In Postgres , width_bucket()
è proprio quello che stai cercando:granulare un numero qualsiasi di righe (N ) nella tabella sottostante in un dato (preferibilmente più piccolo ) numero di punti dati (n ). Puoi aggiungere il conteggio delle righe che contribuiscono a ciascun punto dati per indicare il peso.
Un piccolo ostacolo:la variante di width_bucket() abbiamo bisogno di operare su double precision o numeric numeri, non su timestamp et al. Basta estrarre l'epoca con cui lavorare.
Assumendo questa definizione di tabella e una versione corrente di Postgres:
CREATE TABLE tbl (
tbl_id serial PRIMARY KEY
, value numeric NOT NULL
, created_at timestamptz NOT NULL
);
Query:
SELECT width_bucket(extract(epoch FROM t.created_at), x.min_epoch, x.max_epoch, 400) AS pix
, round(avg(t.value), 2) AS avg -- round is optional
, count(*) AS weight
FROM big t
CROSS JOIN (SELECT extract(epoch FROM min(created_at)) AS min_epoch
, extract(epoch FROM max(created_at)) AS max_epoch FROM big) x
GROUP BY 1
ORDER BY 1;
Risultato:
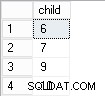
pix | avg | weight
----+--------+------
1 | 152.58 | 7
2 | 155.16 | 8
3 | 148.89 | 7
...
Restituisce 400 righe - a meno che N <n , nel qual caso ottieni N righe.
Correlati:
- Medie multiple su intervalli equidistanti
- Aggregazione (x, y) coordinare le nuvole di punti in PostgreSQL