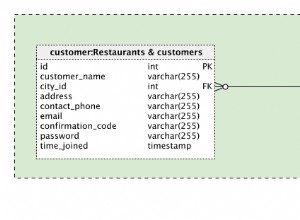
Mentre la risposta di M.Ali ti darà il risultato, dal momento che stai usando SQL Server 2012 vorrei annullare il pivot del name e address colonne leggermente diverse per ottenere il risultato finale.
Poiché stai utilizzando SQL Server 2012, puoi utilizzare CROSS APPLY con VALUES per annullare il pivot di queste colonne multiple in più righe. Ma prima di farlo, userei row_number() per ottenere il numero totale di nuove colonne che avrai.
Il codice per "UNPIVOT" i dati utilizzando CROSS APPLY è simile a:
select d.loanid,
col = c.col + cast(seq as varchar(10)),
c.value
from
(
select loanid, name, address,
row_number() over(partition by loanid
order by loanid) seq
from yourtable
) d
cross apply
(
values
('name', name),
('address', address)
) c(col, value);
Vedere SQL Fiddle con demo. Questo porterà i tuoi dati in un formato simile a:
| LOANID | COL | VALUE |
|--------|----------|----------|
| 1 | name1 | John |
| 1 | address1 | New York |
| 1 | name2 | Carl |
| 1 | address2 | New York |
| 1 | name3 | Henry |
| 1 | address3 | Boston |
Ora hai una singola colonna COL con tutti i nuovi nomi di colonna e i valori associati sono anche in un'unica colonna. I nuovi nomi delle colonne ora hanno un numero alla fine (1, 2, 3, ecc.) basato su quante voci totali hai per loanid . Ora puoi applicare PIVOT:
select loanid,
name1, address1, name2, address2,
name3, address3
from
(
select d.loanid,
col = c.col + cast(seq as varchar(10)),
c.value
from
(
select loanid, name, address,
row_number() over(partition by loanid
order by loanid) seq
from yourtable
) d
cross apply
(
values
('name', name),
('address', address)
) c(col, value)
) src
pivot
(
max(value)
for col in (name1, address1, name2, address2,
name3, address3)
) piv;
Vedere SQL Fiddle con demo. Infine se non sai quante coppie di Name e Address avrai quindi puoi usare SQL dinamico:
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)
select @cols = STUFF((SELECT ',' + QUOTENAME(col+cast(seq as varchar(10)))
from
(
select row_number() over(partition by loanid
order by loanid) seq
from yourtable
) d
cross apply
(
select 'Name', 1 union all
select 'Address', 2
) c (col, so)
group by seq, col, so
order by seq, so
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @query = 'SELECT loanid,' + @cols + '
from
(
select d.loanid,
col = c.col + cast(seq as varchar(10)),
c.value
from
(
select loanid, name, address,
row_number() over(partition by loanid
order by loanid) seq
from yourtable
) d
cross apply
(
values
(''name'', name),
(''address'', address)
) c(col, value)
) x
pivot
(
max(value)
for col in (' + @cols + ')
) p '
exec sp_executesql @query;
Vedere SQL Fiddle con demo. Entrambe le versioni danno un risultato:
| LOANID | NAME1 | ADDRESS1 | NAME2 | ADDRESS2 | NAME3 | ADDRESS3 |
|--------|--------|----------|--------|----------|--------|----------|
| 1 | John | New York | Carl | New York | Henry | Boston |
| 2 | Robert | Chicago | (null) | (null) | (null) | (null) |
| 3 | Joanne | LA | Chris | LA | (null) | (null) |