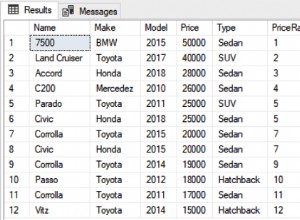
Non sono sicuro del motivo per cui la risposta sopra non ha funzionato per me, ma ho pensato di poter anche condividere ciò che effettivamente ha funzionato per me durante l'esecuzione di pyspark da un notebook jupyter (Spark 2.3.1 - Python 3.6.3):
from pyspark.sql import SparkSession
spark = SparkSession.builder.config('spark.driver.extraClassPath', '/path/to/postgresql.jar').getOrCreate()
url = 'jdbc:postgresql://host/dbname'
properties = {'user': 'username', 'password': 'pwd'}
df = spark.read.jdbc(url=url, table='tablename', properties=properties)