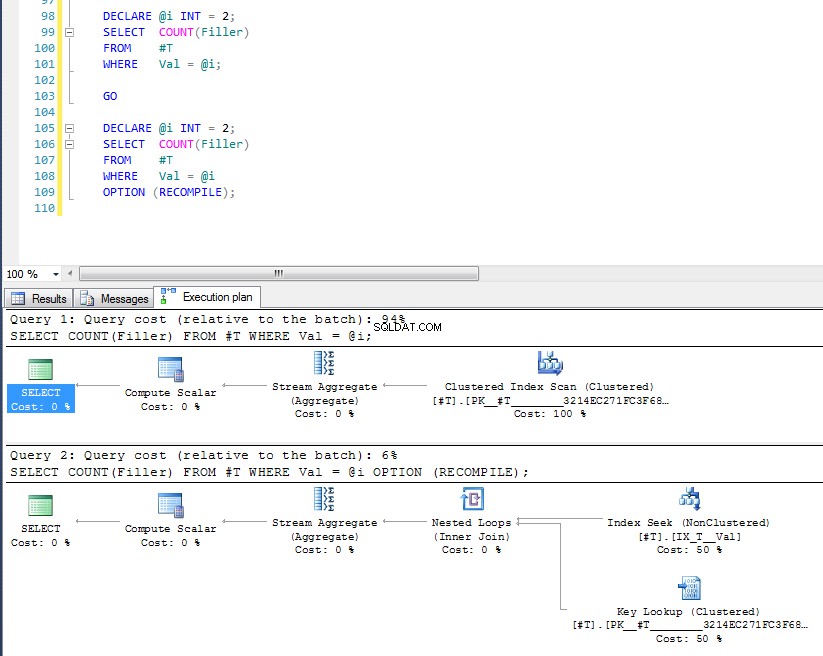
Possiamo vedere che quest'ultimo utilizza la ricerca dell'indice e la ricerca della chiave perché ha verificato il valore della variabile al momento dell'esecuzione e viene scelto il piano più appropriato per quel valore specifico. Il problema con OPTION (RECOMPILE) significa che non puoi sfruttare i piani di query memorizzati nella cache, quindi c'è un costo aggiuntivo per la compilazione della query ogni volta.