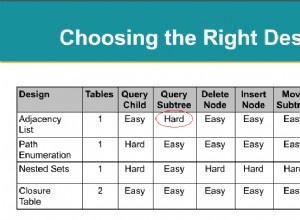
Qualche consiglio in più sulla tua funzione di trigger:
CREATE OR REPLACE FUNCTION delete_question()
RETURNS trigger AS
$func$
BEGIN
CASE OLD.que_type
WHEN 1 THEN
DELETE FROM mcq WHERE que_id=OLD.id;
WHEN 2, 3 THEN
DELETE FROM tffb WHERE que_id=OLD.id;
WHEN 4 THEN
DELETE FROM essay WHERE que_id=OLD.id;
-- ELSE
-- Do something?
END CASE;
RETURN OLD;
END
$func$ LANGUAGE plpgsql;
Punti principali
-
Il tuo assegno di esistenza con un
SELECTdichiarazione raddoppia il costo. Basta eseguireDELETE, se non viene trovata alcuna riga corrispondente, non viene eliminato nulla. -
Usa un
CASEdichiarazione qui. Più corto, più veloce. Nota che plpgsqlCASEè leggermente diverso da SQLCASEdichiarazione. Ad esempio, puoi elencare più casi contemporaneamente. -
Non è necessario il
DECLAREparola chiave, a meno che tu non dichiari effettivamente variabili.
Design alternativo
Potresti evitare del tutto il problema eliminazioni a cascata tramite chiave esterna , come @a_horse menzionato nel commento . Il layout del mio schema sarebbe simile a questo:
CREATE TABLE question (
question_id serial NOT NULL PRIMARY KEY
,que_type int -- this may be redundant as well
);
CREATE TABLE essay (
que_id int NOT NULL PRIMARY KEY
REFERNECES question(question_id) ON UPDATE CASCADE
ON DELETE CASCADE
,ans text
);
...
Informazioni su serial :
Funzione SQL di incremento automatico