In cima alla mia testa, ho una soluzione al 50% per te.
Il problema
SSIS davvero si preoccupa dei metadati, quindi le variazioni in essi tendono a comportare eccezioni. DTS è stato molto più indulgente in questo senso. La forte necessità di metadati coerenti rende problematico l'uso del Flat File Source.
Soluzione basata su query
Se il problema è il componente, non usiamolo. Quello che mi piace di questo approccio è che concettualmente è come interrogare una tabella:l'ordine delle colonne non ha importanza né la presenza di colonne aggiuntive ha importanza.
Variabili
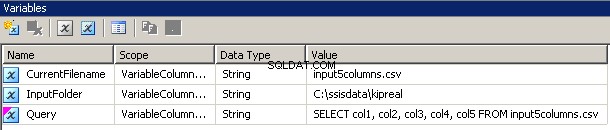
Ho creato 3 variabili, tutte di tipo string:CurrentFileName, InputFolder e Query.
- InputFolder è cablato alla cartella di origine. Nel mio esempio, è
C:\ssisdata\Kipreal - CurrentFileName è il nome di un file. Durante la fase di progettazione, era
input5columns.csvma questo cambierà in fase di esecuzione. - La query è un'espressione
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Gestione connessioni
Configurare una connessione al file di input utilizzando il driver JET OLEDB. Dopo averlo creato come descritto nell'articolo collegato, l'ho rinominato in FileOLEDB e ho impostato un'espressione su ConnectionManager di "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Controllo del flusso
Il mio flusso di controllo si presenta come un'attività del flusso di dati nidificata in un enumeratore di file Foreach
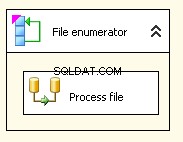
Enumeratore file Foreach
Il mio enumeratore file Foreach è configurato per operare sui file. Ho inserito un'espressione nella directory per @[User::InputFolder] Si noti che a questo punto, se il valore di quella cartella deve essere modificato, verrà aggiornato correttamente sia in Connection Manager che nell'enumeratore di file. In "Recupera il nome del file", invece dell'impostazione predefinita "Completamente qualificato", scegli "Nome ed estensione"
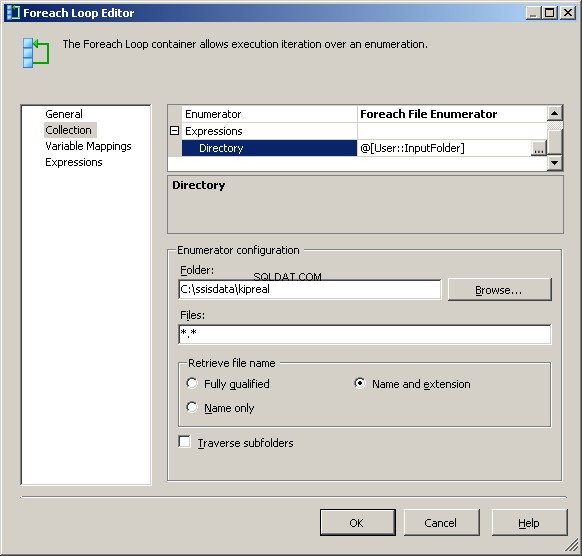
Nella scheda Mapping variabili, assegna il valore al nostro @[User::CurrentFileName] variabile
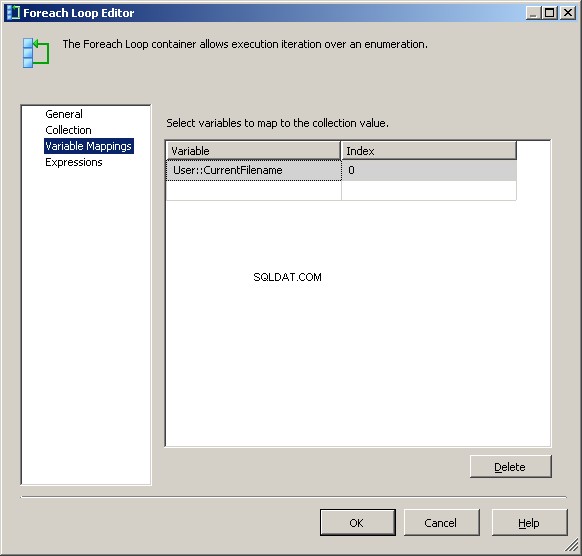
A questo punto, ogni iterazione del ciclo cambierà il valore di @[User::Query per riflettere il nome del file corrente.
Flusso di dati
Questo è in realtà il pezzo più semplice. Utilizzare una sorgente OLE DB e cablarla come indicato.
Utilizzare la gestione connessione FileOLEDB e modificare la modalità di accesso ai dati in "Comando SQL da variabile". Usa il @[User::Query] variabile lì dentro, fai clic su OK e sei pronto per lavorare. 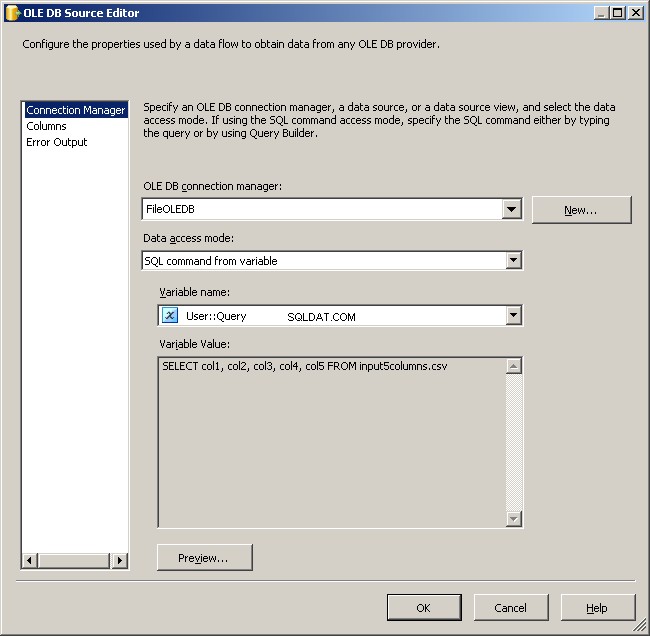
Dati di esempio
Ho creato due file di esempio input5columns.csv e input7columns.csv Tutte le colonne di 5 sono in 7 ma 7 le ha in un ordine diverso (col2 è la posizione ordinale 2 e 6). Ho negato tutti i valori in 7 per rendere immediatamente evidente su quale file si sta operando.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
e
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
L'esecuzione del pacchetto genera queste due schermate
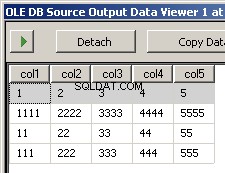
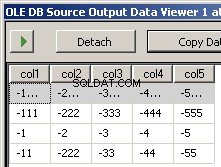
Cosa manca
Non conosco un modo per dire all'approccio basato su query che va bene se una colonna non esiste. Se c'è una chiave univoca, suppongo che tu possa definire la tua query in modo che abbia solo le colonne che devono essere lì e quindi eseguire ricerche sul file per cercare di ottenere le colonne che dovrebbero essere presente e non fallire la ricerca se la colonna non esiste. Piuttosto goffo però.