Vedo due problemi principali:
1. Non puoi inserire un UPDATE in una sottoquery per niente . Potresti risolverlo con una modifica dei dati CTE
come Patrick dimostra
, ma è più costoso e dettagliato del necessario per il caso in questione.
2. Hai un conflitto di denominazione potenzialmente pericoloso , che non è stato ancora risolto.
Migliore query/funzione
Lasciando da parte per il momento il wrapper della funzione SQL (ci torneremo). Puoi usare un semplice UPDATE con un RETURNING clausola:
UPDATE tbl
SET value1 = 'something_new'
WHERE id = 123
RETURNING row_to_json(ROW(value1, value2));
Il RETURNING La clausola consente espressioni arbitrarie che coinvolgono colonne della riga aggiornata. È più breve ed economico di un CTE che modifica i dati.
Il problema rimanente:il costruttore di riga ROW(...) non conserva i nomi delle colonne (che è un punto debole noto), quindi ottieni chiavi generiche nel tuo valore JSON:
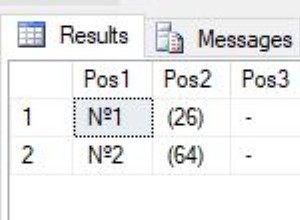
row_to_json
{"f1":"something_new","f2":"what ever is in value2"}
In Postgres 9.3 avresti bisogno di un'altra funzione CTE per incapsulare il primo passaggio o un cast su un tipo di riga ben definito. Dettagli:
In Postgres 9.4 basta usare json_build_object() o json_object()
:
UPDATE tbl
SET value1 = 'something_new'
WHERE id = 123
RETURNING json_build_object('value1', value1, 'value2', value2);Oppure:
...
RETURNING json_object('{value1, value2}', ARRAY[value1, value2]);Ora ottieni i nomi delle colonne originali o qualunque cosa tu abbia scelto come nomi delle chiavi:
row_to_json
{"value1":"something_new","value2":"what ever is in value2"}
È facile racchiuderlo in una funzione, che ci porta al tuo secondo problema ...
Conflitto di denominazione
Nella tua funzione originale usi nomi identici per parametri di funzione e nomi di colonna. Questa è generalmente una pessima idea . Dovresti capire intimamente quale identificatore viene prima in quale ambito.
Nel caso in questione il risultato è una sciocchezza assoluta:
Create Or Replace Function ExampleTable_Update (id bigint, value1 text) Returns
...
Update ExampleTable
Set Value1 = value1
Where id = id
Returning Value1, Value2;
...
$$ Language SQL;
Mentre sembri aspettarti che la seconda istanza di id farebbe riferimento al parametro della funzione, non lo fa. Il nome della colonna viene prima nell'ambito di un'istruzione SQL, la seconda istanza fa riferimento alla colonna. risultando in un'espressione che è sempre true ad eccezione dei valori NULL in id . Di conseguenza, aggiorneresti tutte le righe , che potrebbe portare a una perdita catastrofica di dati . Quel che è peggio, potresti non rendertene conto se non più tardi, perché la funzione SQL ne restituirà uno riga arbitraria come definita da RETURNING clausola della funzione (restituisce uno riga, non un insieme di righe).
In questo caso particolare, saresti "fortunato", perché hai anche value1 = value1 , che sovrascrive la colonna con il suo valore preesistente, di fatto non facendo .. nulla in modo molto costoso (a meno che i trigger non facciano qualcosa). Potresti essere perplesso nell'ottenere una riga arbitraria con un value1 invariato come risultato.
Quindi, non farlo.
Evita potenziali conflitti di denominazione come questo a meno che tu non sappia esattamente cosa stai facendo (che ovviamente non è il caso). Una convenzione che mi piace è quella di anteporre un carattere di sottolineatura per i nomi dei parametri e delle variabili nelle funzioni, mentre i nomi delle colonne non iniziano mai con un carattere di sottolineatura. In molti casi puoi semplicemente usare i riferimenti posizionali per non avere ambiguità:$1 , $2 , ..., ma questo elude solo una metà del problema. Qualsiasi metodo è valido purché eviti conflitti di denominazione . Suggerisco:
CREATE OR REPLACE FUNCTION foo (_id bigint, _value1 text)
RETURNS json AS
$func$
UPDATE tbl
SET value1 = _value1
WHERE id = _id
RETURNING json_build_object('value1', value1, 'value2', value2);
$func$ LANGUAGE sql;
Tieni inoltre presente che restituisce il valore effettivo della colonna in value1 dopo il UPDATE , che può corrispondere o meno al parametro di input _value1 . Potrebbero esserci regole del database o trigger che interferiscono...