Abbiamo già trattato alcune teorie sulla configurazione dei gruppi di disponibilità Always ON per SQL Server basati su Linux. L'articolo corrente si concentrerà sulla pratica.
Presenteremo il processo dettagliato di configurazione dei gruppi di disponibilità Always ON di SQL Server tra due repliche sincrone. Inoltre, evidenzieremo l'utilizzo della replica di sola configurazione per eseguire il failover automatico.
Prima di iniziare, ti consiglio di fare riferimento all'articolo precedente e di aggiornare le tue conoscenze.
Il diagramma di progettazione seguente mostra la replica sincrona a due nodi e una replica di sola configurazione che ci aiutano a garantire il failover automatico e la protezione dei dati.
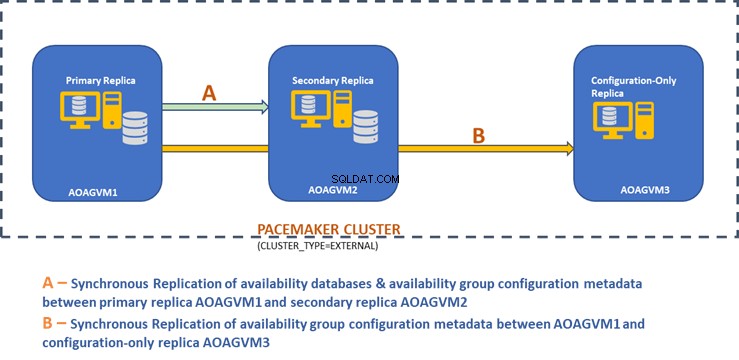
Abbiamo esplorato questo design nell'articolo menzionato in precedenza, quindi consultalo per informazioni prima di passare alle attività pratiche.
Installa SQL Server su sistemi Ubuntu
Il diagramma di progettazione sopra menziona 3 sistemi Ubuntu:aoagvm1 , aoagvm2 e aoagvm3 con le istanze di SQL Server installate. Fare riferimento alle istruzioni sull'installazione di SQL Server su Ubuntu:l'esempio si riferisce a SQL Server 2019 sul sistema Ubuntu 18.04. Puoi procedere e installare SQL Server 2019 su tutti e 3 i nodi (assicurati di installare la stessa versione build).
Per risparmiare sui costi di licenza, è possibile installare l'edizione SQL Server Express per la replica del terzo nodo. Questa funzionerà come replica di sola configurazione senza ospitare alcun database di disponibilità.
Una volta installato SQL Server su tutti e 3 i nodi, possiamo configurare il gruppo di disponibilità tra di loro.
Configura i gruppi di disponibilità tra tre nodi
Prima di procedere, convalida il tuo ambiente:
- Assicurati che ci sia comunicazione tra tutti e 3 i nodi.
- Controlla e aggiorna il nome del computer per ogni host eseguendo il comando sudo vi /etc/hostname
- Aggiorna il file host con l'indirizzo IP e i nomi dei nodi per ogni nodo. Puoi usare il comando sudo vi /etc/hosts per farlo
- Assicurati di avere tutte le istanze in esecuzione oltre SQL Server 2017 CU1 se non utilizzi SQL Server 2019
Ora, iniziamo a configurare il gruppo di disponibilità Always ON di SQL Server tra 3 nodi. Dobbiamo abilitare la funzione Gruppo di disponibilità su tutti e 3 i nodi.
Eseguire il comando seguente (si noti che è necessario riavviare il servizio SQL Server dopo tale azione):
--Enable Availability Group feature
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
--Restart SQL Server service
sudo systemctl restart mssql-server
Ho eseguito il comando sopra sul nodo primario. Dovrebbe essere ripetuto per i restanti due nodi.
L'output è di seguito:inserisci il nome utente e la password ogni volta che richiesto.
example@sqldat.com:~$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
SQL Server needs to be restarted to apply this setting. Please run
'systemctl restart mssql-server.service'.
example@sqldat.com:~$ systemctl restart mssql-server
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to restart 'mssql-server.service'.
Authenticating as: Ubuntu (aoagvm1)
Password:
Il passaggio successivo è abilitare gli eventi estesi Always ON per ogni istanza di SQL Server. Sebbene questo sia un passaggio facoltativo, è necessario abilitarlo per risolvere eventuali problemi che potrebbero verificarsi in seguito. Connettiti all'istanza di SQL Server utilizzando SQLCMD ed esegui il comando seguente:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
Go
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
Go
L'output è il seguente:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
2>GO
1>
Dopo aver abilitato questa opzione sul nodo di replica primario, fai lo stesso per i restanti nodi aoagvm2 e aoagvm3.
Le istanze di SQL Server in esecuzione su Linux usano i certificati per autenticare la comunicazione tra gli endpoint di mirroring. Quindi, l'opzione successiva consiste nel creare il certificato sulla replica primaria aoagvm1 .
Innanzitutto, creiamo una chiave master e un certificato. Quindi eseguiamo il backup di questo certificato in un file e proteggiamo il file con una chiave privata. Esegui lo script T-SQL riportato di seguito sul nodo di replica primario:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Configure Certificates
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
L'uscita:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
3>GO
1>BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
2>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
3>GO
1>
Il nodo di replica primario dispone ora di due nuovi file. Uno è il file del certificato dbm_certificate.cer e il file della chiave privata dbm_certificate.pvk in /var/opt/mssql/data/ posizione.
Copiare i due file precedenti nella stessa posizione sui restanti due nodi (AOAGVM2 e AOAGVM3) che parteciperanno alla configurazione del gruppo di disponibilità. È possibile utilizzare il comando SCP o qualsiasi utilità di terze parti per copiare questi due file sul server di destinazione.
Una volta copiati i file nei due nodi rimanenti, assegneremo le autorizzazioni a mssql utente per accedere a questi file su tutti e 3 i nodi. Per questo, esegui il comando seguente e poi eseguilo per il 3° nodo aoagvm3 anche:
--Copy files to aoagvm2 node
cd /var/opt/mssql/data
scp dbm_certificate.* example@sqldat.com:var/opt/mssql/data/
--Grant permission to user mssql to access both newly created files
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Creeremo la chiave principale e i file del certificato con l'aiuto dei due file copiati sopra sui due nodi rimanenti aoagvm2 e aoagvm3 . Esegui il comando seguente su questi due nodi per creare la chiave principale :
--Create master key and certificate on remaining two nodes
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
Ho eseguito il comando precedente sul secondo nodo aoagvm2 per creare la chiave principale e certificato . Dai un'occhiata all'output di esecuzione. Assicurati di utilizzare le stesse password utilizzate durante la creazione e il backup del certificato e della chiave master.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate
3>FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
4>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
5>GO
1>
Esegui il comando precedente su AOAGVM3 anche nodo.
Ora configuriamo gli endpoint di mirroring del database:in precedenza abbiamo creato i certificati per loro. L'endpoint di mirroring denominato hadr_endpoint dovrebbe essere su tutti e 3 i nodi in base al rispettivo tipo di ruolo.
Poiché i database di disponibilità sono ospitati solo su 2 nodi aoagvm1 e aoagvm2, eseguiremo еру sotto l'istruzione solo su quei nodi. Il terzo nodo fungerà da testimone, quindi cambieremo semplicemente il RUOLO a testimone nello script seguente, quindi esegui T-SQL sul terzo nodo aoagvm3 . Lo script è:
--Configure database mirroring endpoint Hadr_endpoint on nodes aoagvm1 and aoagvm2
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Ecco l'output del comando precedente sul nodo di replica primario. Mi sono connesso a sqlcmd e l'ha eseguito. Assicurati di fare lo stesso sul secondo nodo di replica aoagvm2 anche.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE ENDPOINT [Hadr_endpoint]
2>AS TCP (LISTENER_PORT = 5022)
3>FOR DATABASE_MIRRORING (ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
4>Go
1>ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
2>Go
1>
Dopo aver eseguito lo script T-SQL sopra sui primi 2 nodi, dobbiamo modificarlo per il terzo nodo:cambia il RUOLO in TESTIMONIANZA.
Eseguire lo script seguente per creare l'endpoint di mirroring del database sul nodo di controllo AOAGVM3 . Se si desidera ospitare lì i database di disponibilità, eseguire il comando precedente anche sul nodo di replica 3. Ma assicurati di aver installato l'edizione corretta di SQL Server per ottenere questa funzionalità.
Se hai installato l'edizione SQL Server Express sul nodo 3 per implementare solo configurazione replica , puoi solo configurare RUOLO come testimone per questo nodo:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
----Configure database mirroring endpoint Hadr_endpoint on 3rd node aoagvm3
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = WITNESS, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint on aoagvm3
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Ora dobbiamo creare il gruppo di disponibilità denominato ag1 .
Connettiti all'istanza di SQL Server utilizzando sqlcmd utility ed eseguire il comando seguente sul nodo di replica primario aoagvm1 :
--Connect to the local SQL Server instance using sqlcmd hosted on primary replica node aoagvm1
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Create availability group ag1
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'aoagvm1’ WITH (ENDPOINT_URL = N'tcp://aoagvm1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm2' WITH (ENDPOINT_URL = N'tcp://aoagvm2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm3' WITH (ENDPOINT_URL = N'tcp://aoagvm3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY);
--Assign required permission
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Lo script precedente configura le repliche del gruppo di disponibilità con i parametri di configurazione seguenti (le abbiamo appena utilizzate nello script T-SQL):
- CLUSTER_TYPE =ESTERNO perché stiamo configurando il gruppo di disponibilità su installazioni di SQL Server basate su Linux
- MODALITÀ SEEDING =AUTOMATICA fa in modo che SQL Server crei automaticamente un database su ogni replica secondaria. I database di disponibilità non verranno creati sulla replica di sola configurazione
- FAILOVER_MODE =ESTERNO sia per le repliche primarie che per quelle secondarie. significa che la replica interagisce con un gestore risorse cluster esterno, come Pacemaker
- MODALITÀ_DISPONIBILITÀ =COMMIT_SINCRONO per le repliche primarie e secondarie per il failover automatico
- MODALITÀ_DISPONIBILITÀ =SOLO CONFIGURAZIONE per la terza replica che funziona come replica di sola configurazione
È inoltre necessario creare un accesso Pacemaker su tutte le istanze di SQL Server. A questo utente deve essere assegnato il ALTER , CONTROLLO e VISUALIZZA DEFINIZIONE autorizzazioni sul gruppo di disponibilità su tutte le repliche. Per concedere le autorizzazioni, esegui immediatamente lo script T-SQL riportato di seguito su tutti e 3 i nodi di replica. Per prima cosa, creeremo un login Pacemaker. Quindi, assegneremo le autorizzazioni di cui sopra a quell'accesso.
--Create pacemaker login on each SQL Server instance. Run below commands on all 3 SQL Server instances
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
--Grant permission to pacemaker login on newly created availability group. Run it on all 3 SQL Server instances
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemaker
GRANT VIEW SERVER STATE TO pacemaker
Dopo aver assegnato le autorizzazioni appropriate al login Pacemaker su tutte e 3 le repliche, eseguiamo gli script T-SQL seguenti per unire le repliche secondarie aoagvm2 e aoagvm3 al gruppo di disponibilità appena creato ag1 . Esegui i comandi seguenti sulle repliche secondarie aoagvm2 e aoagvm3 .
--Execute below commands on aoagvm2 and aoagvm3 to join availability group ag1
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Di seguito è riportato l'output delle precedenti esecuzioni sul nodo aoagvm2 . Assicurati di eseguirlo su aoagvm3 anche nodo.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
2>Go
1>ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
2>Go
1>
Pertanto, abbiamo configurato il gruppo di disponibilità. Ora è necessario aggiungere un utente o un database di test a questo gruppo di disponibilità. Se hai già creato un database utente sulla replica del nodo primario, esegui semplicemente un backup completo e poi lascia che il seeding automatico lo ripristini sul nodo secondario.
Quindi, esegui il comando seguente:
--Run a full backup of test database or user database hosted on primary replica aoagvm1
BACKUP DATABASE [Test] TO DISK = N'/var/opt/mssql/data/Test_15June.bak';
Aggiungiamo questo database Test al gruppo di disponibilità ag1 . Eseguire l'istruzione T-SQL seguente sul nodo primario aoagvm1 . Puoi utilizzare sqlcmd utility per eseguire istruzioni T-SQL.
--Add user database or test database to the availability group ag1
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [Test];
È possibile verificare il database utente o un database di test aggiunto al gruppo di disponibilità esaminando l'istanza secondaria di SQL Server, indipendentemente dal fatto che sia stata creata su repliche secondarie o meno. Puoi utilizzare SQL Server Management Studio o eseguire una semplice istruzione T-SQL per recuperare i dettagli su questo database.
--Verify test database is created on a secondary replica or not. Run it on secondary replica aoagvm2.
SELECT * FROM sys.databases WHERE name = 'Test';
GO
Riceverai il Test database creato sulla replica secondaria.
Con il passaggio precedente, il gruppo di disponibilità AlwaysOn è stato configurato tra tutti e tre i nodi. Tuttavia, questi nodi non sono ancora raggruppati. Il prossimo passo è l'installazione di Pacemaker raggrupparsi su di essi. Quindi aggiungeremo il gruppo di disponibilità ag1 come risorsa per quel cluster.
Configurazione del cluster PACEMAKER tra tre nodi
Pertanto, utilizzeremo un gestore di risorse cluster esterno PACEMAKER tra tutti e 3 i nodi per il supporto del cluster. Iniziamo con l'abilitazione delle porte del firewall tra tutti e 3 i nodi.
Apri le porte del firewall usando il comando seguente:
--Run the below commands on all 3 nodes to open Firewall Ports
sudo ufw allow 2224/tcp
sudo ufw allow 3121/tcp
sudo ufw allow 21064/tcp
sudo ufw allow 5405/udp
sudo ufw allow 1433/tcp
sudo ufw allow 5022/tcp
sudo ufw reload
--If you don't want to open specific firewall ports then alternatively you can disable the firewall on all 3 nodes by running the below command (THIS IS ALTERNATE & OPTIONAL APPROACH)
sudo ufw disable
Guarda l'output:questo proviene dalla replica primaria AOAGVM1 . È necessario eseguire i comandi precedenti su tutti e tre i nodi, uno per uno. L'output dovrebbe essere simile.
example@sqldat.com:~$ sudo ufw allow 2224/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 3121/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 21064/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5405/udp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 1433/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5022/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw reload
Firewall not enabled (skipping reload)
Installa Pacemaker e corosync pacchetti su tutti e 3 i nodi. Esegui il comando seguente su ciascun nodo:configurerà Pacemaker , corosincrona e agente di scherma .
--Install Pacemaker packages on all 3 nodes aoagvm1, aoagvm2 and aoagvm3 by running the below command
sudo apt-get install pacemaker pcs fence-agents resource-agents
L'output è enorme - quasi 20 pagine. Ho copiato la prima e l'ultima riga per illustrarlo (puoi vedere tutti i pacchetti installati):
example@sqldat.com:~$ sudo apt-get install pacemaker pcs fence-agents resource-agents
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
cluster-glue corosync fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4 libcpg4
libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker-cli-utils pacemaker-common pacemaker-resource-agents python-pexpect python-ptyprocess python-pycurl python3-bs4 python3-html5lib
python3-lxml python3-pycurl python3-webencodings rake ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean ruby-ethon ruby-ffi ruby-highline
ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4 ruby-power-assert ruby-rack
ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt ruby-tzinfo ruby2.5
rubygems-integration sg3-utils snmp unzip xsltproc zip
Suggested packages:
ipmitool python-requests python-suds apache2 | lighttpd | httpd lm-sensors snmp-mibs-downloader python-pexpect-doc libcurl4-gnutls-dev python-pycurl-dbg
python-pycurl-doc python3-genshi python3-lxml-dbg python-lxml-doc python3-pycurl-dbg ri ruby-dev bundler
The following NEW packages will be installed:
cluster-glue corosync fence-agents fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4
libcpg4 libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker pacemaker-cli-utils pacemaker-common pacemaker-resource-agents pcs python-pexpect python-ptyprocess python-pycurl python3-bs4
python3-html5lib python3-lxml python3-pycurl python3-webencodings rake resource-agents ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean
ruby-ethon ruby-ffi ruby-highline ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4
ruby-power-assert ruby-rack ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt
ruby-tzinfo ruby2.5 rubygems-integration sg3-utils snmp unzip xsltproc zip
0 upgraded, 103 newly installed, 0 to remove and 2 not upgraded.
Need to get 19.6 MB of archives.
After this operation, 86.0 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 fonts-lato all 2.0-2 [2698 kB]
Get:2 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 libdbus-glib-1-2 amd64 0.110-2 [58.3 kB]
…………
--------
Una volta che il pacemaker l'installazione del cluster è terminata, l'hacluster l'utente verrà popolato automaticamente durante l'esecuzione del comando seguente:
example@sqldat.com:~$ cat /etc/passwd|grep hacluster
hacluster:x:111:115::/var/lib/pacemaker:/usr/sbin/nologin
Ora possiamo impostare la password per l'utente predefinito creato durante l'installazione di Pacemaker e il Corosync Pacchetti. Assicurati di utilizzare la stessa password su tutti e 3 i nodi. Usa il comando seguente:
--Set default user password on all 3 nodes
sudo passwd hacluster
Inserisci la password quando richiesto:
example@sqldat.com:~$ sudo passwd hacluster
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Il passaggio successivo è abilitare e avviare pcsd servizio e Pacemaker su tutti e 3 i nodi. Consente a tutti e 3 i nodi di unirsi al cluster dopo il riavvio. Esegui il comando seguente su tutti e 3 i nodi per completare questo passaggio:
--Enable and start pcsd service and pacemaker
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker
Guarda l'esecuzione sulla replica primaria aoagvm1 . Assicurati di eseguirlo anche sui restanti due nodi.
--Enable pcsd service
example@sqldat.com:~$ sudo systemctl enable pcsd
Synchronizing state of pcsd.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pcsd
--Start pcsd service
example@sqldat.com:~$ sudo systemctl start pcsd
--Enable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Abbiamo configurato il Pacemaker Pacchetti. Ora creiamo un cluster.
Innanzitutto, assicurati di non avere cluster precedentemente configurati su quei sistemi. Puoi distruggere qualsiasi configurazione di cluster esistente da tutti i nodi eseguendo i comandi seguenti. Tieni presente che la rimozione di qualsiasi configurazione del cluster interromperà tutti i servizi del cluster e disabiliterà il Pacemaker servizio:deve essere riattivato.
--Destroy previously configured clusters to clean the systems
sudo pcs cluster destroy
--Reenable Pacemaker
sudo systemctl enable pacemaker
Di seguito è riportato l'output dal nodo di replica primario aoagvm1 .
--Destroy previously configured clusters to clean the systems
example@sqldat.com:~$ sudo pcs cluster destroy
Shutting down pacemaker/corosync services...
Killing any remaining services...
Removing all cluster configuration files...
--Reenable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Successivamente, creiamo il cluster a 3 nodi tra tutti e 3 i nodi dalla replica primaria aoagvm1 . Importante :esegui i seguenti comandi solo dal tuo nodo principale !
--Create cluster. Modify below command with your node names, hacluster password and clustername
sudo pcs cluster auth <node1> <node2> <node3> -u hacluster -p <password for hacluster>
sudo pcs cluster setup --name <clusterName> <node1> <node2...> <node3>
sudo pcs cluster start --all
sudo pcs cluster enable --all
Vedi l'output sul nodo di replica primario:
example@sqldat.com:~$ sudo pcs cluster auth aoagvm1 aoagvm2 aoagvm3 -u hacluster -p hacluster
aoagvm1: Authorized
aoagvm2: Authorized
aoagvm3: Authorized
example@sqldat.com:~$ sudo pcs cluster setup --name aoagvmcluster aoagvm1 aoagvm2 aoagvm3
Destroying cluster on nodes: aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Stopping Cluster (pacemaker)...
aoagvm2: Stopping Cluster (pacemaker)...
aoagvm3: Stopping Cluster (pacemaker)...
aoagvm1: Successfully destroyed cluster
aoagvm2: Successfully destroyed cluster
aoagvm3: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'aoagvm1', 'aoagvm2', 'aoagvm3'
aoagvm1: successful distribution of the file 'pacemaker_remote authkey'
aoagvm2: successful distribution of the file 'pacemaker_remote authkey'
aoagvm3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
aoagvm1: Succeeded
aoagvm2: Succeeded
aoagvm3: Succeeded
Synchronizing pcsd certificates on nodes aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
Restarting pcsd on the nodes to reload the certificates...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
example@sqldat.com:~$ sudo pcs cluster start --all
aoagvm1: Starting Cluster...
aoagvm2: Starting Cluster...
aoagvm3: Starting Cluster...
example@sqldat.com:~$ sudo pcs cluster enable --all
aoagvm1: Cluster Enabled
aoagvm2: Cluster Enabled
aoagvm3: Cluster Enabled
Scherma è una delle configurazioni essenziali durante l'utilizzo del cluster PACEMAKER in produzione. Dovresti configurare il fencing per il tuo cluster per assicurarti che non ci sia alcun danneggiamento dei dati in caso di interruzioni .
Esistono due tipi di implementazione della scherma:
- A livello di risorsa – garantisce che un nodo non possa utilizzare una o più risorse.
- A livello di nodo – assicura che un nodo non esegua alcuna risorsa.
Generalmente utilizziamo STONITH come configurazione di scherma:la scherma a livello di nodo per PACEMAKER .
Quando PACEMAKER non è in grado di determinare lo stato di un nodo o di una risorsa su un nodo, il fencing riporta il cluster a uno stato noto. Per raggiungere questo obiettivo, PACEMAKER ci richiede di abilitare STONITH , che sta per Spara all'altro nodo nella testa .
Non ci concentreremo sulla configurazione di recinzione in questo articolo perché la configurazione di recinzione a livello di nodo dipende fortemente dal singolo ambiente. Per il nostro scenario, lo disabiliteremo eseguendo il comando seguente:
--Disable fencing (STONITH)
sudo pcs property set stonith-enabled=false
Tuttavia, se prevedi di utilizzare Pacemaker in un ambiente di produzione, dovresti pianificare l'implementazione di STONITH in base al tuo ambiente e mantenerlo abilitato.
Successivamente, imposteremo alcune proprietà essenziali del cluster:cluster-recheck-interval, start-failure-is-fatal, e timeout guasto .
Come per MSDN, se timeout di errore è impostato su 60 secondi e cluster-recheck-interval è impostato su 120 secondi, il riavvio viene tentato a un intervallo maggiore di 60 secondi ma inferiore a 120 secondi. Microsoft consiglia di impostare un valore per intervallo di ricontrollo del cluster maggiore del valore di timeout guasto . Un'altra impostazione start-failure-is-fatal deve essere impostato come vero . In caso contrario, il cluster non avvierà il failover della replica primaria sulla rispettiva replica secondaria, in caso di interruzioni permanenti.
Esegui i comandi seguenti per configurare tutte e 3 le proprietà importanti del cluster:
--Set cluster property cluster-recheck-interval to 2 minutes
sudo pcs property set cluster-recheck-interval=2min
--Set start-failure-is-fatal to True
sudo pcs property set start-failure-is-fatal=true
--Set failure-timeout to 60 seconds. Ag1 is the name of the availability group. Change this name with your availability group name.
pcs resource update ag1 meta failure-timeout=60s
Integra il gruppo di disponibilità al gruppo del cluster di pacemaker
Qui, il nostro obiettivo è descrivere il processo di integrazione del gruppo di disponibilità appena creato ag1 al nuovo Pacemaker gruppo di cluster.
Innanzitutto, installeremo l'agente di risorse di SQL Server per l'integrazione con Pacemaker su tutti e 3 i nodi:
--Install SQL Server Resource Agent on all 3 nodes
sudo apt-get install mssql-server-ha
Ho eseguito il comando sopra su tutti e 3 i nodi. Guarda l'output di seguito (tratto da aoagvm1 ):
--Install SQL Server resource agent for integration with Pacemaker
example@sqldat.com:~$ sudo apt-get install mssql-server-ha
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
mssql-server-ha
0 upgraded, 1 newly installed, 0 to remove, and 2 not upgraded.
Need to get 1486 kB of archives.
After this operation, 9151 kB of additional disk space will be used.
Get:1 https://packages.microsoft.com/ubuntu/16.04/mssql-server-preview xenial/main amd64 mssql-server-ha amd64 15.0.1600.8-1 [1486 kB]
Fetched 1486 kB in 0s (4187 kB/s)
Selecting previously unselected package mssql-server-ha.
(Reading database ... 90430 files and directories currently installed.)
Preparing to unpack .../mssql-server-ha_15.0.1600.8-1_amd64.deb ...
Unpacking mssql-server-ha (15.0.1600.8-1) ...
Setting up mssql-server-ha (15.0.1600.8-1) ...
Ripetere i passaggi precedenti sui restanti 2 nodi.
Abbiamo già creato il Pacemaker accedere a tutte le istanze di SQL Server ospitate su 3 nodi dopo aver configurato il gruppo di disponibilità ag1 . Ora assegniamo il ruolo di amministratore di sistema a tutte e 3 le istanze di SQL Server. Puoi connetterti usando sqlcmd for running this T-SQL command. If you have not created the Pacemaker login, you can run the below command to do it.
--Create a pacemaker login if you missed creating it in the above section.
USE master
Go
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
Go
--Assign sysadmin role to pacemaker login on all 3 nodes. Run this T-SQL on all 3 SQL Server instances.
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemaker]
We must save the above SQL Server Pacemaker login and its credentials on all 3 nodes. Run the below command there:
--Save pacemaker login credentials on all 3 nodes by executing below commands on each node
echo 'pacemaker' >> ~/pacemaker-passwd
echo 'example@sqldat.com@12' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd
We will create the Availability Group Resource as master/subordinate .
We are using the pcs resource create command to create the Availability Group resource and set its properties. The following command will create the ocf:mssql:ag resource for the Availability Group ag1 .
The Pacemaker resource agent automatically sets the value of REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT on the Availability Group based on the Availability Group’s configuration during the creation of the Availability Group resource.
Execute the below command:
--Create availability group resource ocf:mssql:ag
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s --master meta notify=true
Next, we create a virtual IP resource in Pacemaker . Ensure you have the unused private IP address from your network . Replace the IP value with your virtual IP address. This IP will point to the primary replica and you can use it to make databases connections with active nodes.
The command is below:
--Configure virtual IP resource
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=10.50.0.7
We are adding the colocation constraint and ordering constraint to the Pacemaker cluster configuration . These constraints help the virtual IP resource to make decisions on resources, e.g., where they should run.
Constraints have some scores, and Pacemaker uses these scores to make decisions. Scores are calculated per resource. The cluster resource manager chooses the node with the highest score for a particular resource.
The colocation constraint has an implicit ordering constraint . We need to add an ordering constraint to prevent the IP address from temporarily pointing to the node with the pre-failover secondary . Ordering constraint ensures the cluster comes online in a particular sequential manner.
Run the below commands to add colocation constraint and ordering constraint to the cluster.
--Add colocation constraint
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
--Add ordering constraint
sudo pcs constraint order promote ag_cluster-master then start virtualip
Hence, Two-Node Synchronous Replicas (aoagvm1 &aoagvm2) and a Configuration-Only Replica (aoagvm3) on PACEMAKER Cluster between 3-Node Ubuntu Systems has been completed.
We can test the configuration to validate the automatic failover. Run the below command to check the status of the Pacemaker cluster. The command also initiates the Availability Group failover.
Remember, once you couple your Availability Group with the PACEMAKER cluster, you cannot use T-SQL statements to initiate the Availability Group failovers. You can also shut down the primary replica to initiate the automatic failover.
The command is the following:
--Validate the PACEMAKER cluster configuration
sudo pcs status
--Initiate availability group failover to verify AOAG configuration
sudo pcs resource move ag_cluster-master aoagvm2 –master
Conclusione
This article was meant to help you understand the configuration of the Two-Node Synchronous Replicas and a Configuration-Only Replica on PACEMAKER Cluster. We hope that you got useful information that will help you in your workflow.
Always plan all steps carefully and do proper testing in a lower life cycle before deploying to your production environment.
We’ll be glad to hear your thoughts about this topic. Feel free to leave your feedback in a comment section.



